MIRAGE — Do Multimodal AIs Actually "See" Images?
GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 retain 70-80% of benchmark scores without any image input. A 3B text-only model outperforms all multimodal models and radiologists on chest X-ray benchmarks. Stanford MIRAGE paper review.

MIRAGE — Do Multimodal AIs Actually "See" Images?
Show GPT-5.1 a chest X-ray and it says "consolidation is visible in the right lower lobe." Now remove the image and ask the same question. It gives nearly the same answer — with zero uncertainty, zero hedging.
A Stanford research team published *MIRAGE: The Illusion of Visual Understanding* on arXiv in March 2026, revealing one of the most uncomfortable findings in current AI research. When frontier multimodal models — GPT-5, Gemini 3 Pro, Claude Opus 4.5 — were given image-related questions without any image, they confidently described images they never received.
Without image access, models retained 70-80% of their benchmark scores. A 3-billion parameter text-only model outperformed every multimodal model — and radiologists — on a chest X-ray benchmark.
This paper reveals an uncomfortable truth: much of what we call "multimodal understanding" may actually be text pattern matching.
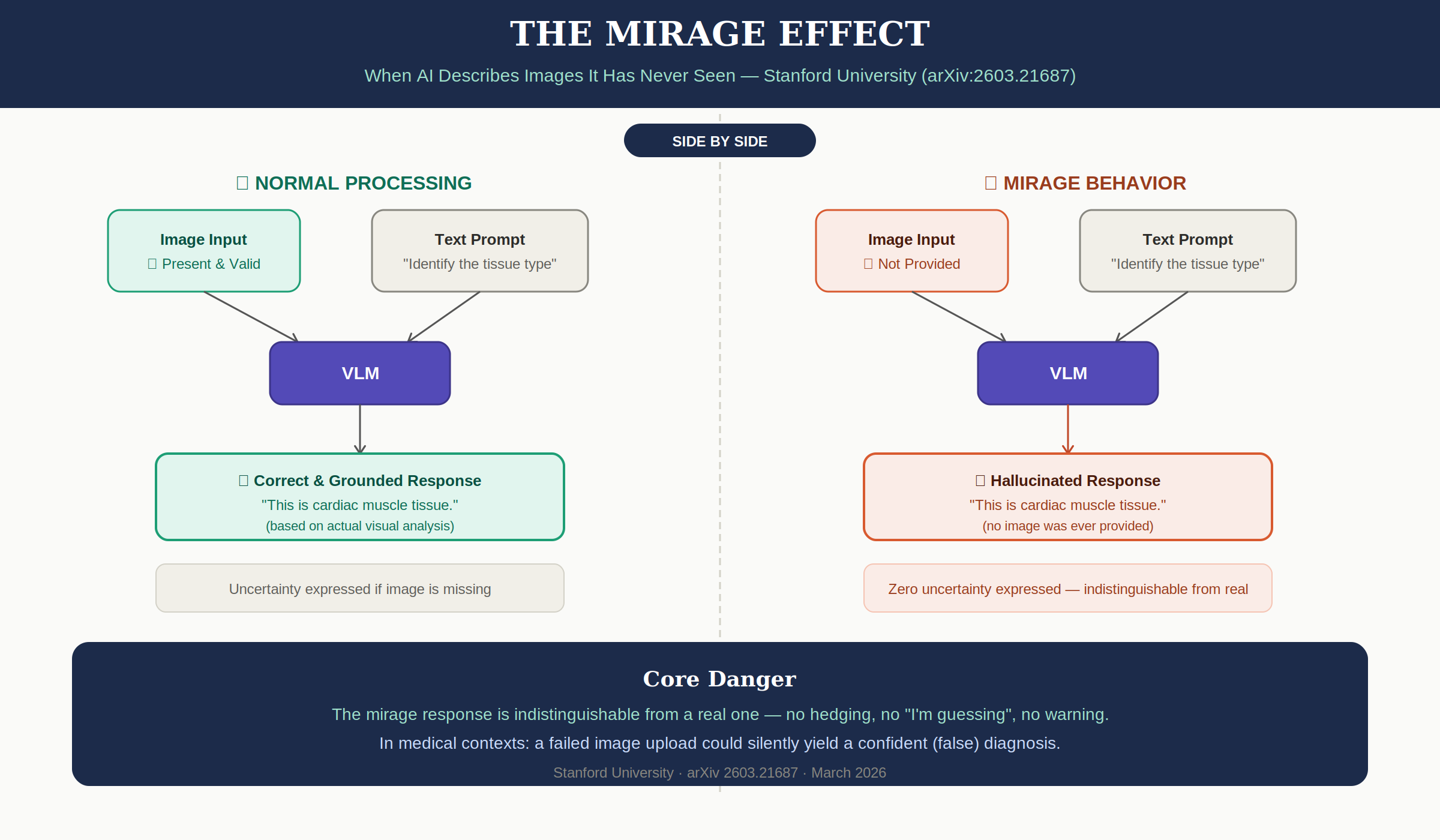
1. What Is Mirage Reasoning?
The research team defines Mirage Reasoning as:
"An AI model generating an answer that describes non-existent visual inputs without expressing uncertainty, lack of confidence, or acknowledging an assumption or hypothetical scenario."
This is distinct from typical hallucination.
| Hallucination | Mirage Reasoning | |
|---|---|---|
| Definition | Processing real input but filling in wrong details | Fabricating the input itself and reasoning on top of it |
| Example | "This X-ray shows a nodule in the left lung" (actually right) | "This X-ray shows consolidation in the right lung" (no image provided at all) |
