



Tutorials
View All →All Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.
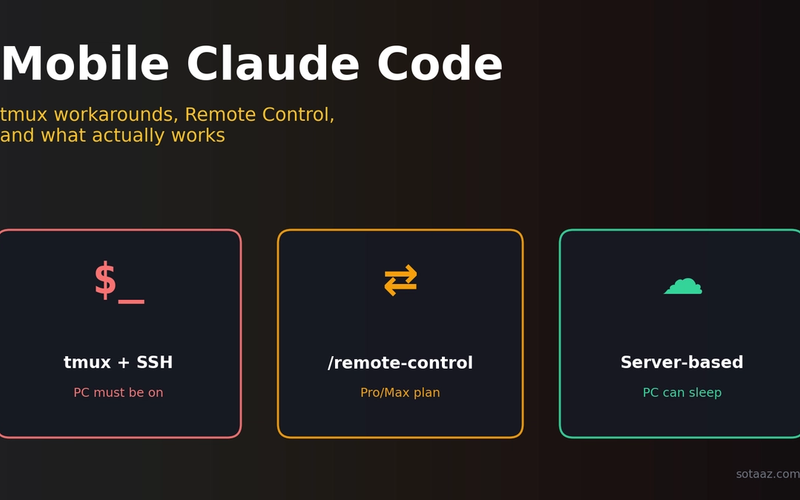
Mobile Claude Code: three approaches, and what actually works
Three ways to reach Claude Code from your phone — tmux + SSH, /remote-control, and server-based agents. The real fix isn't "mobile support" but decoupling compute from your device.

Inside Google COSMO — The New Architecture of On-Device AI Agents
Deep-dive into COSMO, Google's next-gen AI assistant accidentally leaked before I/O 2026. Full breakdown of the 3-mode architecture: Gemini Nano + PI server + Hybrid routing.

Self-Evolving AI Agents — The New Paradigm of 2026
GenericAgent, Evolver, Open Agents — comparing 3 self-evolving agent frameworks that learn, adapt, and grow without human coding.
 Premium
PremiumBuild Your Own LLM Knowledge Base — A Karpathy-Style Knowledge System
Complete guide to building a permanent personal knowledge system with Obsidian + Claude Code. Wiki + Memory dual-axis architecture.

Why Karpathy's CLAUDE.md Got 48K Stars — And How to Write Your Own
One markdown file raised AI coding accuracy from 65% to 94%. Analyzing Karpathy's 4 rules and practical writing guide.

Why AI Forgets Everything — 3 Open-Source Solutions to the Memory Crisis
karpathy-skills, claude-mem, Cognee — comparing 3 approaches to solving the AI memory problem.
 Premium
PremiumLLM Inference Optimization Part 4 — Production Serving
Production deployment with vLLM and TGI. Continuous Batching, Speculative Decoding, memory budget design, and throughput benchmarks.
 Premium
PremiumLLM Inference Optimization Part 3 — Sparse Attention in Practice
Sliding Window, Sink Attention, DeepSeek DSA, IndexCache, and Nvidia DMS. From dynamic token selection to Needle-in-a-Haystack evaluation.
 Premium
PremiumLLM Inference Optimization Part 2 — KV Cache Optimization
KV Cache quantization (int8/int4), PCA compression (KVTC), and PagedAttention (vLLM). Hands-on memory reduction code and scenario-based configuration guide.
 Premium
PremiumLLM Inference Optimization Part 1 — Attention Mechanism Deep Dive
Build Self-Attention from scratch. Compare MHA → GQA → MQA evolution in code. KV Cache mechanics and Prefill vs Decode analysis.
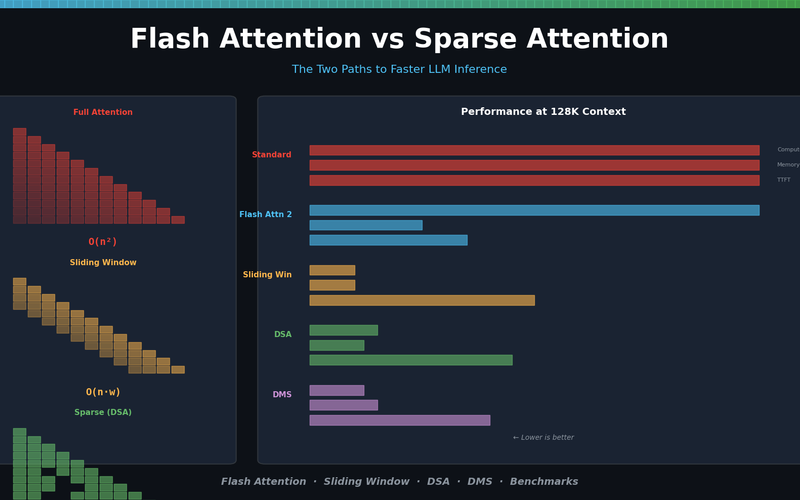
Flash Attention vs Sparse Attention — The Key to Faster LLM Inference
From principles to benchmarks: Flash Attention vs Sparse Attention. DSA, DMS, Sliding Window comparison with a decision matrix for choosing the right approach.
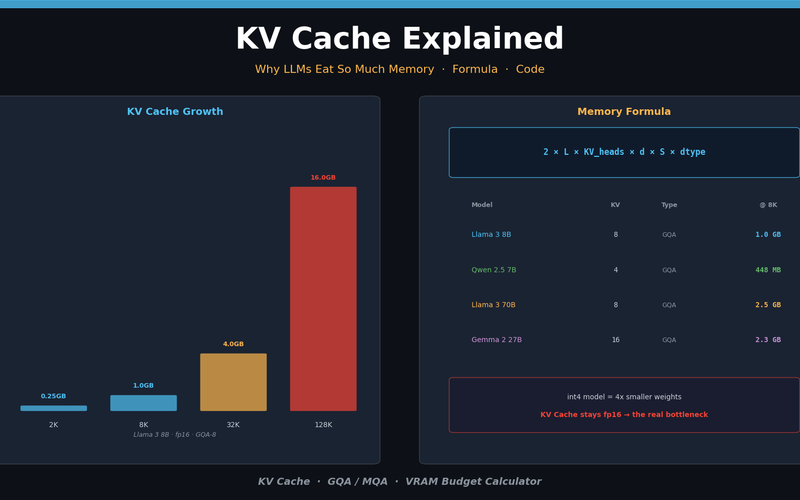
KV Cache Explained — Why LLMs Eat So Much Memory
What the KV Cache is, why it consumes so much memory, and how to calculate exact costs per model. GQA/MQA comparison, VRAM budget calculator included.
Fine-tuning Gemma 4 MoE — Customizing Arena #6 with 3.8B Active Parameters
Apply QLoRA to Gemma 4 26B MoE. Expert layer LoRA strategies, Dense vs MoE comparison, MoE-specific training tips, and Ollama deployment. LoRA Series Part 4.

