From Logit Lens to Tuned Lens: Reading the Intermediate Thoughts of Transformers
What happens inside an LLM between input and output? Logit Lens and Tuned Lens let us observe how Transformers build predictions layer by layer.

From Logit Lens to Tuned Lens: Reading the Intermediate Thoughts of Transformers
You type "The capital of France is" into an LLM and get back "Paris." But *where* inside the model did that answer actually form?
TL;DR
- Logit Lens projects intermediate hidden states to vocabulary space using the model's final unembedding matrix
- This reveals how Transformers build predictions incrementally, layer by layer
- Tuned Lens fixes Logit Lens's systematic bias by learning a lightweight affine transformation per layer
- Together, these tools give us a principled way to peek inside the black box
1. Where Does the Answer Come From?
When you ask GPT "What is the capital of France?", the answer "Paris" comes back in milliseconds. But think about it: the model has 32, 48, or even 96 layers. Did it "know" the answer at Layer 1? Did it only figure it out at the very last layer? Or did it gradually build up confidence somewhere in the middle?
This is not just a philosophical question. If we could watch the model's internal state evolve from layer to layer, we would gain real insight into *how* these models think. We could debug failures, detect hallucinations, and understand what each layer actually contributes.
That is exactly what Logit Lens and Tuned Lens let us do.
2. Residual Stream: The Information Highway
Before we can understand how to "read" intermediate layers, we need to understand how information flows through a Transformer.
A Transformer does not pass information from one layer to the next like a conveyor belt. Instead, every layer reads from and writes to a shared vector called the residual stream. Think of it as a shared whiteboard that every layer can scribble on.
Mathematically, the hidden state at layer is:
Where:
- is the initial embedding (token embedding + positional embedding)
- Each attention block reads from the residual stream, computes something, and *adds* its result back
- Each MLP block does the same
This additive structure is crucial. It means is not some totally transformed representation; it is the original embedding *plus* a running total of every layer's contribution so far. The residual stream accumulates information.
Here is the key insight: at the very end, the model applies a final LayerNorm and then multiplies by the unembedding matrix to convert the hidden state into a probability distribution over the vocabulary. This is the *only* place where the model "speaks" in tokens.
So what happens if we apply that same final projection to an *intermediate* hidden state?
3. Logit Lens: The Simplest Window
The Core Idea