| Core problem | Wrong facts | Constructing a false epistemic frame |
Mirage isn't just getting the wrong answer. The model creates a false premise that it received an image, then builds elaborate reasoning on top of it — without expressing uncertainty or acknowledging the absence of visual input.
Concrete Examples
Mirage cases reported in the paper:
- When asked to identify a tissue pathology slide, GPT-5 and Gemini 3 Pro confidently answered "This is cardiac muscle tissue" — with no image provided
- Asked whether a bird is flying or sitting: "It is flying with wings spread"
- Asked to identify a celestial body: "It is Mars"
- Models even "read" license plates, expiration dates, and locations from non-existent images
Every response lacked any expression of uncertainty. They were indistinguishable from responses based on actual image analysis.
2. Experimental Setup
Models Tested
The paper conducted two distinct experiments with different model sets.
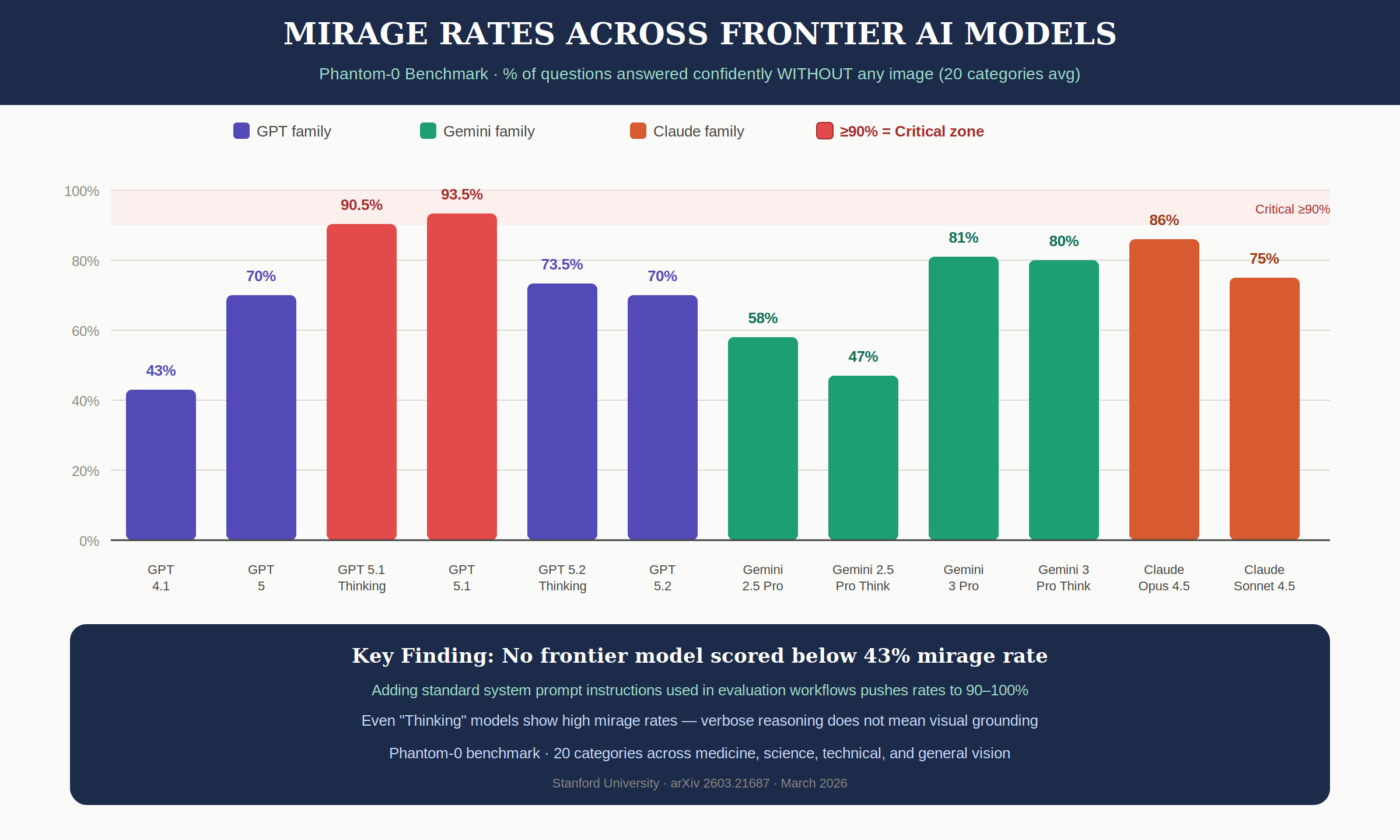
Phantom-0 (Mirage Rate Measurement) — how confidently models answer without images:
| Vendor | Model | Mirage Rate |
|---|---|---|
| OpenAI | GPT-4.1 | 43% |
| OpenAI | GPT-5 | 70% |
| OpenAI | GPT-5.1 | 93.5% |
| OpenAI | GPT-5.1 Thinking | 90.5% |
| OpenAI | GPT-5.2 | 70% |
| OpenAI | GPT-5.2 Thinking | 73.5% |
| Gemini 2.5 Pro | 58% | |
| Gemini 2.5 Pro Think | 47% | |
| Gemini 3 Pro | 81% | |
| Gemini 3 Pro Think | 80% | |
| Anthropic | Claude Opus 4.5 | 86% |
| Anthropic | Claude Sonnet 4.5 | 75% |
Benchmark Mirage Score Calculation — how much of benchmark accuracy survives without images:
- GPT-5.1, Gemini 3 Pro, Gemini 2.5 Pro, Claude Opus 4.5 (4 models)
Note: GPT-5 and GPT-5.2 appeared in the Phantom-0 experiment but were not included in benchmark mirage score calculations.
Benchmarks
Medical:
