QLoRA + 한국어 — T4 한 장으로 7B 모델을 한국어 전문가로 만들기
QLoRA로 T4 16GB에서 7B 모델을 파인튜닝합니다. 한국어 데이터셋 구축, 학습 실행, Wandb 모니터링, Before/After 비교까지.
QLoRA + 한국어 — T4 한 장으로 7B 모델을 한국어 전문가로 만들기
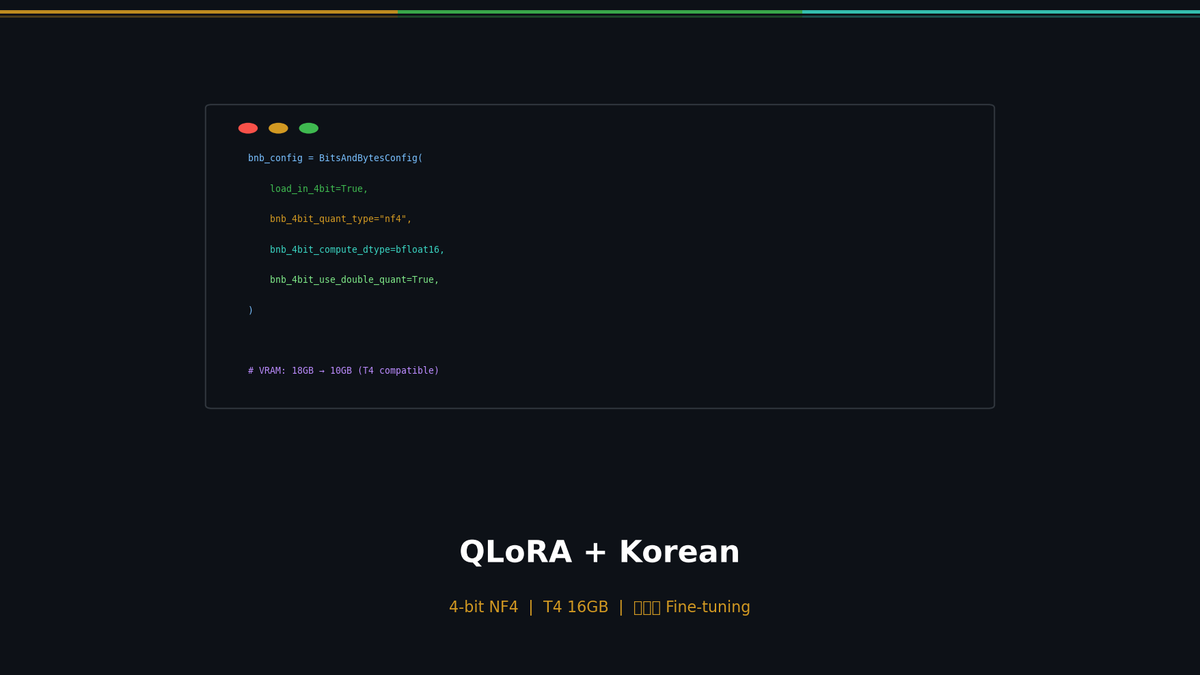
Part 1에서 LoRA의 원리와 Qwen 2.5 7B 파인튜닝을 다뤘습니다. RTX 3090(24GB)에서 약 18GB VRAM이 필요했습니다. 이번 글에서는 QLoRA로 T4 16GB 한 장까지 줄이고, 한국어 데이터셋을 구축해서 실제로 한국어 응답 품질을 끌어올립니다.
시리즈: Part 1: LoRA 이론 | Part 2 (이 글) | Part 3: 평가 + 배포
QLoRA: 메모리의 한계를 뚫다
LoRA가 학습 파라미터를 99.8% 줄였다면, QLoRA는 모델 자체의 메모리까지 줄입니다.
관련 포스트

AI 연구
Reversal Curse를 깨는 Identity Bridge — ICML 2026, 이래도 되는데 되는 fix
언어 모델은 "Alice의 남편은 Bob"을 학습해도 "Bob의 아내는?"을 못 맞힙니다 — 유명한 reversal curse. ICML 2026 논문 하나가 학습 데이터에 이상한 자기참조 예제를 섞는 것만으로 이 문제를 해결합니다. 순진한 버전은 안 되고, 정교한 버전은 됩니다.

AI Tools & Agents
스스로 진화하는 AI 에이전트 — 2026년의 새로운 패러다임
GenericAgent, Evolver, Open Agents — 스스로 스킬을 만들고, 실행 경로를 기억하고, 실패에서 배우는 자가 진화 에이전트 3종 비교.

AI Tools & Agents
나만의 LLM Knowledge Base 구축하기 — Karpathy 스타일 지식 시스템
Obsidian + Claude Code로 영구적인 개인 지식 체계를 만드는 완전 가이드. 위키 + 메모리 두 축의 지식 시스템.