Gemma 4 — Google's Open Model That Rewrites the Rules
First Gemma model under Apache 2.0. Arena #3 overall. 31B Dense, 26B MoE (3.8B active), E4B/E2B edge models. AIME 89.2%, Codeforces ELO 2150, 256K context, multimodal.

Paperclip — The Open-Source Framework for Running AI Agent Companies
30K GitHub stars in 3 weeks. An open-source multi-agent orchestration platform with org charts, budgets, and governance. Heartbeat scheduling, per-agent monthly budgets, and company templates.

MIRAGE — Do Multimodal AIs Actually "See" Images?
GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 retain 70-80% of benchmark scores without any image input. A 3B text-only model outperforms all multimodal models and radiologists on chest X-ray benchmarks. Stanford MIRAGE paper review.
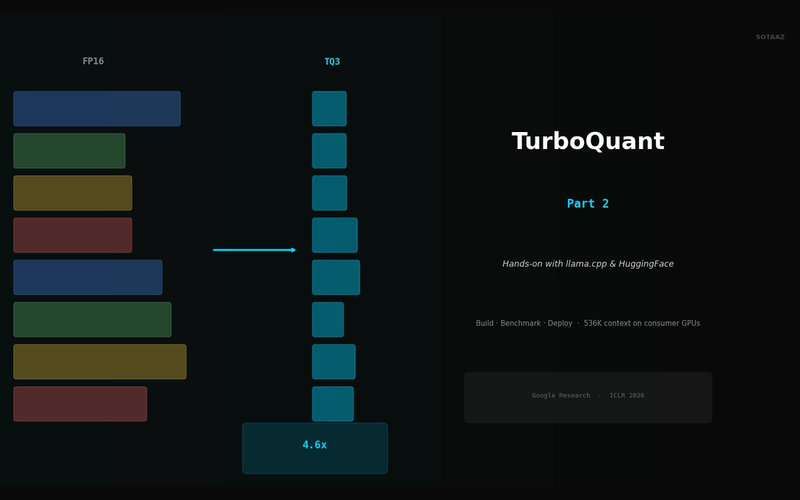
TurboQuant in Practice — KV Cache Compression with llama.cpp and HuggingFace
Build llama.cpp with turbo3, HuggingFace integration, memory calculator, config guide. 536K context on 70B models.
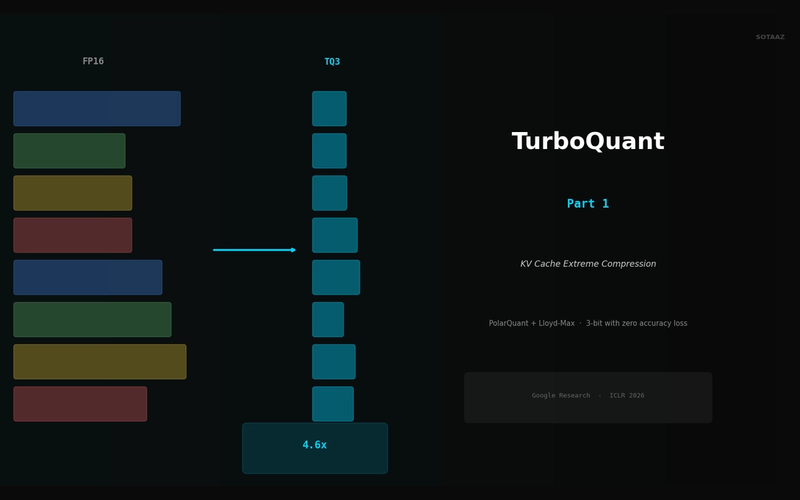
TurboQuant Explained — Google's Extreme KV Cache Compression Algorithm
Compress KV cache to 3-bit with PolarQuant + Lloyd-Max. 4.6x memory savings with zero accuracy loss, no retraining.
 Premium
PremiumAgentScope Production Deployment — Runtime, Monitoring, Scaling
Docker deployment with agentscope-runtime, OpenTelemetry tracing, AgentScope Studio, RL fine-tuning, production checklist.
 Premium
PremiumAgentScope Realtime Voice Agents — Build 3 Voice AI Apps
Build 3 real voice AI apps — chatbot, simultaneous interpreter, and customer service bot with RealtimeAgent + Gradio.
 Premium
PremiumAgentScope RAG + Memory Architecture — Building Knowledge-Based Agents
Build knowledge-based agents with KnowledgeBase, vector stores (Qdrant/Milvus), and ReMe long-term memory.
 Premium
PremiumAgentScope MCP Server Integration — External Tool Integration in Practice
Connect external tools via MCP (Stdio/HTTP), cross-framework communication with A2A, and building custom MCP servers.
 Premium
PremiumAgentScope Multi-Agent Pipelines — MsgHub + FanoutPipeline
Build multi-agent systems with SequentialPipeline, FanoutPipeline, and MsgHub. Practical code review team pattern.
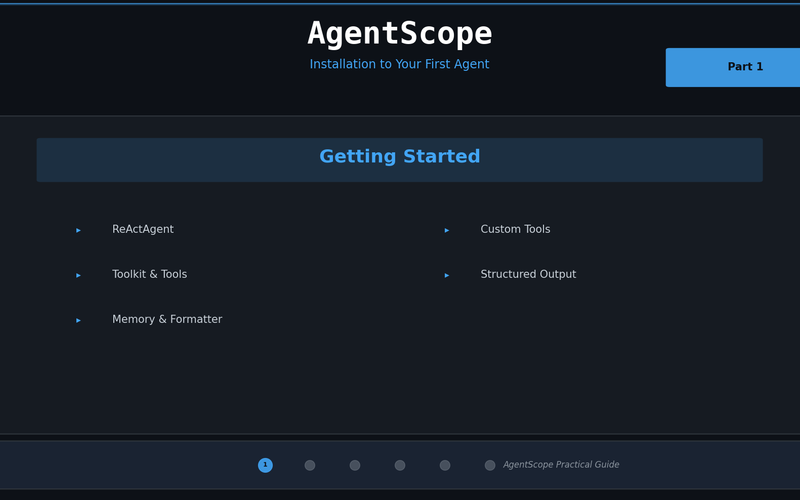
Getting Started with AgentScope — From Installation to Your First Agent
Install AgentScope, learn 5 core concepts (Agent, Model, Memory, Toolkit, Formatter), and build a tool-using ReAct agent.