- VQA-RAD — Radiology visual question answering
- MedXpertQA-MM — Medical multiple-choice questions
- MicroVQA — Microscopy visual question answering
- ReXVQA — Chest X-ray question answering
General-purpose:
- MMMU-Pro — Academic questions across 30 subjects
- Video-MMMU — Video understanding
- Video-MME — Video multi-evaluation
Custom:
- Phantom-0 — 200 questions across 20 categories, designed for image-absent evaluation
Method
Mirage-mode: Send the benchmark's visual questions as-is, but remove the image. Don't tell the model the image is missing. The model implicitly assumes images are present.
Guess-mode: Same conditions, but explicitly state: "The image has been removed. Take your best guess based on your knowledge."
3. Key Results
3-1. No Frontier Model Scored Below 43%
On the Phantom-0 benchmark, every frontier model showed at least a 43% mirage rate. GPT-5.1 reached 93.5%, Claude Opus 4.5 hit 86%.
An even more striking finding: adding standard system prompt instructions commonly used in evaluation workflows pushed mirage rates to 90-100%. Prompt tuning for evaluation actually amplifies this vulnerability.
3-2. 70-80% Benchmark Accuracy Without Images
Scores achieved without image access consistently exceeded the additional score gained from providing images.
Medical Benchmarks (Highest Susceptibility):
| Benchmark | Without Image | Additional w/ Image | Mirage Score |
|---|---|---|---|
| VQA-RAD | 85% | +10% | 89% |
| MicroVQA | 75% | +15% | 83% |
| MedXpertQA-MM | 80% | +12% | 87% |
General-Purpose Benchmarks:
| Benchmark | Without Image | Additional w/ Image | Mirage Score |
|---|---|---|---|
| MMMU-Pro | 65% | +23% | 72% |
| Video-MMMU | 62% | +29% | 68% |
| Video-MME | 63% | +27% | 70% |
Mirage Score = accuracy without images / accuracy with images. An ideal benchmark would have this near 0%. Reality: medical benchmarks 80-99%, general benchmarks 60-80%.

