Logit Lens에서 Tuned Lens까지: Transformer의 중간 사고를 읽는 법
LLM의 내부에서는 무슨 일이 벌어지고 있을까? Logit Lens와 Tuned Lens를 통해 Transformer가 layer마다 어떻게 답을 만들어가는지 직접 들여다본다.

Logit Lens에서 Tuned Lens까지: Transformer의 중간 사고를 읽는 법
대형 언어 모델(LLM)에게 "프랑스의 수도는?"이라고 물으면 "파리"라고 답합니다.
하지만 이 답은 어디서 만들어진 것일까요? 첫 번째 layer에서? 마지막 layer에서? 아니면 중간 어딘가에서 서서히 형성된 것일까요?
Mechanistic interpretability의 핵심 도구인 Lens 계열은 바로 이 질문에 답합니다. 모델의 중간 hidden state를 사람이 읽을 수 있는 형태로 "투영"하여, layer마다 모델이 무엇을 생각하고 있는지 직접 관찰하는 것입니다.
이 글에서는 가장 단순한 Logit Lens부터 학습 기반의 Tuned Lens까지, Transformer 내부를 읽는 방법의 발전 과정을 정리합니다.
1. Residual Stream: 정보의 고속도로
Lens를 이해하려면 먼저 Transformer의 구조를 다시 살펴볼 필요가 있습니다.
Transformer는 단순히 "layer를 쌓은 것"이 아닙니다. 핵심은 residual stream입니다.
각 layer의 attention과 MLP는 residual stream에 정보를 더하는 역할을 합니다. 즉, hidden state 은 이전 모든 layer의 기여가 누적된 결과입니다.
이를 수식으로 쓰면:
residual stream이 중요한 이유는 이것이 모델의 "작업 메모리"이기 때문입니다. 각 layer는 이 메모리를 읽고, 계산하고, 결과를 다시 메모리에 씁니다.
그렇다면 자연스러운 질문이 생깁니다:
이 중간 메모리(hidden state)를 직접 들여다보면, 모델이 그 시점에서 무엇을 "생각"하고 있는지 알 수 있지 않을까요?
2. Logit Lens: 가장 단순한 창
핵심 아이디어
Transformer의 마지막 단계는 무엇일까요? hidden state를 vocabulary 위의 확률 분포로 변환하는 것입니다:
여기서 는 unembedding matrix로, hidden state를 vocab 크기의 벡터로 projection합니다. 이 logits에 softmax를 취하면 각 단어의 예측 확률을 얻습니다.
Logit Lens의 아이디어는 극도로 단순합니다:
마지막 layer의 hidden state 대신, 중간 layer의 hidden state에 같은 변환을 적용하면?