Logit Lens, introduced by nostalgebraist in a 2020 blog post, is beautifully simple. Take the hidden state at any intermediate layer and pretend the model stopped right there. Apply the final LayerNorm and unembedding matrix, and see what tokens the model would predict.
That is it. One matrix multiply. No training required. No modifications to the model.
The question it answers: "If the model were forced to make a prediction at layer l, what would it say?"
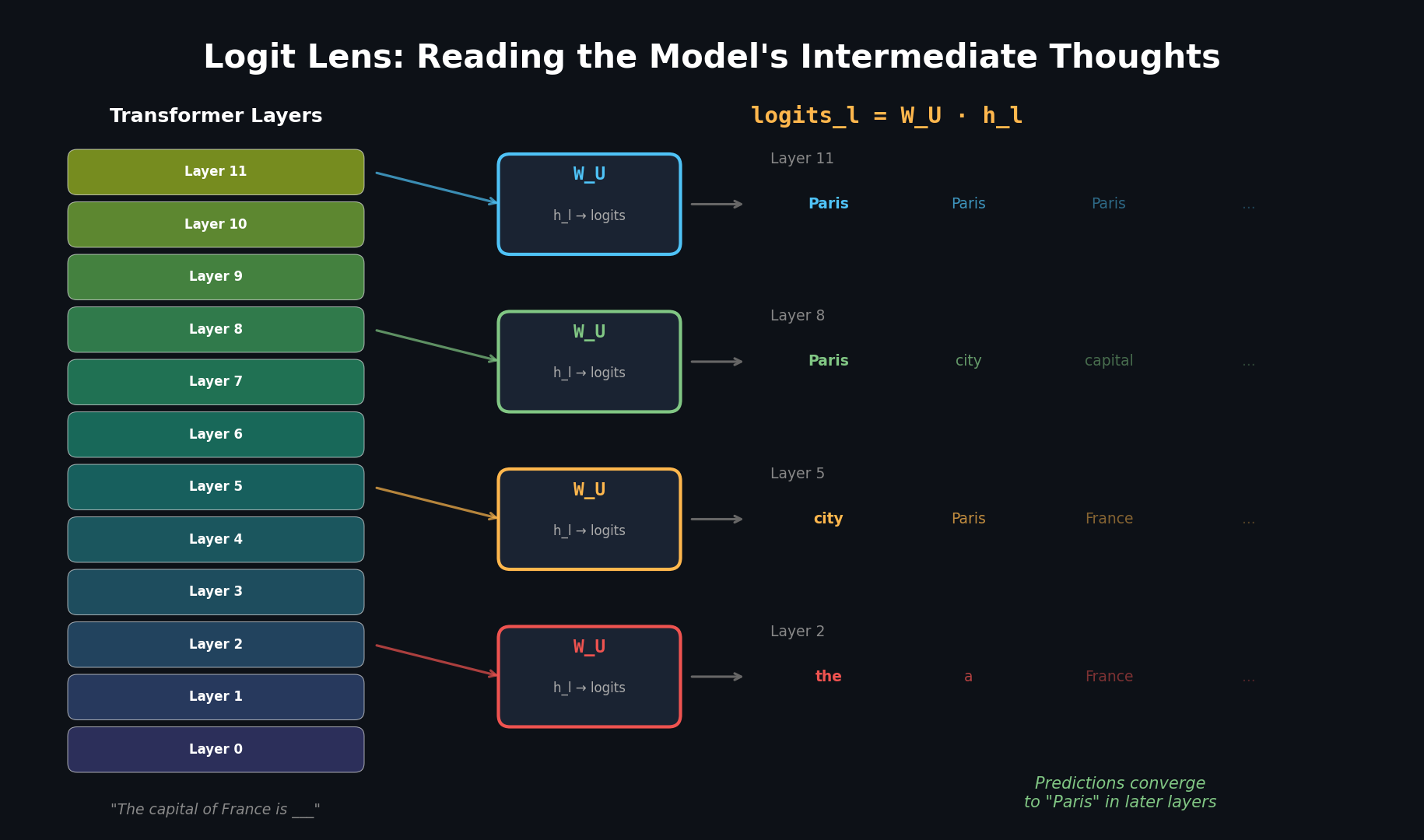
Walking Through an Example
Let's say we feed the prompt "The capital of France is" into GPT-2 and apply Logit Lens at every layer. Here is what we might see for the prediction at the final token position:
The numbers below are illustrative approximations showing the typical pattern observed in GPT-2. Exact values vary by model checkpoint and tokenizer version. See this series' companion notebook to reproduce the experiment yourself.
| Layer | Top-1 Prediction | Confidence | Runner-up |
|---|---|---|---|
| 0 | "the" | ~3% | "a" |
| 1 | "the" | ~4% | "not" |
| 2 | "a" | ~5% | "the" |
| 4 | "one" | ~6% | "a" |
| 8 | "located" | ~9% | "called" |
| 12 | "Paris" | ~14% | "the" |
| 16 | "Paris" | ~32% | "Lyon" |
| 20 | "Paris" | ~53% | "Lyon" |
| 24 | "Paris" | ~78% | "Lyon" |
Look at that progression. In the early layers, the model's "intermediate prediction" is essentially noise: common words like "the" and "a" that have nothing to do with the answer. Somewhere around the middle layers, "Paris" starts appearing. By the final layers, the model is highly confident.
This pattern shows up again and again across different prompts and models. It supports what researchers call the iterative inference hypothesis: Transformers do not compute the answer in one shot. They refine their predictions incrementally, layer by layer.
What Makes It So Compelling
The beauty of Logit Lens is that it requires zero extra machinery. You already have the unembedding matrix sitting right there in the model. You are just reusing it at places where the model never intended it to be used.
And the results are surprisingly interpretable. You can literally watch the model "make up its mind."
4. Limitations of Logit Lens
Logit Lens works remarkably well on GPT-2. But when researchers tried applying it to other models, problems emerged.
It Breaks on Some Models
Logit Lens gives coherent results on GPT-2 and GPT-J, but produces noisy or misleading outputs on:
- BLOOM: The multilingual model from BigScience
- GPT-Neo: EleutherAI's GPT-3 reproduction
- OPT: Meta's open pre-trained Transformer
Why? Logit Lens rests on a hidden assumption: that every intermediate layer's representation lives in roughly the same space as the final layer. The unembedding matrix was trained to decode the *final* hidden state. When intermediate layers use a significantly different internal coordinate system, applying produces garbage.
