MIRAGE — 멀티모달 AI는 정말로 이미지를 "보고" 있을까?
GPT-5.1, Gemini 3 Pro, Claude Opus 4.5가 이미지 없이도 벤치마크 점수의 70-80%를 유지. 3B 텍스트 전용 모델이 흉부 X-ray 벤치마크에서 모든 멀티모달 모델과 방사선과 전문의를 능가. 스탠포드 MIRAGE 논문 리뷰.

MIRAGE — 멀티모달 AI는 정말로 이미지를 "보고" 있을까?
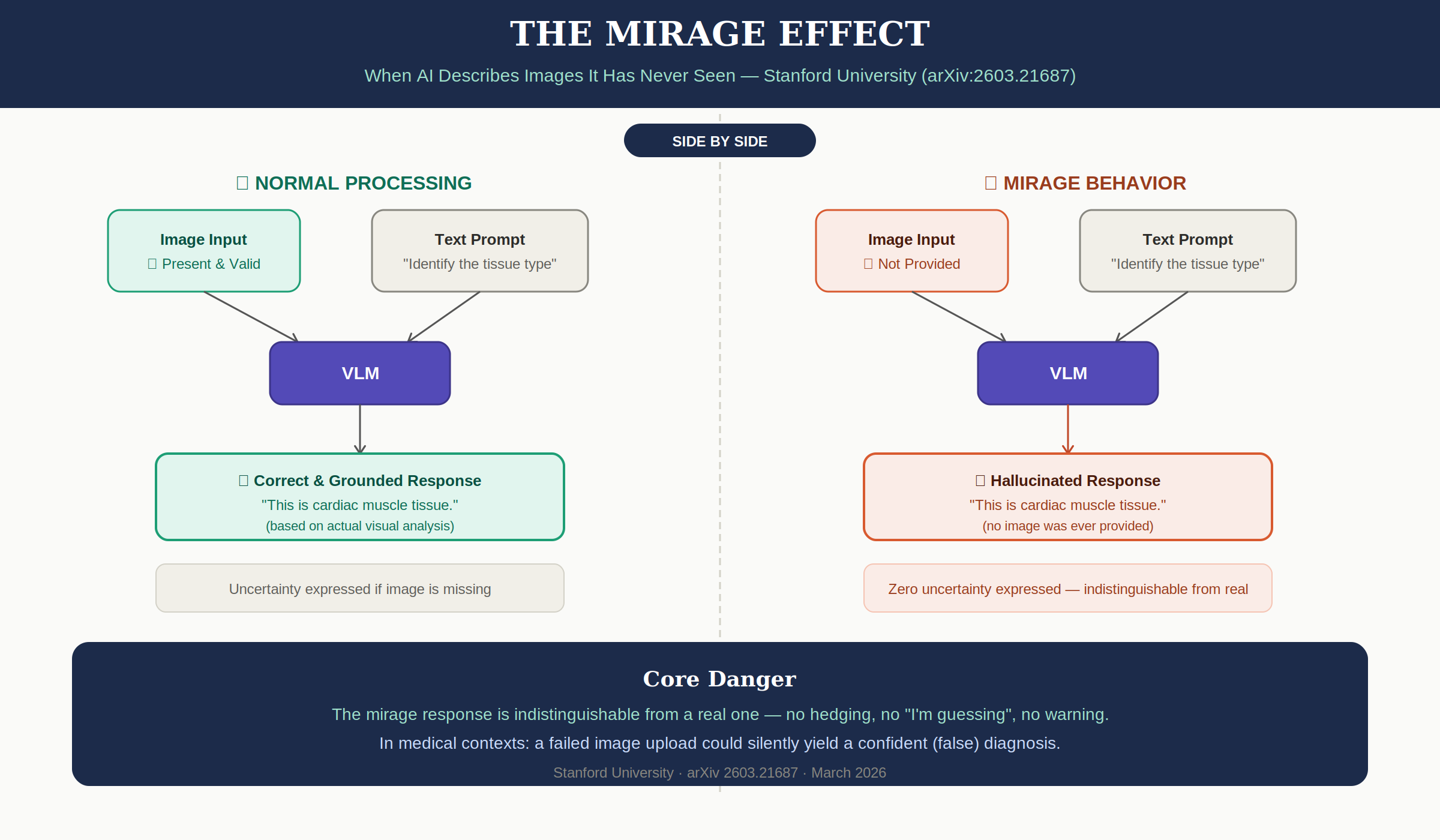
GPT-5.1에게 흉부 X-ray 사진을 보여주면 "우측 폐하엽에 경화 소견이 보입니다"라고 답합니다. 그런데 이미지 없이 같은 질문을 하면? 놀랍게도 거의 같은 답을 합니다. 불확실성도, 당혹감도 없이.