즉, layer 의 hidden state를 마치 "최종 출력인 것처럼" 다뤄서 vocabulary distribution으로 변환하는 것입니다. 이를 통해 다음 질문에 답할 수 있습니다:
"이 layer에서 모델은 이미 어떤 단어를 예측하고 있는가?"
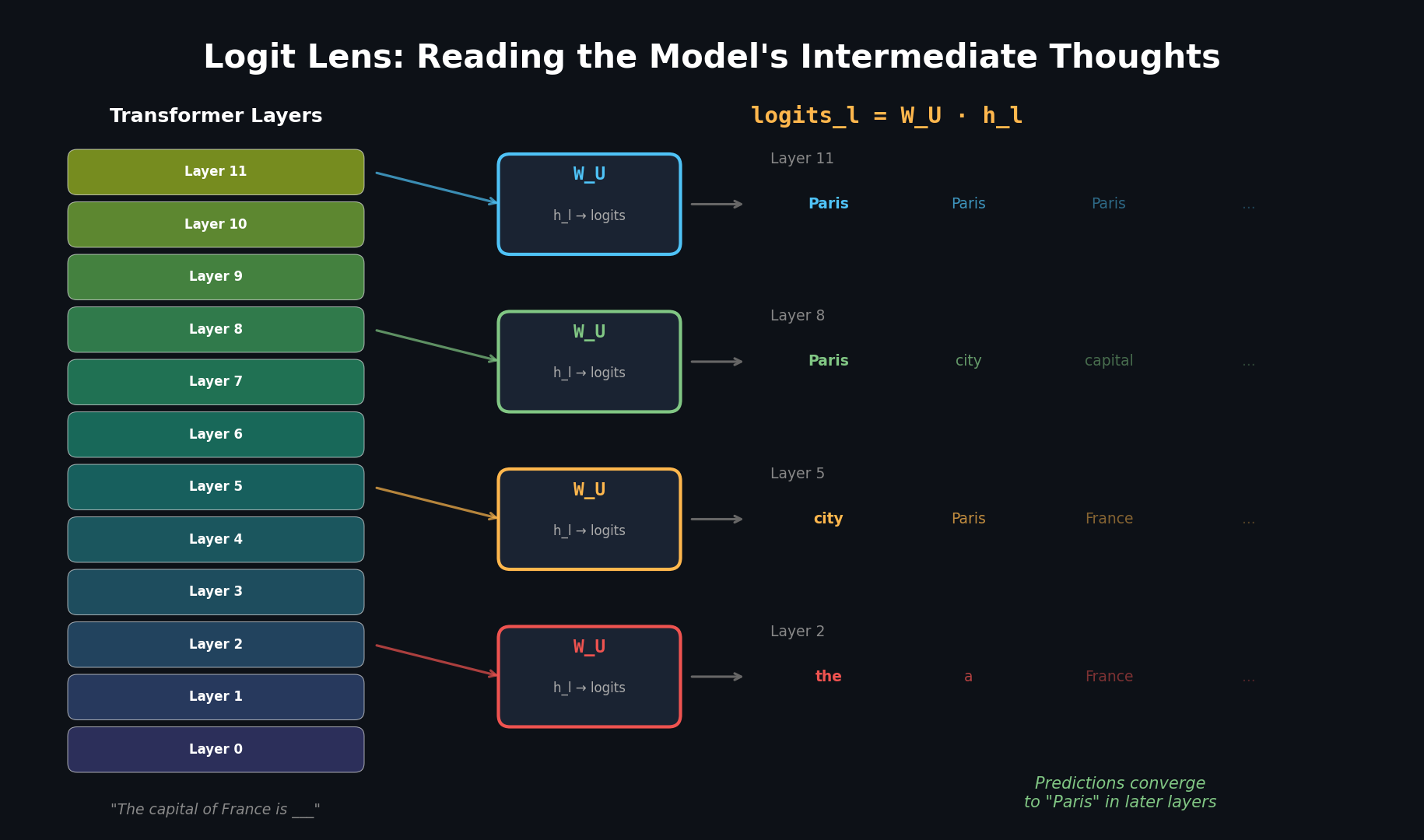
동작 예시: "The capital of France is ___"
GPT-2에 "The capital of France is"를 넣고 각 layer에서 top prediction을 관찰해 보겠습니다.
아래 수치는 GPT-2 Small에서 관찰되는 전형적인 패턴을 보여주기 위한 설명용 근사값입니다. 정확한 값은 모델 체크포인트와 토크나이저 버전에 따라 달라집니다. 직접 실행해보려면 이 시리즈의 실습 노트북을 참고하세요.
| Layer | Top-1 Prediction | Confidence |
|---|---|---|
| 0 | "the" | ~3% |
| 2 | "a" | ~4% |
| 4 | "the" | ~6% |
| 6 | "Paris" | ~8% |
| 8 | "Paris" | ~25% |
| 10 | "Paris" | ~69% |
| 11 (final) | "Paris" | ~82% |
초기 layer에서는 문법적으로 그럴듯한 단어("the", "a")가 후보지만, layer가 깊어질수록 "Paris"로 수렴합니다.
이것이 바로 iterative inference 가설입니다:
Transformer는 한 번에 답을 내는 것이 아니라, layer를 거칠 때마다 답을 점진적으로 개선합니다.
마치 사람이 문제를 풀 때 처음에는 막연한 감을 잡다가 점점 확신을 갖게 되는 것과 같습니다.
Prediction Depth: 모델은 언제 답을 알까
Logit Lens는 prediction depth라는 흥미로운 개념을 가능하게 합니다. 특정 입력에 대해 모델이 "정답을 처음으로 맞추는 layer"를 찾을 수 있는 것입니다.
- "France → Paris"는 비교적 얕은 layer에서 확정됨 (잘 알려진 사실)
- "대한민국의 최초 대통령은?"같은 질문은 더 깊은 layer에서 확정됨
- 학습 초기에 배운 지식일수록 prediction depth가 얕은 경향이 있음
이는 모델의 지식이 어떻게 조직되어 있는지에 대한 실마리를 제공합니다.
3. Logit Lens의 한계
Logit Lens는 직관적이고 구현이 간단하지만, 심각한 한계가 있습니다.
한계 1: 특정 모델에서 완전히 실패
Logit Lens는 GPT-2에서는 잘 작동하지만, BLOOM, GPT-Neo, OPT 등의 모델에서는 중간 layer 예측이 완전히 의미없는 결과를 냅니다.