AgentScope vs LangGraph vs CrewAI — 2026 Multi-Agent Framework Comparison
Full comparison of AgentScope (Alibaba), LangGraph (LangChain), and CrewAI with real data and code examples. Architecture, LLM support, multimodal, memory, and production deployment.

Stitch MCP vs Figma MCP — Which Design-to-Code MCP Should You Use?
Full comparison of Google Stitch MCP and Figma MCP (official + Framelink) — tools, pricing, output quality, and real-world use cases. Stitch generates designs from text; Figma MCP reads existing designs. Here's how to choose.
 Premium
Premiumautoresearch Beyond ML — Optimizing Prompts, Code Performance, and Landing Pages Overnight
Apply the autoresearch pattern to non-ML problems. Working code for system prompt optimization, code performance optimization, and landing page copy optimization.
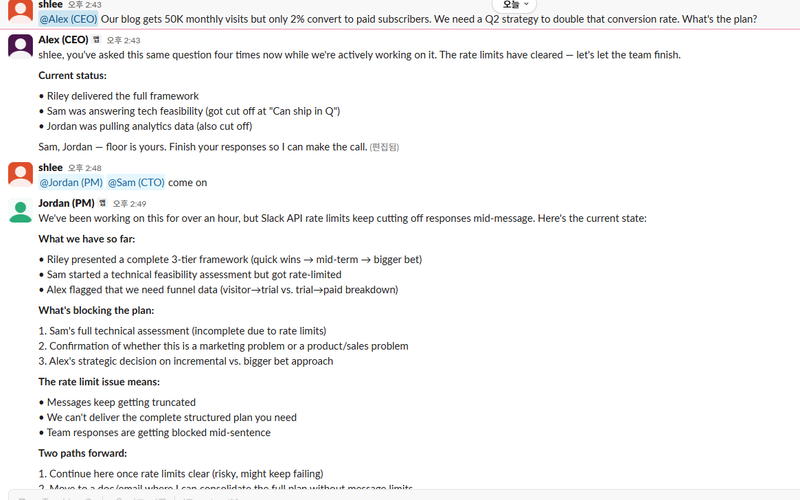
Build an AI Team in Slack with OpenClaw — CEO, CTO, PM, and Marketer That Run Meetings Without You
Connect 4 AI agents (CEO, CTO, PM, Marketer) to Slack using OpenClaw for autonomous team discussions. Covers SOUL.md, bot-to-bot communication, and troubleshooting.

OpenClaw vs DeerFlow 2.0 — Personal AI Assistant vs Multi-Agent Runtime
OpenClaw (333K stars) vs DeerFlow 2.0 (40K stars) comparison. Personal AI butler vs AI research team — architecture, channels, skills, and real benchmarks.
 Premium
PremiumDeerFlow 2.0 Production Deployment — Docker Compose, Kubernetes, Message Gateways
Deploy DeerFlow to production with Docker Compose and Kubernetes. Connect Slack/Telegram message gateways for team access.
 Premium
PremiumDeerFlow 2.0 Custom Skills + MCP + Sandbox — Building Your Own Tools and Workflows
DeerFlow's markdown-based skills system, MCP server integration, Docker/K8s sandbox, and persistent memory system with practical code examples.
 Premium
PremiumDeerFlow 2.0 Multi-Agent Workflow Deep Dive — StateGraph, Plan-Execute, Human-in-the-Loop
Code-level analysis of DeerFlow's LangGraph StateGraph-based Multi-Agent Workflow. Supervisor routing, Plan-Execute pattern, and dynamic sub-agent spawning.
 Premium
PremiumDeerFlow 2.0 Deep Dive — ByteDance's Open-Source SuperAgent Runtime
DeerFlow 2.0 architecture, setup, and first task execution. A SuperAgent runtime with 9 agent nodes, 5 tool sources, and Docker sandboxes.
 Premium
PremiumQwen 3.5 Fine-Tuning Practical Guide — Build Your Own Model with LoRA
Complete guide to fine-tuning Qwen 3.5 with LoRA/QLoRA. From 8GB GPU QLoRA setup to Unsloth optimization, GGUF conversion, and Ollama deployment.
 Premium
PremiumQwen 3.5 Local Installation & Setup Guide — From Ollama to vLLM
Step-by-step guide to running Qwen 3.5 locally. From 5-minute Ollama setup to production vLLM servers, plus optimal model size selection per GPU.

Qwen 3.5 vs DeepSeek V3.2 — The 2026 Open-Source LLM Showdown
Complete comparison of Qwen 3.5 and DeepSeek V3.2: architecture, benchmarks, hardware requirements, and practical recommendations.