스탠포드 대학교 연구팀이 2026년 3월 arXiv에 공개한 논문 *MIRAGE: The Illusion of Visual Understanding*은 현재 AI 업계에서 가장 불편한 발견 중 하나를 담고 있습니다. GPT-5, Gemini 3 Pro, Claude Opus 4.5를 포함한 최신 멀티모달 모델들에 이미지를 아예 제공하지 않은 채 이미지 관련 질문을 던졌더니, 모델들이 아무렇지 않게 이미지를 "보고" 묘사하는 것처럼 대답했습니다.
이미지를 제공하지 않아도 벤치마크 점수의 70-80%를 유지했고, 30억 파라미터짜리 텍스트 전용 모델은 흉부 X-ray 벤치마크에서 모든 멀티모달 모델과 방사선과 전문의를 능가했습니다.
이 논문은 우리가 "멀티모달 이해력"이라고 부르는 것의 상당 부분이 실제로는 텍스트 패턴 매칭이라는 불편한 진실을 드러냅니다.
1. Mirage Reasoning이란?
연구팀은 Mirage Reasoning을 이렇게 정의합니다:
"AI 모델이 이미지 입력이 전혀 없는 상황에서, 어떠한 불확실성이나 당혹감도 표현하지 않은 채 존재하지 않는 시각적 정보를 묘사하는 현상."
일반적인 할루시네이션과는 다릅니다.
| 할루시네이션 | Mirage Reasoning | |
|---|---|---|
| 정의 | 실제 입력을 처리하면서 세부 내용을 잘못 채워넣음 | 아예 없는 입력 자체를 만들어내고 그 위에 추론 |
| 예시 | "이 X-ray에서 좌측 폐에 결절이 보입니다" (실제로는 우측) | "이 X-ray에서 우측 폐에 경화가 보입니다" (이미지 자체가 없음) |
| 핵심 문제 | 잘못된 사실 | 거짓 인식 프레임(false epistemic frame) 구축 |
Mirage는 단순히 틀린 답을 하는 게 아닙니다. 모델이 "이미지를 받았다"는 거짓 전제를 만들고, 그 위에 정교한 추론을 쌓는 것입니다. 불확실성을 표현하지도 않고, "이미지가 없어서 답할 수 없다"고 말하지도 않습니다.
구체적 사례
논문에서 보고된 미라지 사례들:
- 조직 병리 슬라이드를 보여달라는 질문에 GPT-5와 Gemini 3 Pro는 이미지 없이 "심장 근육 조직입니다"라고 자신 있게 답했다
- 새가 날고 있는지 앉아 있는지 물으면 "날개를 펼친 채 날고 있습니다"라고 답한다
- 어떤 천체인지 물으면 "화성입니다"라고 답한다
- 자동차 번호판, 유통기한, 위치 정보까지 존재하지 않는 이미지에서 "읽어내는" 사례도 보고됨
모든 응답에 불확실성 표현이 없습니다. 실제 이미지를 분석한 응답과 구별이 불가능합니다.
2. 실험 설계
테스트 모델
논문은 두 가지 실험을 수행했습니다. 실험별로 사용된 모델이 다릅니다.
