Models & Algorithms
38 posts in this category
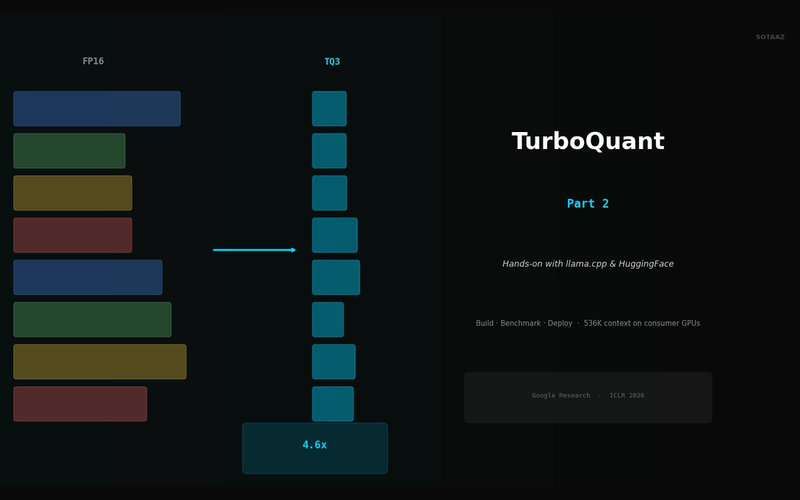
TurboQuant in Practice — KV Cache Compression with llama.cpp and HuggingFace
Build llama.cpp with turbo3, HuggingFace integration, memory calculator, config guide. 536K context on 70B models.
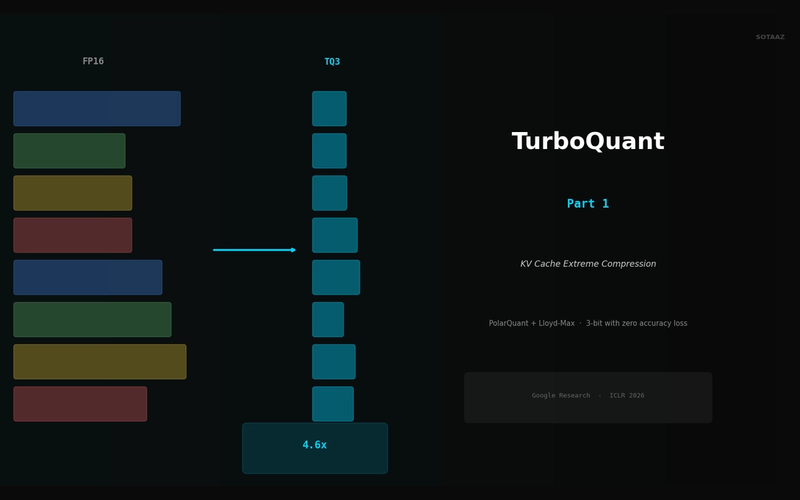
TurboQuant Explained — Google's Extreme KV Cache Compression Algorithm
Compress KV cache to 3-bit with PolarQuant + Lloyd-Max. 4.6x memory savings with zero accuracy loss, no retraining.

Qwen 3.5 Fine-Tuning Practical Guide — Build Your Own Model with LoRA
Complete guide to fine-tuning Qwen 3.5 with LoRA/QLoRA. From 8GB GPU QLoRA setup to Unsloth optimization, GGUF conversion, and Ollama deployment.

Qwen 3.5 Local Installation & Setup Guide — From Ollama to vLLM
Step-by-step guide to running Qwen 3.5 locally. From 5-minute Ollama setup to production vLLM servers, plus optimal model size selection per GPU.

Qwen 3.5 vs DeepSeek V3.2 — The 2026 Open-Source LLM Showdown
Complete comparison of Qwen 3.5 and DeepSeek V3.2: architecture, benchmarks, hardware requirements, and practical recommendations.

Agentic RAG Pipeline — Multi-step Retrieval in Production
Build a full Plan-Retrieve-Evaluate-Synthesize pipeline. Unify vector search, web search, and SQL as agent tools. Add hallucination detection and source grounding.

Self-RAG and Corrective RAG — The Agent Evaluates Its Own Retrieval
Implement Self-RAG reflection tokens and CRAG quality-based fallback. Build retry/fallback logic with LangGraph conditional edges.