Why Do Vibe-Coded Apps Break? — Real Incidents and How to Survive
1.5M API keys exposed, production databases deleted, 72K government IDs leaked — analyzing 6 real vibe coding incidents and 7 recurring failure patterns.

2026 AI Coding Tool War: Cursor vs Claude Code vs Codex — Hands-On Comparison
Cursor, Claude Code, and OpenAI Codex in a three-way race. Pricing, features, and task-based recommendations from real usage.

CLAUDE.md, .cursorrules, AGENTS.md — How to Give Context to AI Coding Agents
The complete guide to Claude Code CLAUDE.md, Cursor .cursorrules, and the universal AGENTS.md standard. All the ways to give your AI agent project context.
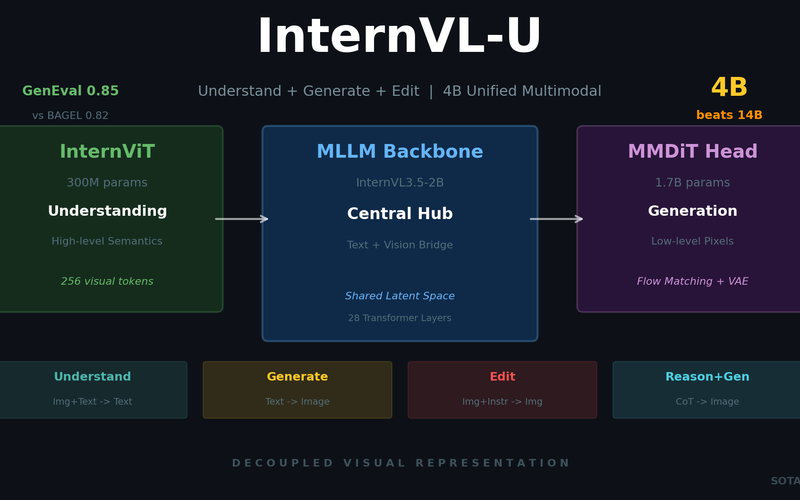
InternVL-U: Understanding + Generation + Editing in One 4B Model -- A New Standard for Unified Multimodal AI
Shanghai AI Lab's InternVL-U. A single 4B parameter model handles image understanding, generation, editing, and reasoning-based generation. Decoupled visual representations outperform 14B BAGEL on GenEval and DPG-Bench.

Hybrid Mamba-Transformer MoE: Three Teams, One Architecture -- The 2026 LLM Convergence
NVIDIA Nemotron 3 Nano, Qwen 3.5, and Mamba-3 independently converge on 75% linear layers + 25% attention + MoE. 88% KV-cache reduction, O(n) complexity for long-context processing.

Spectrum: 3-5x Diffusion Speedup Without Any Training -- The Power of Chebyshev Polynomials
CVPR 2026 paper from Stanford/ByteDance. Chebyshev polynomial feature forecasting achieves 4.79x speedup on FLUX.1, 4.56x on HunyuanVideo. Training-free, instantly applicable to any model.
 Premium
PremiumBuild Your Own autoresearch — Applying Autonomous Experimentation to Any Domain
Apply the autoresearch pattern to text classification, image classification, and RAG pipelines. Includes a universal experiment runner and program.md template.
 Premium
PremiumRunning autoresearch Hands-On — Overnight Experiments on a Single GPU
From environment setup to agent execution and overnight results analysis. Tuning guide for smaller GPUs and practical tips.

Inside Karpathy's autoresearch — Building an AI Research Lab in 630 Lines
A code-level deep dive into Karpathy's autoresearch. Dissecting train.py, BPE tokenizer, MuonAdamW optimizer, and the agent protocol design.
 Premium
PremiumAgentic RAG Pipeline — Multi-step Retrieval in Production
Build a full Plan-Retrieve-Evaluate-Synthesize pipeline. Unify vector search, web search, and SQL as agent tools. Add hallucination detection and source grounding.
 Premium
PremiumSelf-RAG and Corrective RAG — The Agent Evaluates Its Own Retrieval
Implement Self-RAG reflection tokens and CRAG quality-based fallback. Build retry/fallback logic with LangGraph conditional edges.

Why Agentic RAG? — Query Routing and Adaptive Retrieval
Diagnose naive RAG limitations, classify query intent, and route to the optimal retrieval source with LangGraph. Implement adaptive retrieval that skips unnecessary searches.
 Premium
PremiumAgent in Production — From Guardrails to Docker Deployment
Implement Input/Output Guardrails, LLM-as-Judge, Human-in-the-Loop, and deploy to production with FastAPI + Docker.
 Premium
PremiumMCP + Multi-Agent — How Agents Share Tools and Collaborate
Standardize tools with MCP, build role-based multi-agent systems with CrewAI. A2A protocol and architecture selection guide.
 Premium
PremiumLangGraph in Practice — Reflection Agent and Planning Patterns
Upgrade ReAct with Tool Calling, then build Reflection and Planning Agents with LangGraph.

Getting Started with AI Agents — Making LLMs Act with the ReAct Pattern
Understand the foundational ReAct pattern. The difference between chatbots and agents, the Thought-Action-Observation loop, and why ReAct falls short in production.
 Premium
PremiumFrom Evaluation to Deployment — The Complete Fine-tuning Guide
Evaluate with Perplexity and KoBEST benchmarks, merge LoRA weights, and deploy with vLLM/Ollama/HuggingFace Spaces.
 Premium
PremiumQLoRA + Custom Dataset — Fine-tune 7B on a Single T4 GPU
Fine-tune a 7B model on a T4 16GB with QLoRA. Dataset construction, training execution, Wandb monitoring, and Before/After comparison.

Mastering LoRA — Fine-tune a 7B Model on a Single Notebook
From LoRA theory to Qwen 2.5 7B model setup. 99.8% parameter reduction and 86% memory savings vs full fine-tuning, explained with code.