Systematic Bias
Even on models where Logit Lens "works," it has a systematic bias. Belrose et al. (2023) measured this precisely: Logit Lens predictions have a KL divergence of 4-5 bits from the model's actual behavior, even at the final layer.
Think about what that means. Even at the last layer, Logit Lens does not perfectly reproduce what the model is actually doing. There is a persistent distortion.
Representational Drift
The core problem is what we might call representational drift. Early layers operate in a different "dialect" than later layers. The residual stream at Layer 2 encodes information differently than at Layer 30, even though both are vectors of the same dimension. Applying the final-layer decoder to an early-layer vector is like using an English dictionary to read French: you will occasionally get lucky (cognates), but systematically you will be wrong.
5. Tuned Lens: Learning Layer-Specific Decoders
The Fix
Tuned Lens, introduced by Belrose et al. (2023) in "Eliciting Latent Predictions from Transformers with the Tuned Lens," addresses the systematic bias of Logit Lens with an elegant fix: learn a lightweight affine transformation for each layer that "translates" that layer's representation into the final layer's space.
Where is a learned affine probe specific to layer . That is it. One matrix multiply and one bias term per layer, and then Logit Lens as usual.
The Translator Analogy
Here is the best way to think about the difference:
- Logit Lens = Using a single English-to-English dictionary for all your translation needs. Works great when the source text is English. Gives gibberish when the source text is French, German, or Mandarin.
- Tuned Lens = Hiring a specialist translator for each language. The French specialist converts French to English, the German specialist converts German to English, and *then* you look up words in the English dictionary.
Each layer "speaks" its own dialect. Tuned Lens learns a translator for each dialect. After translation, the standard unembedding matrix works properly.
Training Details
The affine probes are trained with the following recipe:
- Objective: Minimize KL divergence between the Tuned Lens output at layer and the model's actual final-layer output
- Initialization: Each starts as the identity matrix, starts as zero. This means Tuned Lens starts *exactly* as Logit Lens and then learns corrections
- Optimizer: L-BFGS (a second-order optimizer that converges quickly for convex-ish problems)
- Model weights: Completely frozen. We never touch the model itself