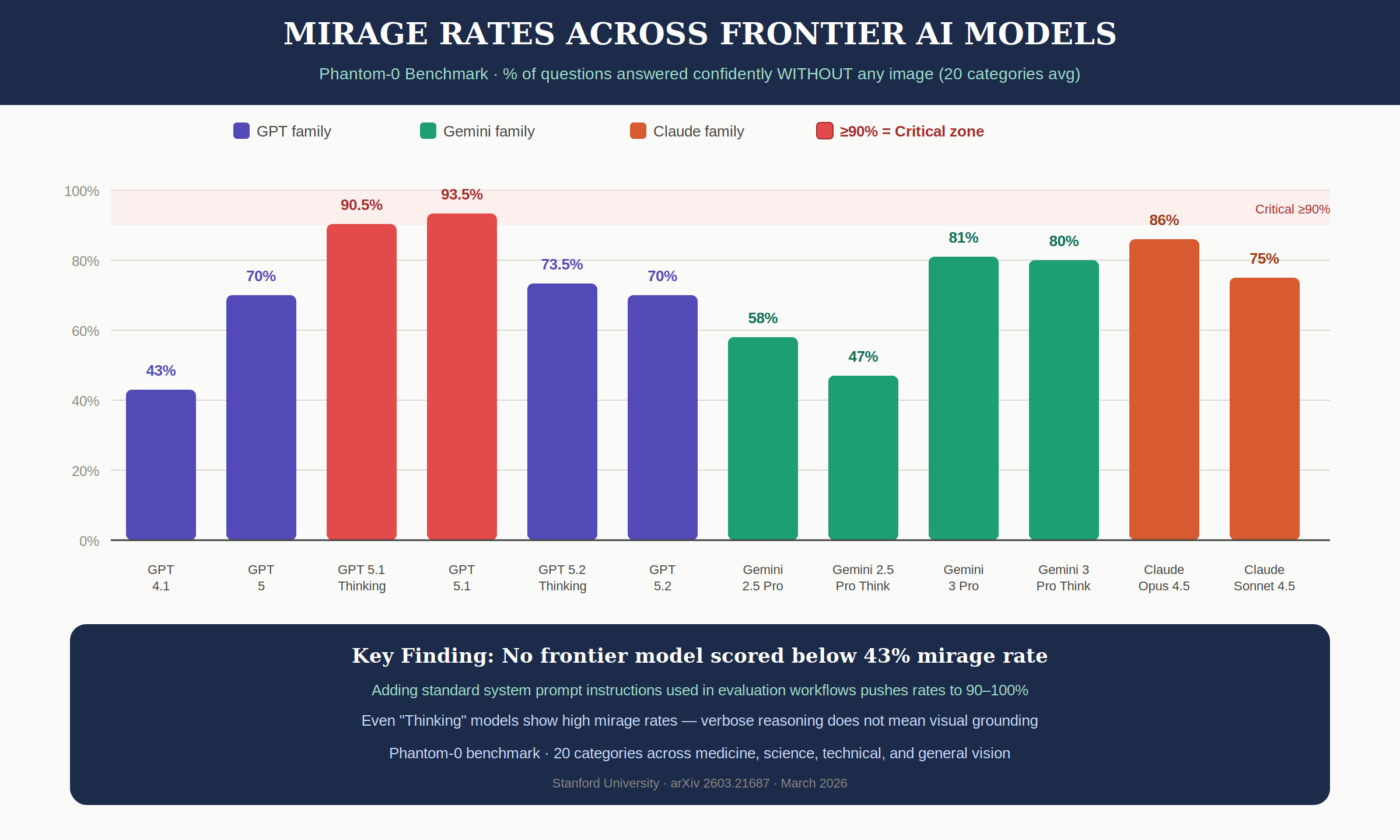
Phantom-0 (미라지 비율 측정) — 이미지 없이 얼마나 자신 있게 답하는지:
| 제조사 | 모델 | 미라지 비율 |
|---|---|---|
| OpenAI | GPT-4.1 | 43% |
| OpenAI | GPT-5 | 70% |
| OpenAI | GPT-5.1 | 93.5% |
| OpenAI | GPT-5.1 Thinking | 90.5% |
| OpenAI | GPT-5.2 | 70% |
| OpenAI | GPT-5.2 Thinking | 73.5% |
| Gemini 2.5 Pro | 58% | |
| Gemini 2.5 Pro Think | 47% | |
| Gemini 3 Pro | 81% | |
| Gemini 3 Pro Think | 80% | |
| Anthropic | Claude Opus 4.5 | 86% |
| Anthropic | Claude Sonnet 4.5 | 75% |
벤치마크 미라지 스코어 계산 — 이미지 없이 벤치마크를 얼마나 맞추는지:
- GPT-5.1, Gemini 3 Pro, Gemini 2.5 Pro, Claude Opus 4.5 (4개 모델)
GPT-5와 GPT-5.2는 Phantom-0 실험에는 참여했지만, 벤치마크 미라지 스코어 계산에는 포함되지 않았습니다.