Why Agentic RAG? — Query Routing and Adaptive Retrieval
Diagnose naive RAG limitations, classify query intent, and route to the optimal retrieval source with LangGraph. Implement adaptive retrieval that skips unnecessary searches.

From Evaluation to Deployment — The Complete Fine-tuning Guide
Evaluate with Perplexity and KoBEST benchmarks, merge LoRA weights, and deploy with vLLM/Ollama/HuggingFace Spaces.

QLoRA + Custom Dataset — Fine-tune 7B on a Single T4 GPU
Fine-tune a 7B model on a T4 16GB with QLoRA. Dataset construction, training execution, Wandb monitoring, and Before/After comparison.

Mastering LoRA — Fine-tune a 7B Model on a Single Notebook
From LoRA theory to Qwen 2.5 7B model setup. 99.8% parameter reduction and 86% memory savings vs full fine-tuning, explained with code.

SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.

Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.

YOLO26: Upgrade or Hype? The Complete Guide
Analyzing YOLO26's key features released in January 2026, comparing performance with YOLO11, and determining if it's worth upgrading through hands-on examples.

RAG Evaluation: Beyond Precision/Recall
"How do I know if my RAG is working?" — Precision/Recall aren't enough. You need to measure Faithfulness, Relevance, and Context Recall to see the real quality.

Retrieval Planning: ReAct vs Self-Ask vs Plan-and-Solve
Now that we've diagnosed Query Planning failures, it's time to fix them. Let's compare when each of these three patterns shines.

Query Planning Failures in Multi-hop RAG: Patterns and Solutions
You added Query Decomposition, but why does it still fail? Decomposition is just the beginning—the real problems emerge in Sequencing and Grounding.

Multi-hop RAG: Why It Still Fails After Temporal RAG
You added Temporal RAG, but "who is my boss's boss?" still returns wrong answers. RAG now understands time, but it still doesn't know "what to search for next."

GraphRAG: Microsoft's Global-Local Dual Search Strategy
Why can't traditional RAG answer "What are the main themes in these documents?" Microsoft Research's GraphRAG reveals the secret of community-based search.

CFG-free Distillation: Fast Generation Without Guidance
Eliminating the 2x computational cost of CFG. Achieving same quality with single forward pass.

Consistency Models: A New Paradigm for 1-Step Generation
Single-step generation without iterative sampling. OpenAI's innovative approach using self-consistency property.

SDE vs ODE: Mathematical Foundations of Score-based Diffusion
Stochastic vs Deterministic. A deep dive into Score-based SDEs and Probability Flow ODEs, the theoretical foundations of DDPM and DDIM.

Stable Diffusion 3 & FLUX: Complete Guide to MMDiT Architecture
From U-Net to Transformer. A deep dive into MMDiT architecture treating text and image equally, plus Rectified Flow and Guidance Distillation.

Rectified Flow: Straightening Paths Toward 1-Step Generation
Flow Matching still too slow? Reflow straightens trajectories for 1-step generation. The core technique behind SD3 and FLUX.