Constraints: initialized to identity matrix , initialized to zero vector . Model weights are frozen (only are learned). Optimizer: L-BFGS.
The identity initialization is a nice design choice. It means the optimization starts from the Logit Lens solution and only departs from it as much as the data requires. If Logit Lens already works perfectly at some layer, Tuned Lens will learn and reproduce Logit Lens exactly.
The total number of additional parameters is tiny: for a model with hidden dimension and layers, each probe has parameters, and there are probes. That is about 537M parameters total, which sounds like a lot, but it is trained in minutes on a single GPU because L-BFGS converges fast on this problem.
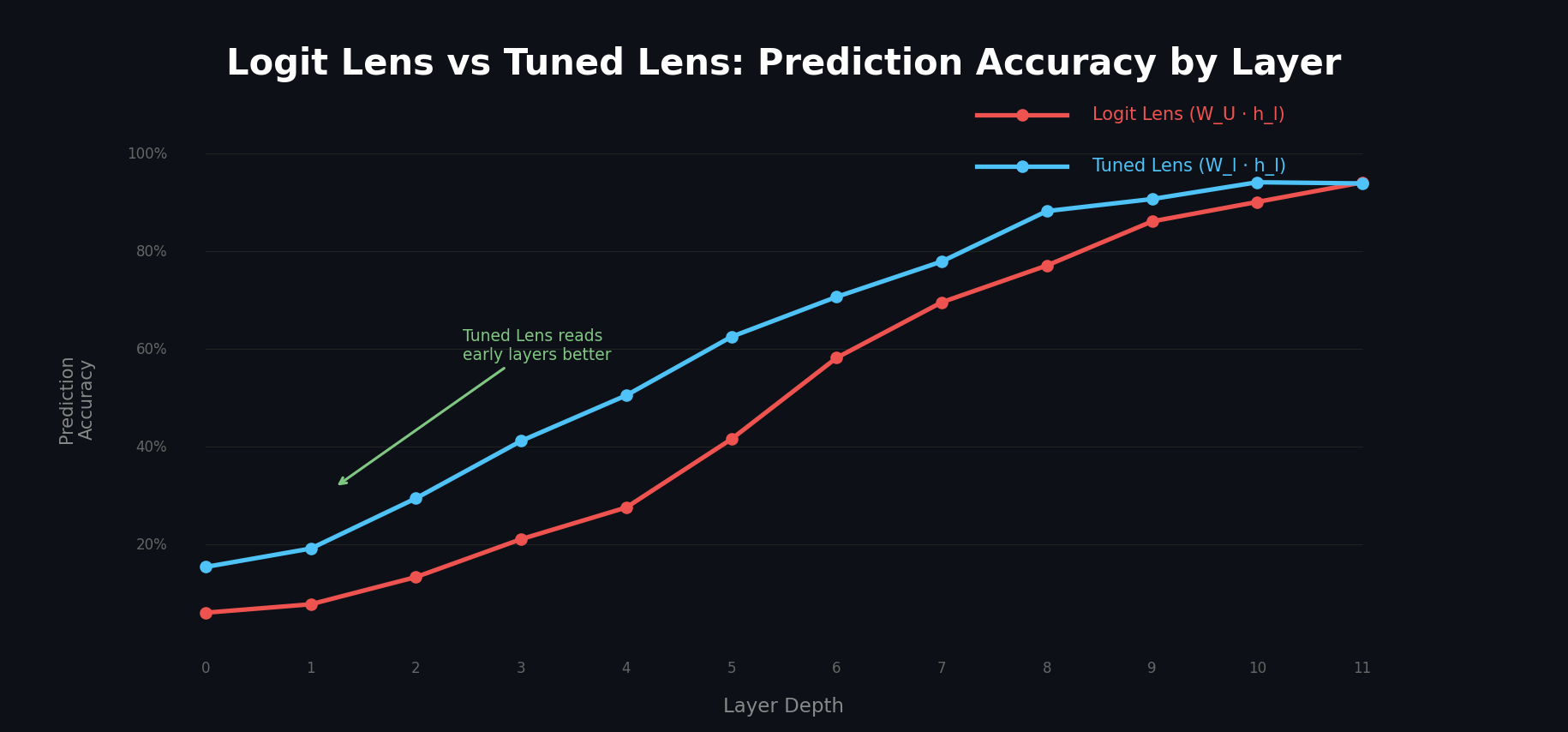
6. Quantitative Improvements
Belrose et al. (2023) ran extensive experiments comparing Logit Lens and Tuned Lens across multiple model families. The results are striking.
Prediction Quality
| Metric | Logit Lens | Tuned Lens | Improvement |
|---|---|---|---|
| Bias (KL divergence) | 4-5 bits | ~0.1 bits | ~40x lower |
| Perplexity gap | Baseline | 30-50% lower | Significant |
| Cross-model consistency | Varies wildly | Consistent | Works on BLOOM, OPT, etc. |
The bias number is the most telling. Logit Lens has 4-5 bits of systematic distortion; Tuned Lens reduces this to about 0.1 bits. This means Tuned Lens is almost perfectly faithful to what the model is actually computing.
Causal Fidelity
A lens is only useful if what it shows you *actually matters* for the model's behavior. The authors measured this with causal experiments: if you perturb the hidden state at layer , does the Tuned Lens prediction change in the same way as the model's actual output?
The answer is yes. Tuned Lens achieves a Spearman correlation of 0.89 between its predicted changes and the model's actual changes. This means Tuned Lens is not just a good predictor; it is causally faithful.
Practical Application: Prompt Injection Detection
One immediately practical application: detecting prompt injection attacks. When a model processes a prompt injection, its internal layer-by-layer trajectory looks different from normal text. Tuned Lens can detect this:
| Detection Task | AUROC |
|---|---|
| Prompt injection (known attacks) | 0.99 |
| Prompt injection (zero-shot) | 1.00 |
An AUROC of 0.99-1.00 means near-perfect detection, even for previously unseen attacks. The model's own intermediate representations give away that something unusual is happening.