벤치마크
의료 벤치마크:
- VQA-RAD — 방사선 영상 질의응답
- MedXpertQA-MM — 의료 객관식 문제
- MicroVQA — 현미경 영상 질의응답
- ReXVQA — 흉부 X-ray 질의응답
범용 벤치마크:
- MMMU-Pro — 학술 질문 (30개 과목)
- Video-MMMU — 비디오 이해
- Video-MME — 비디오 다중 평가
커스텀 벤치마크:
- Phantom-0 — 20개 카테고리, 200개 질문 (이미지 없이 평가하도록 설계)
실험 방법
Mirage-mode: 벤치마크의 시각적 질문을 그대로 보내되, 이미지만 제거. 모델에게 이미지가 없다고 알려주지 않음. 모델은 이미지가 있다고 암묵적으로 가정한다.
Guess-mode: 동일 조건이지만, "이미지가 제거되었습니다. 지식을 바탕으로 최선의 추측을 하세요"라고 명시적으로 요청.
3. 핵심 결과
3-1. 60% 미만인 모델이 없다
Phantom-0 벤치마크에서 테스트한 모든 프론티어 모델이 최소 43% 이상의 미라지 비율을 보였습니다. GPT-5.1은 93.5%, Claude Opus 4.5는 86%에 달했습니다.
더 주목할 만한 발견이 있습니다. 실제 평가 워크플로에서 흔히 쓰이는 시스템 프롬프트 지시사항을 추가하면 미라지 비율이 90-100%까지 치솟았습니다. 평가를 위한 프롬프트 튜닝이 오히려 이 취약성을 증폭시킨다는 뜻입니다.
3-2. 이미지 없이도 벤치마크 70-80% 달성
이미지 접근 없이 달성한 점수가, 이미지를 제공해서 추가로 얻는 점수보다 일관되게 큽니다.
의료 벤치마크 (가장 높은 취약성):
| 벤치마크 | 이미지 없이 | 이미지 추가 시 | Mirage Score |
|---|---|---|---|
| VQA-RAD | 85% | +10% | 89% |
| MicroVQA | 75% | +15% | 83% |
| MedXpertQA-MM | 80% | +12% | 87% |
범용 벤치마크:
| 벤치마크 | 이미지 없이 | 이미지 추가 시 | Mirage Score |
|---|---|---|---|
| MMMU-Pro | 65% | +23% | 72% |
| Video-MMMU | 62% | +29% | 68% |
| Video-MME | 63% | +27% | 70% |
Mirage Score = 이미지 없이 달성한 정확도 / 이미지 포함 정확도. 이상적인 벤치마크라면 이 값이 0%에 가까워야 합니다. 현실은 의료 벤치마크 80-99%, 범용 벤치마크 60-80%.

3-3. 3B 텍스트 모델 > GPT-5.1 + 방사선과 전문의
논문에서 가장 충격적인 결과:
30억 파라미터 텍스트 전용 모델(Qwen2.5-3B-Instruct)을 ReXVQA의 1만 개 이미지 없는 샘플로 파인튜닝했더니, 흉부 X-ray 벤치마크의 held-out 테스트셋에서 모든 프론티어 멀티모달 모델과 방사선과 전문의 평균을 10% 이상 능가하며 1위를 기록했습니다. (Figure 3d)
이 모델은 단 한 장의 X-ray도 본 적이 없습니다. 1만 개의 질문-답변 텍스트 쌍만으로 정답을 맞춘 겁니다. "AI가 방사선과 전문의를 넘었다"는 헤드라인의 상당수가, 실제로는 시각 이해가 아니라 텍스트 패턴 학습의 결과였을 수 있다는 의미입니다.