왜일까요? Logit Lens의 암묵적인 가정 때문입니다:
"모든 layer의 hidden state는 최종 layer와 같은 표현 공간(representation space)에 있다"
하지만 이는 사실이 아닙니다. 각 layer는 서로 다른 basis를 사용할 수 있고, 학습 과정에서 representation이 점진적으로 변형(drift)됩니다.
한계 2: 체계적인 편향 (Systematic Bias)
Logit Lens의 예측은 실제 모델 출력과 체계적으로 다릅니다. 이 차이를 KL divergence로 측정하면:
| Method | Layer별 평균 KL Divergence |
|---|---|
| Logit Lens | 4-5 bits |
| Tuned Lens | ~0.1 bits |
4-5 bits의 KL divergence는 매우 큰 값입니다. 이는 Logit Lens가 보여주는 "중간 예측"이 모델의 실제 내부 상태를 상당히 왜곡하고 있다는 의미입니다.
한계 3: 표현 공간의 드리프트
수학적으로, layer 의 hidden state 의 공분산 행렬은 layer마다 상당히 달라집니다. 같은 행렬로 모든 layer를 해석하는 것은 마치 한국어 문장을 영어 사전으로 번역하려는 것과 같습니다. 때로는 우연히 맞을 수 있지만, 구조적으로 올바르지 않습니다.
4. Tuned Lens: Layer별 번역기를 학습하다
핵심 아이디어
Tuned Lens는 Logit Lens의 구조적 한계를 해결합니다. 핵심 아이디어는 다음과 같습니다:
각 layer마다 별도의 affine transformation(번역기)을 학습하여, 해당 layer의 표현 공간을 최종 layer의 표현 공간으로 올바르게 매핑합니다.
수식으로:
여기서 은 layer 에 맞춤 학습된 affine 변환입니다. 이를 논문에서는 "translator"라고 부릅니다.
비유로 이해하기
Logit Lens가 "모든 layer의 hidden state를 영어 사전으로 번역"하는 것이라면, Tuned Lens는 "각 layer의 언어에 맞는 전문 번역가를 배치"하는 것입니다.
- Layer 3의 hidden state → Layer 3 전용 translator → 최종 표현 공간 → vocab distribution
- Layer 7의 hidden state → Layer 7 전용 translator → 최종 표현 공간 → vocab distribution
