DiT: Replacing U-Net with Transformer Finally Made Scaling Laws Work (Sora Foundation)
U-Net shows diminishing returns when scaled up. DiT improves consistently with size. Complete analysis of the architecture behind Sora.

DiT: Diffusion Transformer - A New Paradigm Beyond U-Net
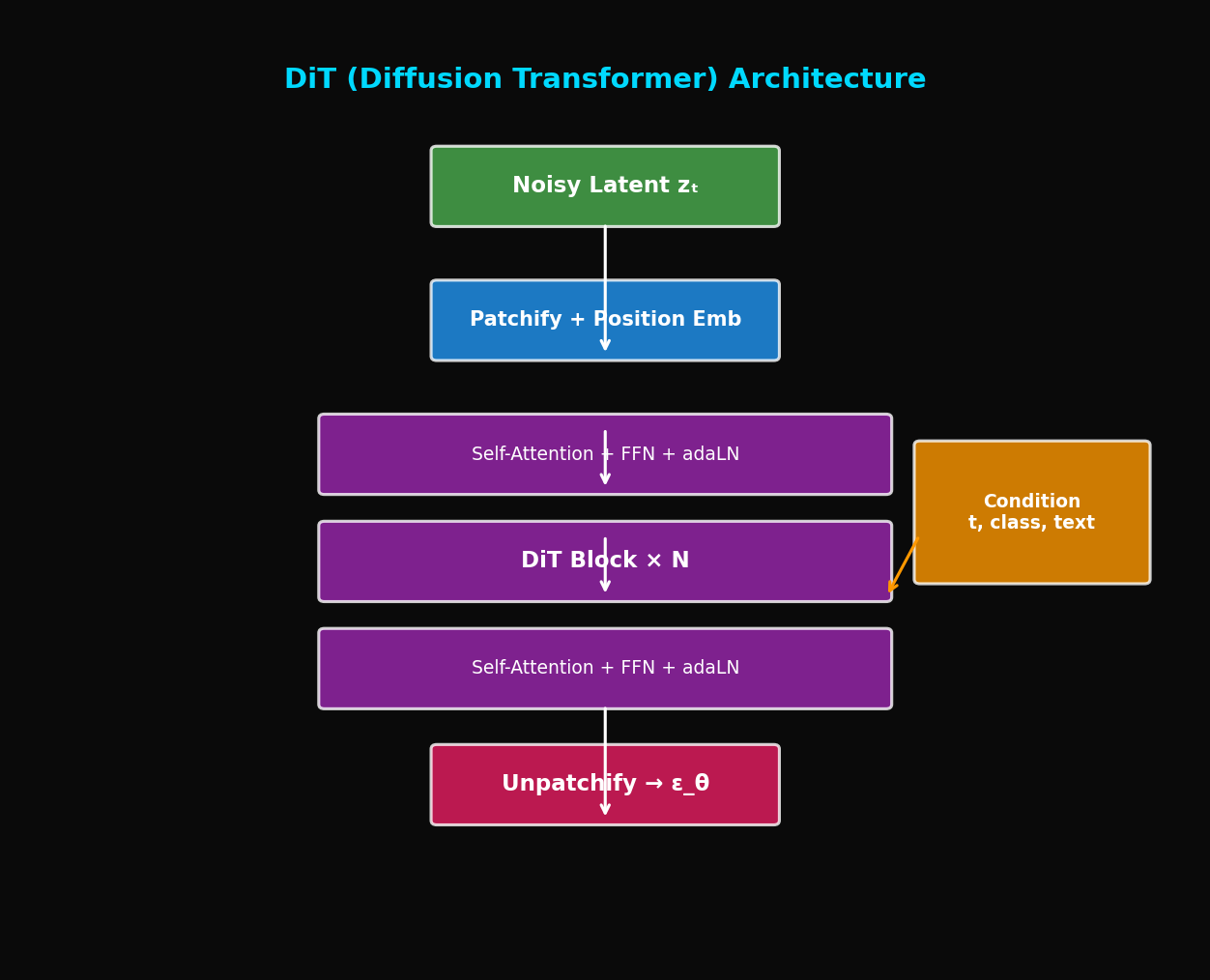
TL;DR: DiT replaces the Diffusion model's backbone from U-Net to Vision Transformer. Scaling laws apply, so performance consistently improves as the model grows larger. It's the foundation technology behind Sora.
1. Limitations of U-Net
1.1 Why U-Net?
Related Posts

Models & Algorithms
TurboQuant in Practice — KV Cache Compression with llama.cpp and HuggingFace
Build llama.cpp with turbo3, HuggingFace integration, memory calculator, config guide. 536K context on 70B models.

Models & Algorithms
TurboQuant Explained — Google's Extreme KV Cache Compression Algorithm
Compress KV cache to 3-bit with PolarQuant + Lloyd-Max. 4.6x memory savings with zero accuracy loss, no retraining.

Models & Algorithms
Qwen 3.5 Fine-Tuning Practical Guide — Build Your Own Model with LoRA
Complete guide to fine-tuning Qwen 3.5 with LoRA/QLoRA. From 8GB GPU QLoRA setup to Unsloth optimization, GGUF conversion, and Ollama deployment.