Learn AI by Building
Free tutorials, deep-dive series, and hands-on Jupyter notebooks for AI engineers and data scientists.
Tutorials
View All →LLM Agent Cookbook
Build AI agents from scratch — ReAct, Tool Use, Multi-Agent orchestration
ML Cookbook
Master machine learning algorithms with hands-on Jupyter projects
Data Analysis Cookbook
SQL, Pandas, Statistics — everything for data-driven decisions
Ontology & KG Cookbook
RDF, OWL, Neo4j, and GraphRAG for knowledge-powered AI
Premium Series
Our Products
Tools we built for developers and job seekers
DrillCheck
AI-powered mock interviews — practice with real questions and get instant feedback
VibeCheck
Vibe-check your project — get AI feedback on your side project ideas
SpecRadar
Find what to build next — discover gaps in existing products and market opportunities
SpecRadar Career
Hottest tech skills from job posts — newsletter and CV analysis for your career
Starter Kits
View All →Practice notebooks, interview questions, and project solutions — ready to download.
Browse Starter KitsLatest Posts
View All →
Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.
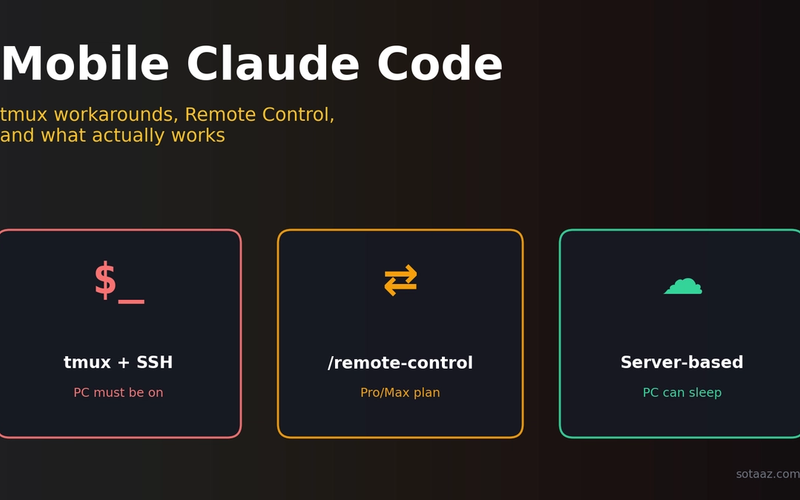
Mobile Claude Code: three approaches, and what actually works
Three ways to reach Claude Code from your phone — tmux + SSH, /remote-control, and server-based agents. The real fix isn't "mobile support" but decoupling compute from your device.

Inside Google COSMO — The New Architecture of On-Device AI Agents
Deep-dive into COSMO, Google's next-gen AI assistant accidentally leaked before I/O 2026. Full breakdown of the 3-mode architecture: Gemini Nano + PI server + Hybrid routing.

Self-Evolving AI Agents — The New Paradigm of 2026
GenericAgent, Evolver, Open Agents — comparing 3 self-evolving agent frameworks that learn, adapt, and grow without human coding.
 Premium
PremiumBuild Your Own LLM Knowledge Base — A Karpathy-Style Knowledge System
Complete guide to building a permanent personal knowledge system with Obsidian + Claude Code. Wiki + Memory dual-axis architecture.

Why Karpathy's CLAUDE.md Got 48K Stars — And How to Write Your Own
One markdown file raised AI coding accuracy from 65% to 94%. Analyzing Karpathy's 4 rules and practical writing guide.