Flow Matching vs DDPM: Why ODE Beats SDE in Diffusion Models
DDPM needs 1000 steps, Flow Matching needs 10. The mathematics of straight-line generation. Comparing SDE curved paths vs ODE straight paths.
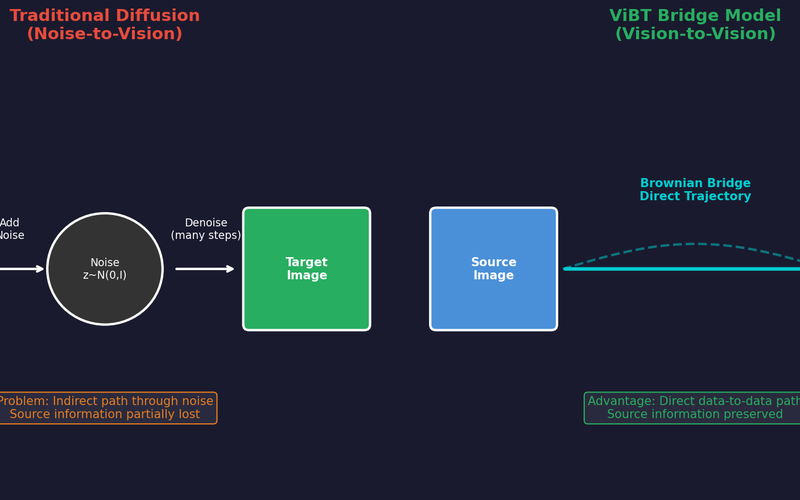
ViBT: The Beginning of Noise-Free Generation, Vision Bridge Transformer (Paper Review)
Analyzing ViBT's core technology and performance that transforms images/videos without noise using a Vision-to-Vision paradigm with Brownian Bridge.
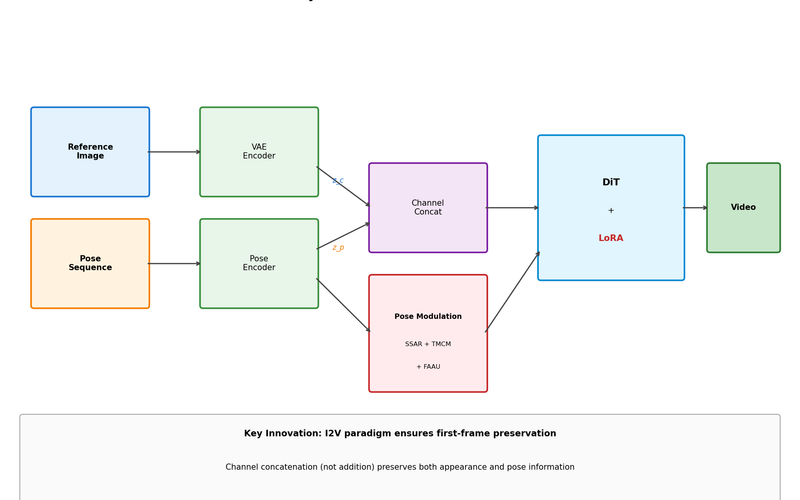
SteadyDancer Complete Analysis: A New Paradigm for Human Image Animation with First-Frame Preservation
Make a photo dance - why existing methods fail and how SteadyDancer solves the identity problem by guaranteeing first-frame preservation through the I2V paradigm.
Still Using GPT-4o for Everything? (How to Build an AI Orchestra & Save 90%)
An 8B model as conductor routes queries to specialized experts based on difficulty. ToolOrchestra achieves GPT-4o performance at 1/10th the cost using a Compound AI System approach.

SANA: O(n²)→O(n) Linear Attention Generates 1024² Images in 0.6 Seconds
How Linear Attention solved Self-Attention quadratic complexity. The secret behind 100x faster generation compared to DiT.

PixArt-α: How to Cut Stable Diffusion Training Cost from $600K to $26K
23x training efficiency through Decomposed Training strategy. Making Text-to-Image models accessible to academic researchers.

DiT: Replacing U-Net with Transformer Finally Made Scaling Laws Work (Sora Foundation)
U-Net shows diminishing returns when scaled up. DiT improves consistently with size. Complete analysis of the architecture behind Sora.

From 512×512 to 1024×1024: How Latent Diffusion Broke the Resolution Barrier
How Latent Space solved the memory explosion problem of pixel-space diffusion. Complete analysis from VAE compression to Stable Diffusion architecture.

DDIM: 20x Faster Diffusion Sampling with Zero Quality Loss (1000→50 Steps)
Use your DDPM pretrained model as-is but sample 20x faster. Mathematical derivation of probabilistic→deterministic conversion and eta parameter tuning.

DDPM Math Walkthrough: Deriving Forward/Reverse Process Step by Step
Generate high-quality images without GAN mode collapse. Derive every equation from β schedule to loss function and truly understand how DDPM works.

Why Your Translation Model Fails on Long Sentences: Context Vector Bottleneck Explained
BLEU score drops by half when sentences exceed 40 words. Deep analysis from information theory and gradient flow perspectives, proving why Attention is necessary.

Bahdanau vs Luong Attention: Which One Should You Actually Use? (Spoiler: Luong)
Experimental comparison of additive vs multiplicative attention performance and speed. Why Luong is preferred in production, proven with code.

Building Seq2Seq from Scratch: How the First Neural Architecture Solved Variable-Length I/O
How Encoder-Decoder architecture solved the fixed-size limitation of traditional neural networks. From mathematical foundations to PyTorch implementation.

AdamW vs Lion: Save 33% GPU Memory While Keeping the Same Performance
How Lion optimizer saves 33% memory compared to AdamW, and the hyperparameter tuning guide for real-world application. Use it wrong and you lose.