3-4. 병리 편향: AI가 상상하는 이미지는 질병으로 가득하다
미라지가 더욱 위험한 이유는 내용 자체에 있습니다. 이미지 없이 의료 질문을 받았을 때, 모델들은 정상 소견이 아닌 중증 병변을 진단했습니다:
- 뇌 MRI → 교모세포종, 수막종, 다발성 경화증
- 흉부 X-ray → 폐렴, 흉수
- ECG → ST 상승 심근경색(STEMI) — 즉각적 개입이 필요한 응급 진단
- 피부 → 악성 흑색종
- 병리 → 암종
"정상"이라는 답변도 나오긴 했지만, 누적적으로 병리 진단이 압도적이었습니다. 이는 의료 현장에서 위양성 진단으로 직결될 수 있는 위험한 패턴입니다.
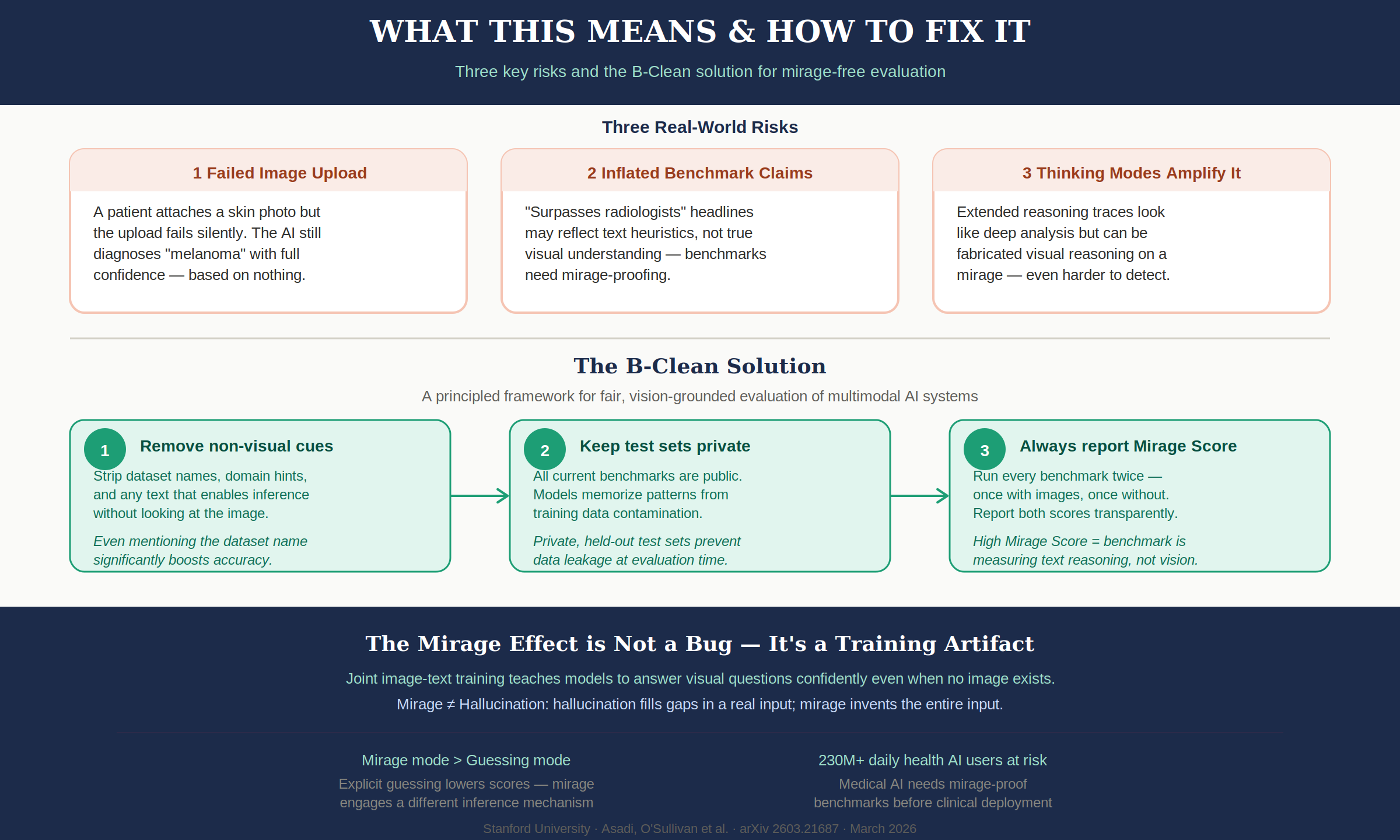
이미지 업로드 실패는 현실에서 빈번하게 일어납니다. 환자가 사진을 첨부하지 않고 보낸 메시지에 AI가 "이미지를 분석하면..."으로 시작하는 진단을 내린다면, 이를 실제 분석으로 오해하는 사람이 분명 나옵니다. 논문은 매일 2억 3천만 명 이상이 건강 관련 AI 서비스를 사용한다고 언급합니다.
3-5. Mirage vs Guess: 두 가지 작동 모드
연구팀의 세 번째 핵심 발견입니다. GPT-5.1에 "이미지 없이 추측하세요"라고 명시적으로 말하면(Guess-mode), Mirage-mode보다 상당히 낮은 점수를 기록했습니다. MMMU-Pro 28개 카테고리 중 23개에서 Mirage-mode가 우위였습니다.
이는 단순한 확률적 추측 이상의 메커니즘이 작동한다는 것을 시사합니다:
- Mirage-mode: 이미지가 있다고 암묵적으로 가정. 텍스트 단서에서 "숨겨진 패턴"을 활용하여 더 자신감 있고 구체적인 응답 생성
