QLoRA + Custom Dataset — Fine-tune 7B on a Single T4 GPU
Fine-tune a 7B model on a T4 16GB with QLoRA. Dataset construction, training execution, Wandb monitoring, and Before/After comparison.
QLoRA + Custom Dataset — Fine-tune 7B on a Single T4 GPU
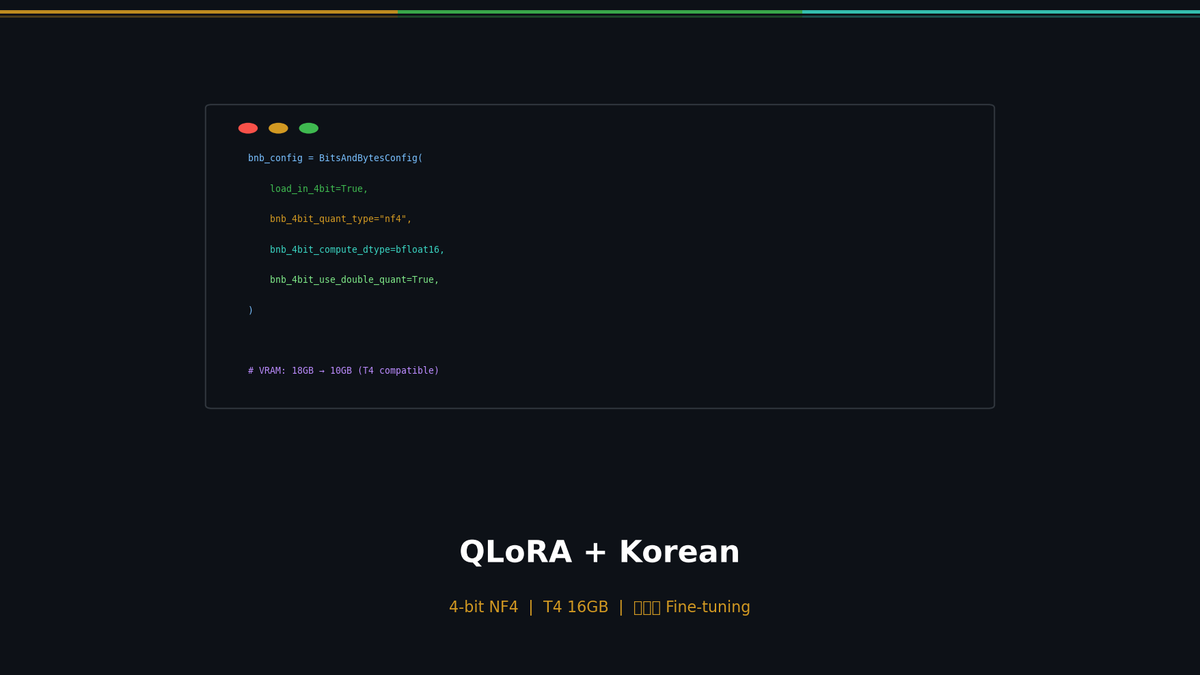
In Part 1, we covered the theory behind LoRA and fine-tuned Qwen 2.5 7B. That required about 18GB of VRAM on an RTX 3090 (24GB). In this post, we use QLoRA to bring that down to a single T4 with 16GB, and build a Korean-language dataset to meaningfully improve the model's Korean response quality.
Series: Part 1: LoRA Theory | Part 2 (this post) | Part 3: Eval + Deploy
QLoRA: Breaking Through the Memory Barrier
If LoRA reduced trainable parameters by 99.8%, QLoRA goes further and reduces the memory footprint of the model itself.
Related Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.

Self-Evolving AI Agents — The New Paradigm of 2026
GenericAgent, Evolver, Open Agents — comparing 3 self-evolving agent frameworks that learn, adapt, and grow without human coding.

Build Your Own LLM Knowledge Base — A Karpathy-Style Knowledge System
Complete guide to building a permanent personal knowledge system with Obsidian + Claude Code. Wiki + Memory dual-axis architecture.