RAG Evaluation: Beyond Precision/Recall
"How do I know if my RAG is working?" — Precision/Recall aren't enough. You need to measure Faithfulness, Relevance, and Context Recall to see the real quality.
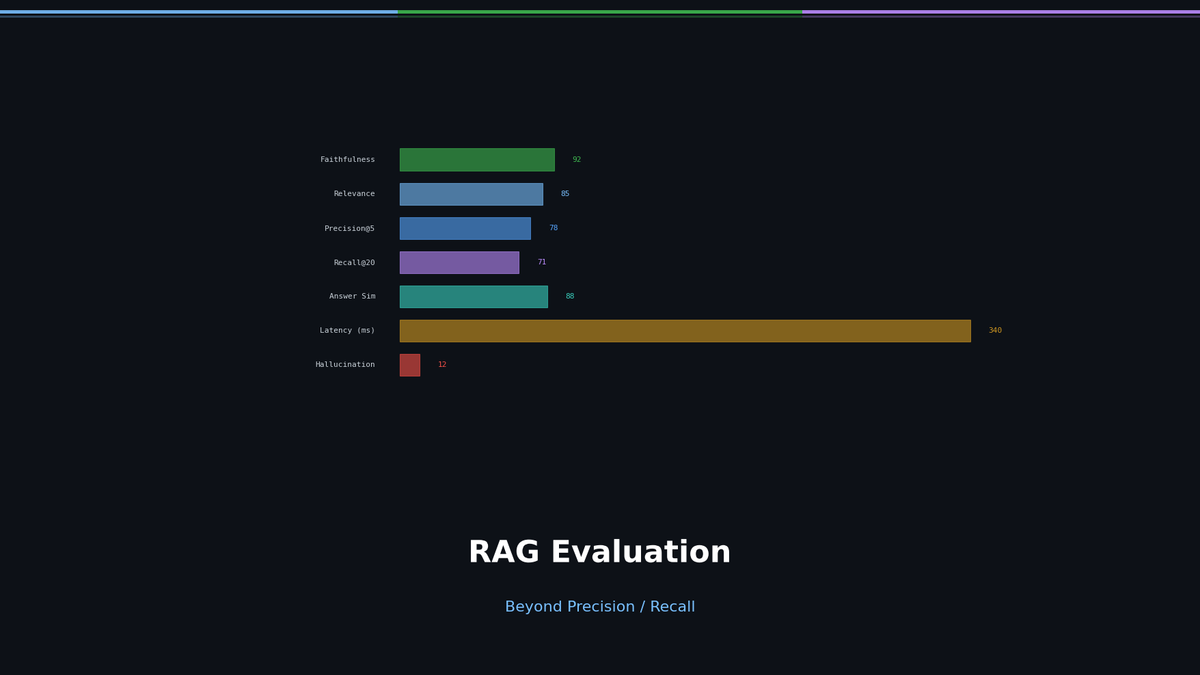
RAG Evaluation: Beyond Precision/Recall
"How do I know if my RAG is working?" — Precision/Recall aren't enough. You need to measure Faithfulness, Relevance, and Context Recall to see the real quality.
Why Traditional Metrics Fall Short
Traditional IR (Information Retrieval) metrics:
| Metric | Measures | Limitation in RAG |
|---|---|---|
| Precision@K | Relevant docs in top K | May not correlate with answer quality |
| Recall@K | Retrieved relevant docs / all relevant | Requires ground truth, often impractical |
| MRR | Rank of first relevant doc | Meaningless when multiple docs needed |
Related Posts

AI Research
Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.

AI Tools & Agents
Self-Evolving AI Agents — The New Paradigm of 2026
GenericAgent, Evolver, Open Agents — comparing 3 self-evolving agent frameworks that learn, adapt, and grow without human coding.

AI Tools & Agents
Build Your Own LLM Knowledge Base — A Karpathy-Style Knowledge System
Complete guide to building a permanent personal knowledge system with Obsidian + Claude Code. Wiki + Memory dual-axis architecture.