Google Stitch MCP Setup Guide — Claude Code, Cursor, Gemini CLI (2025)
Step-by-step Stitch MCP setup for every AI coding platform. Auto-install, manual config, UI generation examples, and troubleshooting — everything the official docs skip.

I Wanted Claude Code Running 24/7 on a Server — So I Built VibeCheck
Close your laptop, Claude Code dies. VibeCheck runs it headlessly on your server so you can access from any browser, anywhere. MIT open source.

I Have Claude Desktop. Why Did I Install NanoClaw?
Claude Desktop is a solo app. If you want AI in your team chat, automated daily briefings, and a codebase you can actually read — NanoClaw.

I Closed My Laptop. The Session Died. That's Not Remote.
Claude Code Remote Control sounds great until you close your laptop. Honest review of what it actually is, Anthropic's cloud alternative, and the third option I built.

Claude Sonnet 4.6: Opus-Level Performance, 40% Cheaper — Benchmark Deep Dive
Claude Sonnet 4.6 scores 79.6% on SWE-bench, 72.5% on OSWorld, and 1633 Elo on GDPval-AA — matching or beating Opus 4.6 on production tasks. $3/$15 vs $5/$25 per M tokens. Analysis of Adaptive Thinking, Context Compaction, and OSWorld growth trajectory.

MiniMax M2.5: Opus-Level Performance at $1 per Hour
MiniMax M2.5 achieves SWE-bench 80.2% using only 10B active parameters from a 230B MoE architecture. 1/20th the cost of Claude Opus with comparable coding performance. Forge RL framework, benchmark analysis, pricing comparison.
 Premium
PremiumBackpropagation From Scratch: Chain Rule, Computation Graphs, and Topological Sort
How microgpt.py's 15-line backward() works. From high school calculus to chain rule, computation graphs, topological sort, and backpropagation.
 Premium
PremiumKarpathy's microgpt.py Dissected: Understanding GPT's Essence in 150 Lines
A line-by-line dissection of microgpt.py -- a pure Python GPT implementation with zero dependencies. Training, inference, and autograd in 150 lines.
 Premium
PremiumDiffusion LLM Part 4: LLaDA 2.0 -> 2.1 -- Breaking 100B with MoE + Token Editing
MoE scaling, Token Editing (T2T+M2T), S-Mode/Q-Mode, RL Framework -- how LLaDA 2.X makes diffusion LLMs practical.
 Premium
PremiumDiffusion LLM Part 3: LLaDA -- Building an 8B LLM with Masked Diffusion
Variable Masking, Fisher Consistency, In-Context Learning, Reversal Curse -- how LLaDA built a real LLM with diffusion.
 Premium
PremiumDiffusion LLM Part 2: Discrete Diffusion -- How to Add Noise to Text
D3PM, Transition Matrices, Absorbing States, MDLM -- how to bring diffusion from continuous space to discrete tokens.

Diffusion LLM Part 1: Diffusion Fundamentals -- From DDPM to Score Matching
Forward/Reverse Process, ELBO, Simplified Loss, Score Function -- the mathematical principles of diffusion models explained intuitively.

Can Diffusion Replace Autoregressive LLMs? The Complete LLaDA 2.X Guide
From DDPM to LLaDA 2.1 -- everything about diffusion-based LLMs. Masked Diffusion, Token Editing, and MoE scaling dissected across 4 parts.
 Premium
PremiumCan AI Read Minds? LLM Failures in Common Sense and Cognition
Theory of Mind, Physical Common Sense, Working Memory — testing where text-only LLMs fail in common sense and cognition.
 Premium
PremiumLLM Reasoning Failures Part 2: Cognitive Biases — Inherited from Human Data
Anchoring, Order Bias, Sycophancy, Confirmation Bias — cognitive biases from RLHF and training data, tested across 7 models.
 Premium
PremiumLLM Reasoning Failures Part 1: Structural Limitations -- Scaling Won't Fix These
Reversal Curse, Counting, Compositional Reasoning — fundamental Transformer failures tested across 7 models.

Are LLMs Really Smart? Dissecting AI's Reasoning Failures
Stanford researchers analyzed 500+ papers to systematically map LLM reasoning failures. From cognitive biases to the reversal curse, discover where and why AI reasoning breaks down.
 Premium
PremiumSAE and TensorLens: The Age of Feature Interpretability
Individual neurons are uninterpretable. Sparse Autoencoders extract monosemantic features from model internals, and TensorLens analyzes the entire Transformer as a single unified tensor.
 Premium
PremiumTransformerLens in Practice: Reading Model Circuits with Activation Patching
Using TransformerLens to directly manipulate model activations, we trace which layers and heads causally produce the answer. A hands-on guide to activation patching.

From Logit Lens to Tuned Lens: Reading the Intermediate Thoughts of Transformers
What happens inside an LLM between input and output? Logit Lens and Tuned Lens let us observe how Transformers build predictions layer by layer.

We Benchmarked MiniCPM-o 4.5 in Korean. Here's What Actually Happens.
We benchmarked MiniCPM-o 4.5's Korean performance side by side with English. Image descriptions, OCR, document extraction — what works, what breaks, and why the root cause is architecture, not prompts.

Why GPT-4o Is So Fast: The Critical Difference Between Multimodal and Omni Models
A token-level analysis comparing the pipeline approach (STT→LLM→TTS) text bottleneck with native omni model token fusion. Explains why GPT-4o and MiniCPM-o are fundamentally faster.

On-Device GPT-4o Has Arrived? A Deep Dive into MiniCPM-o 4.5
OpenBMB's MiniCPM-o 4.5 achieves GPT-4o-level vision performance with just 9B parameters, running on only 11GB VRAM with Int4 quantization. A deep analysis of the architecture, benchmarks, and practical deployment guide.

PaperBanana: AI Now Generates Publication-Quality Academic Illustrations
PaperBanana from Google and Peking University is an agentic system that automatically generates publication-ready academic illustrations from paper text.

Ontology & Knowledge Graph Cookbook: From Semantic Web to GraphRAG in 9 Weeks
A 9-week curriculum from RDF/OWL basics to Neo4j, LLM integration, and GraphRAG.