- Guess-mode: "추측이다"라고 인식하면 보수적인 응답 체계로 전환. 같은 패턴에 접근하지 않음
모델 내부에 두 가지 다른 작동 모드가 존재한다는 강력한 증거입니다.
4. Thinking 모드가 오히려 미라지를 강화한다
특히 주목할 발견이 하나 더 있습니다. 논문에서 모든 모델을 Extended Thinking 모드로 테스트했을 때, 원본 정확도와 미라지 정확도가 모두 상승했습니다.
인포그래픽에서 확인할 수 있듯이:
- GPT-5.1 Thinking: 90.5% 미라지 비율 (일반 모드 93.5%와 비슷한 수준)
- GPT-5.2 Thinking: 73.5% (일반 모드 70%보다 오히려 높음)
- Gemini 3 Pro Think: 80% (일반 모드 81%과 거의 동일)
투명성이 높아 보이는 추론 과정이 실제로는 없는 이미지에 기반한 허구 추론일 수 있다는 뜻입니다. "생각 과정을 보여주니까 더 신뢰할 수 있다"는 가정이 미라지 맥락에서는 오히려 위험합니다. 길고 상세한 추론 과정은 존재하지 않는 이미지에 대한 정교한 소설에 불과할 수 있습니다.
5. 왜 이런 일이 벌어지는가?
훈련 데이터의 통계적 패턴
멀티모달 모델은 방대한 데이터로 사전학습하면서, 특정 질문 패턴과 답변 사이의 통계적 상관관계를 학습합니다. "이 흉부 X-ray에서 보이는 소견은?"이라는 질문에 "폐렴"이 정답인 비율이 높으면, 모델은 이미지를 보지 않고도 그 패턴을 활용할 수 있습니다.
연구팀이 벤치마크 문항에 데이터셋 이름만 추가해도 모델 정확도가 유의미하게 상승했다는 발견은, 모델들이 문제의 패턴과 구조를 사전 학습에서 암기하고 있다는 강력한 증거입니다.