이렇게 하면 각 layer의 고유한 표현 방식을 올바르게 "번역"할 수 있습니다.
학습 방법
Translator는 다음 목적함수를 최소화하도록 학습됩니다:
여기서:
- : layer 이후의 실제 모델 계산을 통과한 최종 출력 분포
- : translator를 통과한 예측 분포
- : 두 분포 사이의 KL divergence
즉, "이 layer의 hidden state로부터 최종 출력을 최대한 정확하게 예측하라"는 것이 학습 목표입니다.
중요한 점:
- 모델의 가중치는 동결(frozen) 상태로, translator만 학습합니다
- Identity로 초기화: translator가 처음에는 아무 변환도 하지 않는 상태(= Logit Lens와 동일)에서 시작하여, 필요한 보정만 학습합니다
- Optimizer: L-BFGS (또는 더 최신의 Muon optimizer)
- 학습 비용: 2^18 토큰을 250 step만 학습하면 충분합니다 (GPT 학습에 비하면 극히 적은 비용)
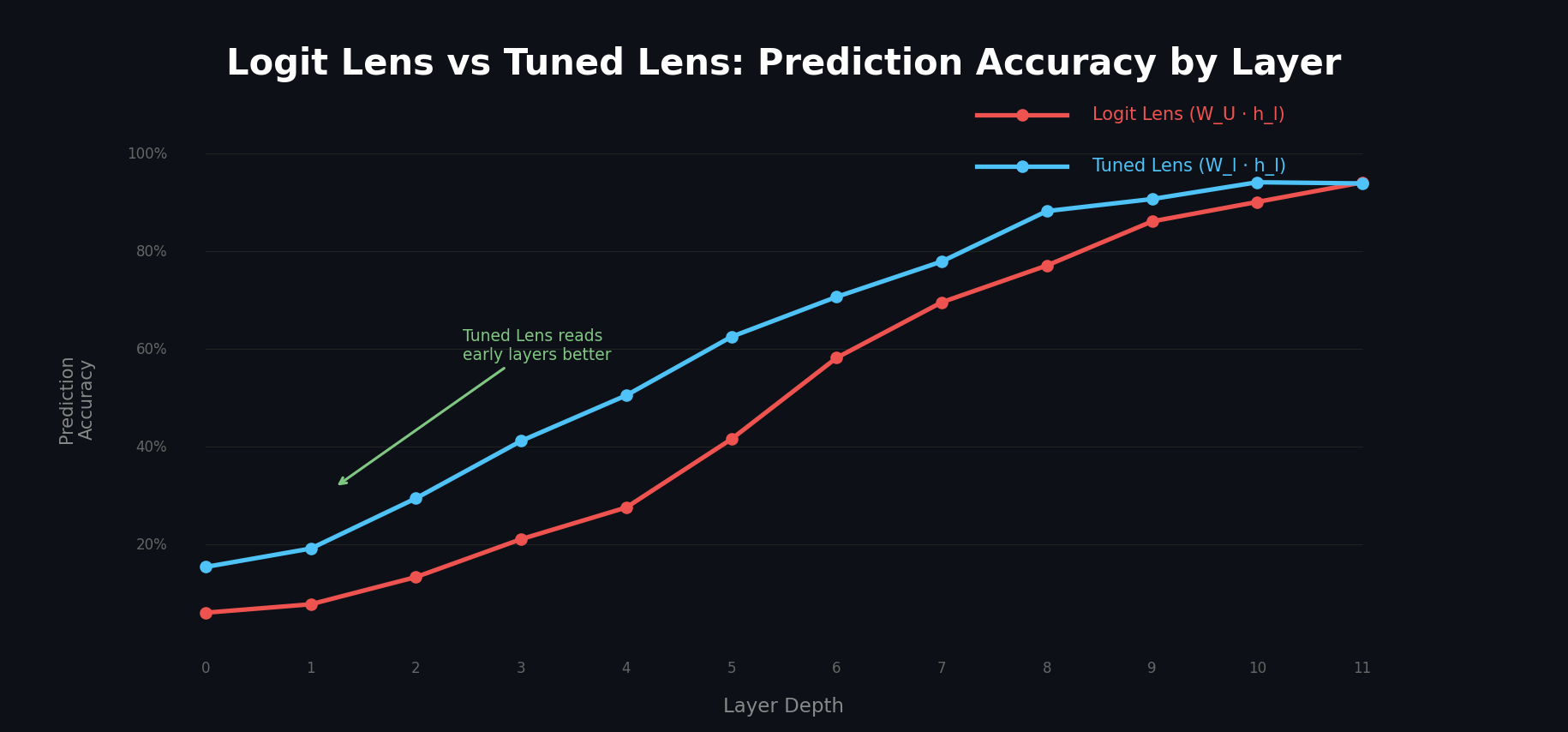
정량적 개선
Tuned Lens 논문(Belrose et al., 2023)의 주요 결과입니다:
1) Perplexity 30-50% 개선
Pythia, GPT-NeoX-20B 등 다양한 모델에서, Tuned Lens는 Logit Lens 대비 30-50% 낮은 perplexity를 달성했습니다. 특히 초기-중간 layer에서의 개선이 두드러집니다.
2) Bias 거의 제거
| 지표 | Logit Lens | Tuned Lens |
|---|---|---|
| KL Divergence (bias) | 4-5 bits | ~0.1 bits |
| 모든 모델에서 작동 | X (BLOOM, OPT 실패) | O |
3) 인과적 신뢰도 (Causal Fidelity)
Tuned Lens가 "중요하다"고 식별한 feature들은 실제 모델 출력에 대한 인과적 영향과 Spearman rho = 0.89의 상관관계를 보입니다. 즉, Tuned Lens가 보여주는 중간 예측은 단순히 "비슷해 보이는 것"이 아니라, 모델이 실제로 사용하는 정보를 반영하고 있습니다.
4) Prompt Injection 탐지
예측이 layer별로 어떻게 변하는지의 궤적(prediction trajectory)을 분석하면, 악의적 입력(prompt injection)을 탐지할 수 있습니다. BoolQ, MNLI, SST-2 등의 task에서 AUROC 0.99-1.00을 달성했습니다.