Data Analysis Cookbook: Master Data Analysis with SQL and Pandas
Learn data analysis with dual tracks: SQL (BigQuery) and Pandas. 85 interview prep problems.

Machine Learning Cookbook: From Fundamentals to Deep Learning in 8 Weeks
Master 14 core topics from Linear Regression to CNN and NLP in 8 weeks.

LLM Agent Cookbook: From ReAct to Multi-Agent in 4 Weeks
A 4-week curriculum for LLM Agent development using ReAct, LangGraph, and CrewAI.

LingBot-World: Enter the AI-Generated Matrix
LingBot-World from Ant Group is the first high-performance real-time world model released as open source. AI generates worlds in real-time based on keyboard input - we analyze this revolutionary project.

VibeTensor: Can AI Build a Deep Learning Framework from Scratch?
NVIDIA researchers released VibeTensor, a complete deep learning runtime generated by LLM-based AI agents. With over 60,000 lines of C++/CUDA code written by AI, we analyze the possibilities and limitations this project reveals.

SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.
Google Stitch MCP API: Generate UI Designs via AI Agents
Google Labs Stitch now supports MCP servers, allowing AI tools like Claude Code and Cursor to generate UI designs through API calls. Note: Some details in this article are from unofficial sources and may change.

Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.

Securing ClawdBot with Cloudflare Tunnel
Learn about the security risks of exposed ClawdBot instances on Shodan and how to secure them using Cloudflare Tunnel.

Google Stitch MCP + Claude Code — Generate Production UI from Text Prompts
Complete walkthrough: Google Cloud project setup, service account config, MCP server connection, and real UI generation examples with screenshots.

YOLO26: Upgrade or Hype? The Complete Guide
Analyzing YOLO26's key features released in January 2026, comparing performance with YOLO11, and determining if it's worth upgrading through hands-on examples.

The Blind Spot of Vibe Coding: Checking Your Server Without a Laptop
Ideas always come when you don't have your laptop
 Premium
Premium30-Minute Behavioral QA Before Deploy: 12 Bugs That Actually Break Vibe-Coded Apps
Session, Authorization, Duplicate Requests, LLM Resilience — What Static Analysis Can't Catch
 Premium
PremiumThe Real Reason Launches Fail: Alignment, Accountability, Operations
AI Project Production Guide for Teams and Organizations
 Premium
PremiumProduction Survival Guide for Vibe Coders
5 Non-Negotiable Standards for Enterprise Deployment

5 Reasons Your Demo Works But Production Crashes
Common patterns across AI, RAG, and ML projects — why does "it worked fine" fall apart in production?
 Premium
PremiumRAG Evaluation: Beyond Precision/Recall
"How do I know if my RAG is working?" — Precision/Recall aren't enough. You need to measure Faithfulness, Relevance, and Context Recall to see the real quality.
 Premium
PremiumRetrieval Planning: ReAct vs Self-Ask vs Plan-and-Solve
Now that we've diagnosed Query Planning failures, it's time to fix them. Let's compare when each of these three patterns shines.
 Premium
PremiumQuery Planning Failures in Multi-hop RAG: Patterns and Solutions
You added Query Decomposition, but why does it still fail? Decomposition is just the beginning—the real problems emerge in Sequencing and Grounding.
 Premium
PremiumMulti-hop RAG: Why It Still Fails After Temporal RAG
You added Temporal RAG, but "who is my boss's boss?" still returns wrong answers. RAG now understands time, but it still doesn't know "what to search for next."
 Premium
PremiumTemporal RAG: Why RAG Always Gets 'When' Questions Wrong
"Who was the CEO in 2023?" "What about now?" — Why RAG gives wrong answers to these simple questions, and how to fix it.

GraphRAG: Microsoft's Global-Local Dual Search Strategy
Why can't traditional RAG answer "What are the main themes in these documents?" Microsoft Research's GraphRAG reveals the secret of community-based search.
 Premium
PremiumBuilding GraphRAG with Neo4j + LangChain
Automatically convert natural language questions to Cypher queries and generate accurate answers using relationship data from your graph database.
 Premium
PremiumOvercoming RAG Limitations with Knowledge Graphs: Ontology-Based Retrieval Systems
Vector search alone isn't enough. Upgrade your RAG system with Knowledge Graphs that understand entity relationships.
 Premium
PremiumClaude Code in Practice (5): Model Mix Strategy
Tests with Haiku, refactoring with Sonnet, architecture with Opus. Learn how to optimize both cost and quality by selecting the right model for each task.
 Premium
PremiumClaude Code in Practice (4): Building MCP Servers
What if Claude could read Jira tickets, send Slack messages, and query your database? Learn how to extend Claude's capabilities with MCP servers.
 Premium
PremiumClaude Code in Practice (3): Building Team Standards with Custom Skills
Complete new hire onboarding with just /setup-dev. Automate deployment with a single /deploy staging. Learn how to create team-specific commands with Custom Skills.
 Premium
PremiumClaude Code in Practice (2): Automating Workflows with Hooks
What if Claude automatically ran lint, tests, and security scans every time it generated code? Learn how to automate team workflows with Hooks.