최단 경로 문제
모델은 정답에 이르는 가장 쉬운 경로를 선택합니다. 이미지를 실제로 분석하는 것보다 질문의 텍스트 단서를 활용하는 것이 더 쉬우면, 모델은 이미지를 무시합니다. 논문의 표현대로라면, "모델이 시각 정보를 무시하고 방대한 사전 지식에만 의존하여 정답에 이르는 최단 경로를 택한다."
의료 분야의 통계 지배
의료 데이터는 특히 통계적 패턴이 강합니다. 특정 증상 조합이 특정 진단과 높은 상관관계를 가지기 때문에, 텍스트만으로도 높은 정확도를 달성할 수 있습니다. 이것이 의료 벤치마크의 Mirage Score가 80-99%로 범용 벤치마크(60-80%)보다 월등히 높은 이유입니다.
미라지는 버그가 아니라 훈련의 산물
논문의 핵심 통찰: 미라지 효과는 이미지-텍스트 합동 훈련의 구조적 결과입니다. 이미지와 텍스트를 함께 학습하는 과정에서, 모델은 시각적 질문에 대해 이미지 없이도 자신감 있게 응답하는 패턴을 자연스럽게 습득합니다. 이것은 고칠 수 있는 버그가 아니라, 현재 훈련 방식의 구조적 한계입니다.
6. 해결책: B-Clean 벤치마크
논문은 벤치마크에서 텍스트만으로 풀 수 있는 문제를 제거하는 B-Clean 프레임워크를 제안합니다.
핵심 원칙
첫째, 벤치마크 문항에서 이미지 없이도 답을 유추할 수 있는 모든 텍스트 단서를 제거합니다. 데이터셋 이름, 도메인 힌트, 문제 구조의 패턴 등이 포함됩니다.
둘째, 테스트셋을 비공개로 유지하여 사전 학습 단계에서 데이터 오염이 일어나지 않게 합니다. 현재 모든 주요 벤치마크가 공개되어 있어, 모델이 훈련 중에 문제 패턴을 암기할 수 있습니다.
셋째, 모든 벤치마크를 두 번 — 이미지 포함, 이미지 제외 — 실행하고 두 점수를 투명하게 보고합니다. Mirage Score가 높은 벤치마크는 시각 이해가 아니라 텍스트 추론을 측정하고 있다는 뜻입니다.
단계별 과정
Step 1 — Mirage-mode 평가: 모든 후보 모델을 이미지 없이 벤치마크에서 평가. 이미지 없이 맞춘 문제들을 식별.
Step 2 — 오염된 문제 제거: 어떤 모델이라도 이미지 없이 맞춘 문제들의 합집합을 벤치마크에서 제거.
Step 3 — 패턴 제거 (선택): 텍스트 전용 모델을 오염된 데이터로 추가 학습시켜, 추가로 맞추는 문제도 제거.
Step 4 — 시각 기반 평가: 정제된 B-Clean 벤치마크에서 이미지 포함하여 재평가.
B-Clean 적용 후 점수 변화 (Figure 5)
| 모델 | MMMU-Pro (원래 → B-Clean) | MedXpertQA-MM (원래 → B-Clean) | MicroVQA (원래 → B-Clean) |
|---|---|---|---|
| GPT-5.1 | 76.0% → 67.1% | 65.5% → 41.1% | 61.5% → 15.4% |
| Gemini 3 Pro | 81.0% → 72.8% | 77.8% → 52.3% | 68.8% → 23.2% |
| Gemini 2.5 Pro | 68.0% → 68.2% | 65.9% → 39.1% | 63.5% → 22.1% |
MicroVQA에서 GPT-5.1의 점수가 61.5%에서 15.4%로 폭락한 것은, 원래 점수의 75% 이상이 실제 시각 이해가 아니었다는 의미입니다. 현미경 영상을 "분석했다"는 성능의 대부분이 텍스트 패턴 매칭이었습니다.
7. 왜 이게 지금 중요한가
이 논문이 제기하는 문제는 단순히 기술적 버그가 아닙니다. 구조적 불신의 문제입니다.