5. 코드로 보는 Lens
Logit Lens 구현 (TransformerLens 사용)
from transformer_lens import HookedTransformer
import torch
model = HookedTransformer.from_pretrained("gpt2-small")
prompt = "The capital of France is"
tokens = model.to_tokens(prompt)
# 모든 activation을 캐싱하며 forward pass
logits, cache = model.run_with_cache(tokens)
# 각 layer의 hidden state에 Logit Lens 적용
for layer in range(model.cfg.n_layers):
h_l = cache[f"blocks.{layer}.hook_resid_post"]
# LayerNorm + Unembedding = Logit Lens
h_ln = model.ln_final(h_l)
logits_l = model.unembed(h_ln)
# 마지막 position의 top prediction
top_token = model.to_string(logits_l[0, -1].argmax())
prob = logits_l[0, -1].softmax(dim=-1).max().item()
print(f"Layer {layer:2d}: {top_token:>15s} ({prob:.1%})")Tuned Lens 사용
from tuned_lens import TunedLens
# 사전 학습된 Tuned Lens 로드
tuned_lens = TunedLens.from_model_and_pretrained(model)
for layer in range(model.cfg.n_layers):
h_l = cache[f"blocks.{layer}.hook_resid_post"]
# Tuned Lens: affine transform + LayerNorm + Unembedding
logits_l = tuned_lens(h_l, layer)
top_token = model.to_string(logits_l[0, -1].argmax())
prob = logits_l[0, -1].softmax(dim=-1).max().item()
print(f"Layer {layer:2d}: {top_token:>15s} ({prob:.1%})")6. Lens가 보여주는 것, 그리고 보여주지 못하는 것
Lens 계열은 매우 강력한 분석 도구지만, 한계도 명확히 알아야 합니다.
Lens가 보여주는 것:
- layer별 예측 수렴 과정
- 어느 시점에서 모델이 "답을 아는지" (prediction depth)
- 서로 다른 모델 간 정보 처리 패턴 비교
- 비정상 입력 탐지 (prediction trajectory 이상 탐지)
Lens가 보여주지 못하는 것:
- "왜" 그 예측이 나오는지 (인과 관계)
- 어떤 attention head나 MLP 뉴런이 그 예측에 기여하는지
- 모델이 그 정보를 실제로 "사용"하고 있는지 vs 단순히 "갖고만" 있는지
이 한계를 극복하려면 causal intervention이 필요합니다. 이것이 바로 다음 글에서 다룰 Activation Patching의 영역입니다.
Wrap-up
| 방법 | 접근 | 장점 | 한계 |
|---|---|---|---|
| Logit Lens | $W_U \cdot \text{LN}(h_l)$ | 구현 극히 단순 | 모델별 불안정, 높은 bias |
| Tuned Lens | $W_U \cdot \text{LN}(A_l h_l + b_l)$ | 안정적, 낮은 bias, 범용 | 사전 학습 필요 |
Lens는 interpretability의 출발점입니다. 모델의 중간 사고를 읽을 수 있게 해줍니다.
하지만 "읽기"만으로는 부족합니다. 모델이 그 정보를 정말로 사용하는지 확인하려면, 직접 개입(intervention)하여 인과 관계를 확인해야 합니다.
다음 글에서는 TransformerLens를 사용한 Activation Patching으로, 모델의 causal circuit을 직접 추적하는 방법을 다룹니다.
References
- Belrose et al. *Eliciting Latent Predictions from Transformers with the Tuned Lens* (2023)
https://arxiv.org/abs/2303.08112
- nostalgebraist. *Logit Lens* (2020)
https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
- Anthropic. *A Mathematical Framework for Transformer Circuits*
https://transformer-circuits.pub
- Tuned Lens GitHub
https://github.com/AlignmentResearch/tuned-lens
- Neel Nanda. *Mechanistic Interpretability Intro*
https://www.neelnanda.io/mechanistic-interpretability
이메일로 받아보기
관련 포스트

MIRAGE — 멀티모달 AI는 정말로 이미지를 "보고" 있을까?
GPT-5.1, Gemini 3 Pro, Claude Opus 4.5가 이미지 없이도 벤치마크 점수의 70-80%를 유지. 3B 텍스트 전용 모델이 흉부 X-ray 벤치마크에서 모든 멀티모달 모델과 방사선과 전문의를 능가. 스탠포드 MIRAGE 논문 리뷰.

InternVL-U: 4B 파라미터로 이해+생성+편집을 동시에 -- 통합 멀티모달의 새 기준
Shanghai AI Lab의 InternVL-U. 4B 파라미터 단일 모델로 이미지 이해, 생성, 편집, 추론 기반 생성을 모두 수행. 디커플드 비주얼 표현으로 14B BAGEL을 GenEval과 DPG-Bench에서 능가.

Hybrid Mamba-Transformer MoE: 세 팀이 동시에 도달한 같은 결론 -- 2026년 LLM 아키텍처의 수렴
NVIDIA Nemotron 3 Nano, Qwen 3.5, Mamba-3가 독립적으로 75% 선형 레이어 + 25% 어텐션 + MoE 구조에 수렴. 88% KV-cache 절감, O(n) 복잡도로 긴 컨텍스트 처리.