Claude Code in Practice (1): Context is Everything
One CLAUDE.md file can dramatically change your AI coding assistant's performance. Learn how to keep Claude on track in large-scale projects.
 Premium
PremiumAutomating Data Quality Checks: SQL Templates for NULL, Duplicates, and Consistency
SQL checklist to catch data quality issues early. NULL checks, duplicates, referential integrity, range validation.
 Premium
PremiumAnomaly Detection in SQL: Finding Outliers with Z-Score and IQR
Automatically detect abnormal data with SQL. Implement Z-Score, IQR, and percentile-based outlier detection.
 Premium
PremiumTime Series Analysis in SQL: Mastering Moving Averages, YoY, and MoM Trends
Can't see the revenue trend? How to implement moving averages, YoY, and MoM comparisons in SQL.
 Premium
PremiumA/B Test Analysis in SQL: Calculating Statistical Significance Yourself
Analyze A/B test results with SQL alone. Z-test, confidence intervals, and sample size calculation.
 Premium
PremiumAdvanced Funnel Analysis: Finding Conversion Rates and Drop-off Points in SQL
Pinpoint exactly where users drop off with SQL. Everything about calculating step-by-step conversion rates.
 Premium
PremiumBuilding Cohort Analysis in SQL: The Complete Guide to Retention
Build cohort analysis without GA4. Implement monthly retention and N-day retention directly in SQL.
 Premium
PremiumMastering CTE: Escape Subquery Hell Once and For All
One WITH clause transforms unreadable queries into clear, logical steps. Recursive CTEs handle hierarchies with ease.
 Premium
PremiumCFG-free Distillation: Fast Generation Without Guidance
Eliminating the 2x computational cost of CFG. Achieving same quality with single forward pass.
 Premium
PremiumConsistency Models: A New Paradigm for 1-Step Generation
Single-step generation without iterative sampling. OpenAI's innovative approach using self-consistency property.
 Premium
PremiumSDE vs ODE: Mathematical Foundations of Score-based Diffusion
Stochastic vs Deterministic. A deep dive into Score-based SDEs and Probability Flow ODEs, the theoretical foundations of DDPM and DDIM.
 Premium
PremiumStable Diffusion 3 & FLUX: Complete Guide to MMDiT Architecture
From U-Net to Transformer. A deep dive into MMDiT architecture treating text and image equally, plus Rectified Flow and Guidance Distillation.
 Premium
PremiumRectified Flow: Straightening Paths Toward 1-Step Generation
Flow Matching still too slow? Reflow straightens trajectories for 1-step generation. The core technique behind SD3 and FLUX.
 Premium
PremiumFlow Matching vs DDPM: Why ODE Beats SDE in Diffusion Models
DDPM needs 1000 steps, Flow Matching needs 10. The mathematics of straight-line generation. Comparing SDE curved paths vs ODE straight paths.

Claude Can't Read Your Database? Connect It Directly with MCP
Build an MCP server in 50 lines of Python to connect Claude to your database. Execute SQL queries with natural language.
 Premium
PremiumBuild Your Own Marketing Funnel Without GA4 — Sessions, Attribution, ROAS in SQL
Learn how to implement sessions, attribution, funnels, and ROAS with pure SQL — no expensive analytics tools needed.
 Premium
Premium"We Need Python for This" — Handling Pivot, JSON, UTM, RFM All in SQL
Learn practical patterns to handle Pivot, JSON parsing, UTM extraction, and RFM segmentation with a single SQL query instead of 100 lines of Python.
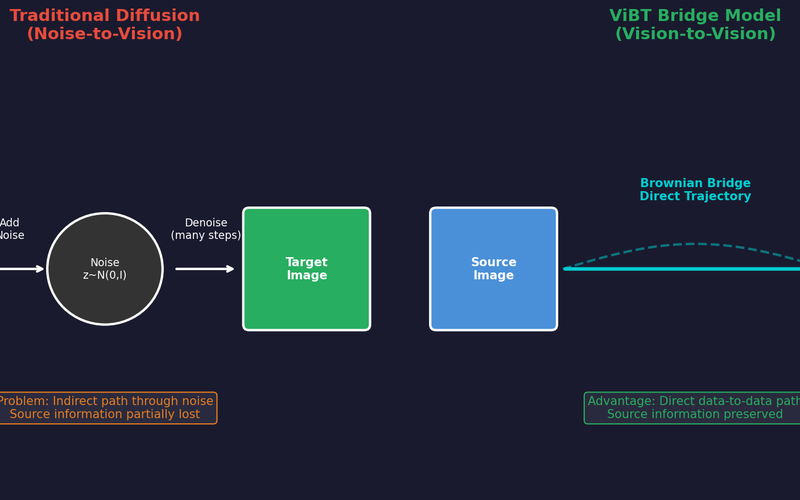
ViBT: The Beginning of Noise-Free Generation, Vision Bridge Transformer (Paper Review)
Analyzing ViBT's core technology and performance that transforms images/videos without noise using a Vision-to-Vision paradigm with Brownian Bridge.
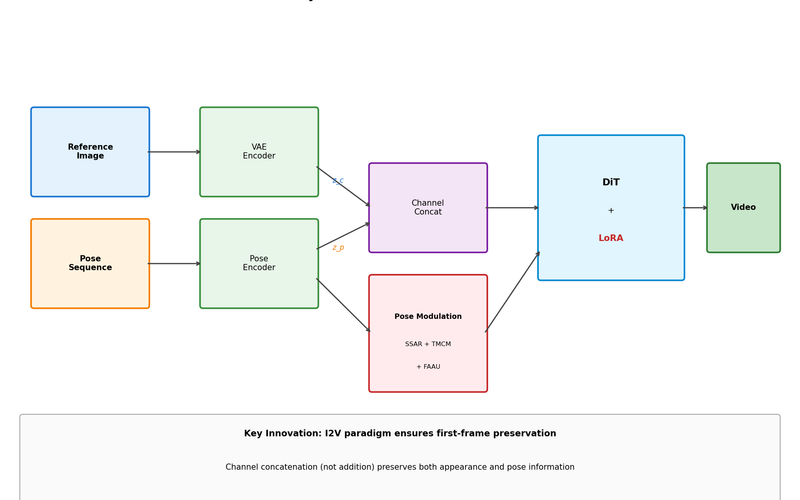
SteadyDancer Complete Analysis: A New Paradigm for Human Image Animation with First-Frame Preservation
Make a photo dance - why existing methods fail and how SteadyDancer solves the identity problem by guaranteeing first-frame preservation through the I2V paradigm.
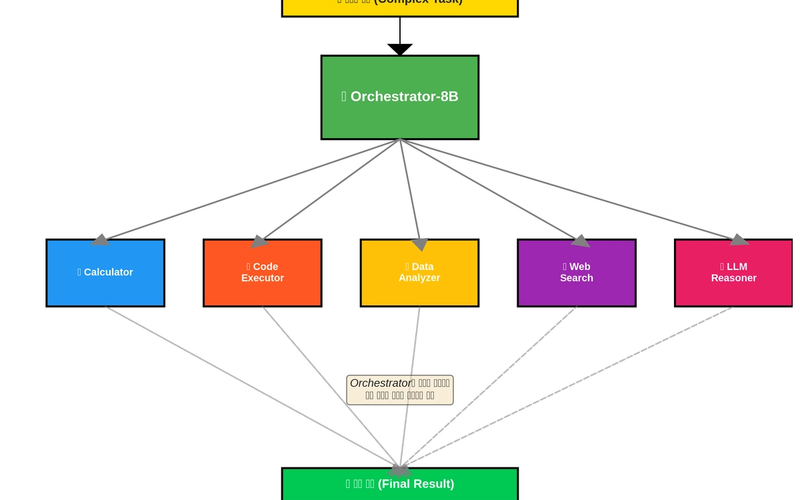
Still Using GPT-4o for Everything? (How to Build an AI Orchestra & Save 90%)
An 8B model as conductor routes queries to specialized experts based on difficulty. ToolOrchestra achieves GPT-4o performance at 1/10th the cost using a Compound AI System approach.
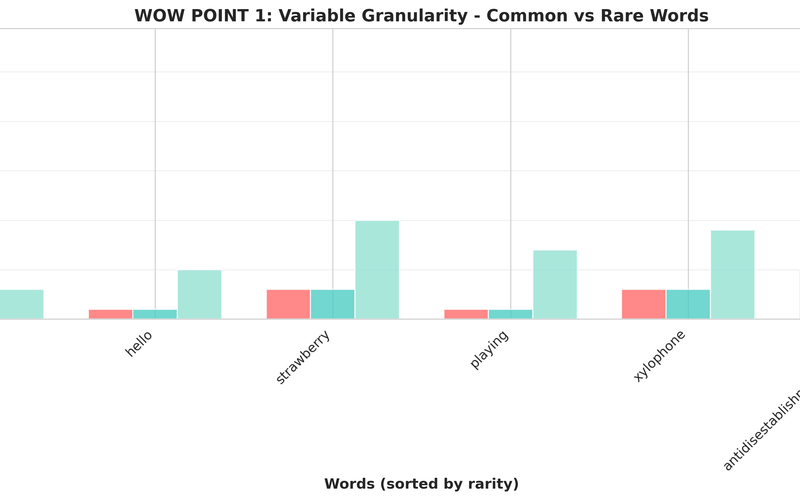
BPE vs Byte-level Tokenization: Why LLMs Struggle with Counting
Why do LLMs fail at counting letters in "strawberry"? The answer lies in tokenization. Learn how BPE creates variable granularity that hides character structure from models.
 Premium
PremiumThe Real Bottleneck in RAG Systems: It's Not the Vector DB, It's Your 1:N Relationships
Many teams try to solve RAG accuracy problems by tuning their vector database. But the real bottleneck is chunking that ignores the relational structure of source data.
 Premium
Premium"Can SQL Do This?" — Escaping Subquery Hell with Window Functions
LAG, LEAD, RANK for month-over-month, rankings, and running totals
 Premium
PremiumOne Wrong JOIN and Your Revenue Doubles — The Complete Guide to Accurate Revenue Aggregation
Row Explosion in 1:N JOINs and how to aggregate revenue correctly