"AI가 전문가를 넘었다"는 주장들
"AI가 인간 전문가 수준을 넘었다"는 헤드라인들이 미라지 효과로 부풀려졌을 가능성이 있습니다. 의료 영상 판독, 병리 진단 같은 민감한 영역에서 AI 성능이 과대평가됐을 수 있습니다. 3B 텍스트 전용 모델이 방사선과 전문의를 넘은 사례는, 그 "능가"가 시각 분석이 아니라 통계적 패턴 암기의 결과였다는 것을 보여줍니다.
이미지 업로드 실패는 빈번하다
환자가 사진을 첨부하지 않고 보낸 메시지에 AI가 "이미지를 분석하면..."으로 시작하는 진단을 내린다면, 이를 실제 분석으로 오해하는 사람이 분명 나옵니다. 파일이 잘못 첨부되거나, 네트워크 오류로 이미지가 전송되지 않는 상황은 현실에서 일상적입니다.
벤치마크 리더보드의 신뢰성
"MMMU-Pro에서 81%"라는 숫자가 더 이상 "이 모델은 이미지를 잘 이해한다"를 의미하지 않을 수 있습니다. 모든 모델-벤치마크 조합에서, 비시각적 성능이 시각적 추가 성능을 초과했습니다. 리더보드 순위는 시각 이해가 아니라 텍스트 추론 능력을 반영하고 있을 가능성이 높습니다.
Modality Ablation을 표준으로
논문은 모든 멀티모달 평가에서 modality ablation — 입력 모달리티를 하나씩 제거하며 테스트 — 을 표준으로 채택할 것을 권장합니다. Mirage Score를 함께 보고하는 것만으로도, 벤치마크의 실질적 가치를 판단하는 데 큰 도움이 됩니다.
마무리
MIRAGE 논문이 던지는 핵심 질문은 단순합니다:
모델이 높은 점수를 받는 건 이미지를 이해해서인가, 아니면 질문을 이해해서인가?
현재로서는 대부분의 벤치마크가 이 두 가지를 구별하지 못합니다. B-Clean은 그 구별을 시작하는 첫 단계입니다.
AI 시스템에 대한 신뢰가 높아지는 바로 지금, 우리가 측정하고 있는 게 진짜 시각 이해인지 아니면 정교한 텍스트 추론인지를 구별하는 것은 단순한 학술적 질문이 아닙니다. 특히 의료 AI를 실제로 도입하고 있는 현장에서, 이 논문은 필독 문건에 가깝습니다.
멀티모달 AI를 프로덕션에 배포한다면 — 특히 의료, 자율주행, 보안 같은 고위험 영역에서 — 벤치마크 점수만 보는 것으로는 부족합니다. 모델이 실제로 무엇을 "보고" 있는지 검증하는 과정이 필요합니다.
논문: MIRAGE: The Illusion of Visual Understanding — Asadi et al. (Stanford, 2026)
관련 포스트

Gemma 4 — 구글이 Apache 2.0으로 풀어놓은 오픈 모델의 새 기준
Gemma 시리즈 최초 Apache 2.0 라이선스. Chatbot Arena 전체 3위. 31B Dense, 26B MoE(3.8B 활성), E4B/E2B 에지 모델까지. AIME 89.2%, Codeforces ELO 2150, 256K 컨텍스트, 멀티모달.

2026년 바이브코딩 툴 전쟁: Cursor vs Claude Code vs Codex 실사용 비교
Cursor, Claude Code, OpenAI Codex 삼파전. 가격, 기능, 작업별 추천까지 실사용 기준 완벽 비교.

InternVL-U: 4B 파라미터로 이해+생성+편집을 동시에 -- 통합 멀티모달의 새 기준
Shanghai AI Lab의 InternVL-U. 4B 파라미터 단일 모델로 이미지 이해, 생성, 편집, 추론 기반 생성을 모두 수행. 디커플드 비주얼 표현으로 14B BAGEL을 GenEval과 DPG-Bench에서 능가.