7. Code: Trying It Yourself
Logit Lens with TransformerLens
TransformerLens (by Neel Nanda) makes it straightforward to apply Logit Lens to any supported model.
import torch
from transformer_lens import HookedTransformer
# Load a model
model = HookedTransformer.from_pretrained("gpt2-small")
# Run the model and cache all intermediate states
prompt = "The capital of France is"
logits, cache = model.run_with_cache(prompt)
# Apply Logit Lens at each layer
for layer in range(model.cfg.n_layers):
# Get residual stream state after this layer
h_l = cache[f"blocks.{layer}.hook_resid_post"]
# Apply final LayerNorm
h_l_normed = model.ln_final(h_l)
# Apply unembedding matrix (Logit Lens)
logits_l = model.unembed(h_l_normed)
# Get the prediction for the last token position
probs = torch.softmax(logits_l[0, -1, :], dim=-1)
top_token_id = torch.argmax(probs).item()
top_token = model.tokenizer.decode(top_token_id)
confidence = probs[top_token_id].item()
print(f"Layer {layer:2d}: {top_token:>15s} ({confidence:.1%})")Expected output (illustrative — exact values are model-dependent):
Layer 0: the (~3%)
Layer 1: the (~4%)
Layer 2: a (~5%)
Layer 3: one (~6%)
Layer 4: one (~6%)
Layer 5: also (~7%)
Layer 6: located (~9%)
Layer 7: called (~9%)
Layer 8: Paris (~11%)
Layer 9: Paris (~19%)
Layer 10: Paris (~34%)
Layer 11: Paris (~68%)Tuned Lens with the tuned-lens Library
The authors released an official Python library:
# Install
# pip install tuned-lens
from tuned_lens import TunedLens
from transformer_lens import HookedTransformer
import torch
# Load model and Tuned Lens
model = HookedTransformer.from_pretrained("gpt2-small")
tuned_lens = TunedLens.from_model_and_pretrained(model)
# Run with cache
prompt = "The capital of France is"
logits, cache = model.run_with_cache(prompt)
# Compare Logit Lens vs Tuned Lens at each layer
print(f"{'Layer':>5} | {'Logit Lens':>15} | {'Tuned Lens':>15}")
print("-" * 45)
for layer in range(model.cfg.n_layers):
h_l = cache[f"blocks.{layer}.hook_resid_post"]
# Logit Lens
h_normed = model.ln_final(h_l)
logit_lens_logits = model.unembed(h_normed)
logit_lens_pred = model.tokenizer.decode(
torch.argmax(logit_lens_logits[0, -1, :]).item()
)
# Tuned Lens (applies learned affine transform first)
tuned_logits = tuned_lens(h_l, layer)
tuned_pred = model.tokenizer.decode(
torch.argmax(tuned_logits[0, -1, :]).item()
)
print(f"{layer:5d} | {logit_lens_pred:>15s} | {tuned_pred:>15s}")Visualizing the Prediction Trajectory
You can also visualize how predictions evolve across all layers and token positions:
import numpy as np
import matplotlib.pyplot as plt
def plot_lens_heatmap(model, cache, prompt_tokens, lens_fn, title):
"""
Plot a heatmap of top-1 prediction confidence across
layers (y-axis) and token positions (x-axis).
"""
n_layers = model.cfg.n_layers
n_tokens = len(prompt_tokens)
confidence_map = np.zeros((n_layers, n_tokens))
for layer in range(n_layers):
h_l = cache[f"blocks.{layer}.hook_resid_post"]
logits_l = lens_fn(h_l, layer)
probs = torch.softmax(logits_l[0], dim=-1)
# Get the confidence of the "correct" next token
for pos in range(n_tokens - 1):
next_token_id = prompt_tokens[pos + 1]
confidence_map[layer, pos] = probs[pos, next_token_id].item()
fig, ax = plt.subplots(figsize=(12, 8))
im = ax.imshow(confidence_map, aspect="auto", cmap="viridis")
ax.set_xlabel("Token Position")
ax.set_ylabel("Layer")
ax.set_title(title)
plt.colorbar(im, label="Confidence")
plt.tight_layout()
plt.savefig(f"{title.lower().replace(' ', '_')}.png", dpi=150)
plt.show()8. What Lens Shows vs. What It Doesn't
Logit Lens and Tuned Lens are powerful observational tools. But it is important to be clear about what they do and do not tell us.
What They Show
- Layer-by-layer prediction trajectory: How the model's "best guess" evolves from input to output
- When information appears: At which layer does the model first "know" the answer?