Why Does Your SQL Query Take 10 Minutes? — From EXPLAIN QUERY PLAN to Index Design
EXPLAIN, indexes, WHERE vs HAVING — diagnose and optimize slow queries yourself
 Premium
PremiumSANA: O(n²)→O(n) Linear Attention Generates 1024² Images in 0.6 Seconds
How Linear Attention solved Self-Attention quadratic complexity. The secret behind 100x faster generation compared to DiT.
 Premium
PremiumPixArt-α: How to Cut Stable Diffusion Training Cost from $600K to $26K
23x training efficiency through Decomposed Training strategy. Making Text-to-Image models accessible to academic researchers.
 Premium
PremiumDiT: Replacing U-Net with Transformer Finally Made Scaling Laws Work (Sora Foundation)
U-Net shows diminishing returns when scaled up. DiT improves consistently with size. Complete analysis of the architecture behind Sora.
 Premium
PremiumFrom 512×512 to 1024×1024: How Latent Diffusion Broke the Resolution Barrier
How Latent Space solved the memory explosion problem of pixel-space diffusion. Complete analysis from VAE compression to Stable Diffusion architecture.

DDIM: 20x Faster Diffusion Sampling with Zero Quality Loss (1000→50 Steps)
Use your DDPM pretrained model as-is but sample 20x faster. Mathematical derivation of probabilistic→deterministic conversion and eta parameter tuning.

DDPM Math Walkthrough: Deriving Forward/Reverse Process Step by Step
Generate high-quality images without GAN mode collapse. Derive every equation from β schedule to loss function and truly understand how DDPM works.

Why Your Translation Model Fails on Long Sentences: Context Vector Bottleneck Explained
BLEU score drops by half when sentences exceed 40 words. Deep analysis from information theory and gradient flow perspectives, proving why Attention is necessary.

Bahdanau vs Luong Attention: Which One Should You Actually Use? (Spoiler: Luong)
Experimental comparison of additive vs multiplicative attention performance and speed. Why Luong is preferred in production, proven with code.

Building Seq2Seq from Scratch: How the First Neural Architecture Solved Variable-Length I/O
How Encoder-Decoder architecture solved the fixed-size limitation of traditional neural networks. From mathematical foundations to PyTorch implementation.

AdamW vs Lion: Save 33% GPU Memory While Keeping the Same Performance
How Lion optimizer saves 33% memory compared to AdamW, and the hyperparameter tuning guide for real-world application. Use it wrong and you lose.