- Prediction confidence: How certain the model is at each layer
- Anomaly detection: When the internal trajectory looks unusual (prompt injection, distribution shift)
What They Do Not Show
- Causality: Just because "Paris" appears at Layer 12 does not mean Layer 12 *computed* the answer. It might have been computed earlier and only became decodable at Layer 12 because the representation shifted into a space that can read.
- Mechanism: Lens tells you *what* the model is predicting but not *how* it arrived at that prediction. Which attention heads contributed? Which MLP neurons fired? Lens cannot answer these questions.
- Counterfactuals: Lens shows what the model predicts on *this* input. It does not tell you what would happen on a different input without actually running the model again.
The distinction between observation and intervention is fundamental in science. Observing that a patient's temperature rises before they feel sick does not mean the fever *caused* the sickness. To establish causation, you need to intervene.
In the mechanistic interpretability world, the intervention counterpart to Lens is Activation Patching (also called causal tracing). This is where you take a hidden state from one run of the model and patch it into a different run, then observe the effect on the output. If patching the hidden state at Layer 12 causes the output to change, then Layer 12 is causally important.
We will cover Activation Patching in depth in Part 2 of this series.
9. Wrap-up
Comparison at a Glance
| Aspect | Logit Lens | Tuned Lens |
|---|---|---|
| Year | 2020 | 2023 |
| Author | nostalgebraist | Belrose et al. |
| Extra parameters | None | Affine probe per layer |
| Training required | No | Yes (minutes) |
| Bias (KL div) | 4-5 bits | ~0.1 bits |
| Cross-model support | GPT-2 family | GPT-2, BLOOM, OPT, GPT-Neo, etc. |
| Causal fidelity | Not measured | Spearman rho = 0.89 |
| Best use case | Quick exploration | Rigorous analysis |
| Conceptual insight | Very high | Very high |
The Big Picture
Logit Lens gave us the first way to peek inside Transformers and watch them "think." It showed us that these models build predictions incrementally, not all at once. Tuned Lens took that insight and made it rigorous, fixing the systematic biases and extending it to models where Logit Lens fails.
But both are fundamentally observational tools. They show us *what* the model is thinking, not *why*. To understand the why, we need to move from observation to intervention.
Next up: Part 2 - Activation Patching and Causal Tracing
We will take the natural next step: instead of just reading the model's intermediate states, we will start *editing* them and watching what happens. This will give us true causal evidence about which components of the model are responsible for which behaviors.
References
- nostalgebraist. (2020). "interpreting GPT: the logit lens." LessWrong blog post. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
- Belrose, N., Furman, H., Smith, L., Halawi, D., Oesterling, A., McKinney-Bock, K., Steinhardt, J., Jermyn, A., & Bowman, S. (2023). "Eliciting Latent Predictions from Transformers with the Tuned Lens." arXiv:2303.08112. https://arxiv.org/abs/2303.08112
- Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., DasSarma, N., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S., & Olah, C. (2021). "A Mathematical Framework for Transformer Circuits." Anthropic. https://transformer-circuits.pub/2021/framework/index.html
- Nanda, N. (2022). TransformerLens library. https://github.com/TransformerLensOrg/TransformerLens
- Geva, M., Schuster, R., Berant, J., & Levy, O. (2021). "Transformer Feed-Forward Layers Are Key-Value Memories." EMNLP. https://arxiv.org/abs/2012.14913
- Dar, G., Geva, M., Gupta, A., & Berant, J. (2023). "Analyzing Transformers in Embedding Space." ACL. https://arxiv.org/abs/2209.02535
- din (tuned-lens library). https://github.com/AlignmentResearch/tuned-lens
Subscribe to Newsletter
Related Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.

MIRAGE — Do Multimodal AIs Actually "See" Images?
GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 retain 70-80% of benchmark scores without any image input. A 3B text-only model outperforms all multimodal models and radiologists on chest X-ray benchmarks. Stanford MIRAGE paper review.

InternVL-U: Understanding + Generation + Editing in One 4B Model -- A New Standard for Unified Multimodal AI
Shanghai AI Lab's InternVL-U. A single 4B parameter model handles image understanding, generation, editing, and reasoning-based generation. Decoupled visual representations outperform 14B BAGEL on GenEval and DPG-Bench.