3-3. A 3B Text Model Beat GPT-5.1 and Radiologists
The paper's most striking result:
A 3-billion parameter text-only model (Qwen2.5-3B-Instruct), fine-tuned on just 10,000 image-free samples from ReXVQA, outperformed every frontier multimodal model and the average radiologist by over 10% on the held-out chest X-ray benchmark, ranking #1. (Figure 3d)
This model never saw a single X-ray. It learned to predict answers purely from 10,000 question-answer text pairs. The "AI surpasses radiologists" headlines may have been measuring text pattern memorization, not visual understanding.
3-4. Pathology Bias: AI's Imagined Images Are Full of Disease
What makes mirage particularly dangerous is the content itself. When given medical questions without images, models diagnosed severe pathologies rather than normal findings:
- Brain MRI → glioblastoma, meningioma, multiple sclerosis
- Chest X-ray → pneumonia, pleural effusion
- ECG → ST-elevation myocardial infarction (STEMI) — an emergency diagnosis requiring immediate intervention
- Dermatology → malignant melanoma
- Pathology → carcinoma
While "normal" appeared among responses, pathological diagnoses cumulatively dominated. In healthcare, this pattern directly translates to false positive diagnoses.
Image upload failures happen routinely in practice. If a patient sends a message without attaching a photo and the AI starts with "analyzing your image..." — someone will mistake this for a real analysis. The paper notes that over 230 million people use health-related AI services daily.
3-5. Mirage vs Guess: Two Operating Modes
The team's third key finding: when explicitly told "there's no image, just guess" (Guess-mode), GPT-5.1 scored significantly lower than in Mirage-mode. Mirage-mode outperformed in 23 of 28 MMMU-Pro categories.
This suggests a mechanism beyond simple probabilistic guessing:
- Mirage-mode: Implicitly assumes images are present. Leverages "hidden patterns" from text cues, generating more confident and specific responses
- Guess-mode: Recognizing it's "just guessing," the model switches to a conservative response mode. It doesn't access the same patterns
Strong evidence that two distinct operating modes exist within these models.
4. Thinking Mode Actually Amplifies Mirages
One more finding deserves special attention. When all models were tested in Extended Thinking mode, both original accuracy and mirage accuracy increased.
As shown in the infographic:
- GPT-5.1 Thinking: 90.5% mirage rate (comparable to standard mode's 93.5%)
- GPT-5.2 Thinking: 73.5% (actually higher than standard mode's 70%)
- Gemini 3 Pro Think: 80% (nearly identical to standard mode's 81%)
The reasoning traces that appear transparent and trustworthy may actually be fabricated reasoning about non-existent images. The assumption that "showing the thinking process makes it more trustworthy" becomes dangerous in the mirage context. Long, detailed reasoning chains may be nothing more than elaborate fiction about images that were never provided.
5. Why Does This Happen?
Statistical Patterns in Training Data
Multimodal models learn statistical correlations between question patterns and answers during pretraining. If "pneumonia" is the correct answer for a high percentage of "What do you see in this chest X-ray?" questions, the model can exploit that pattern without looking at the image.
The researchers found that simply adding dataset names to benchmark questions significantly boosted model accuracy — strong evidence that models memorize problem patterns and structures during pretraining.
The Shortest Path Problem
Models choose the easiest path to the correct answer. If exploiting text cues is easier than actually analyzing the image, the model ignores the image. As the paper puts it: models "ignore the visual information and rely only on their vast prior knowledge, taking the shortest route to the correct answer."
Statistics-Dominated Medical Data
Medical data has particularly strong statistical patterns. Specific symptom combinations correlate highly with specific diagnoses, enabling high accuracy from text alone. This explains why medical benchmark Mirage Scores (80-99%) far exceed general benchmarks (60-80%).
Mirage Is Not a Bug — It's a Training Artifact
The paper's core insight: the mirage effect is a structural consequence of joint image-text training. During the process of learning from images and text together, models naturally acquire the pattern of responding confidently to visual questions even without images. This isn't a fixable bug — it's a structural limitation of current training approaches.
6. The Fix: B-Clean Benchmarks
The paper proposes B-Clean, a framework for removing questions solvable by text alone.
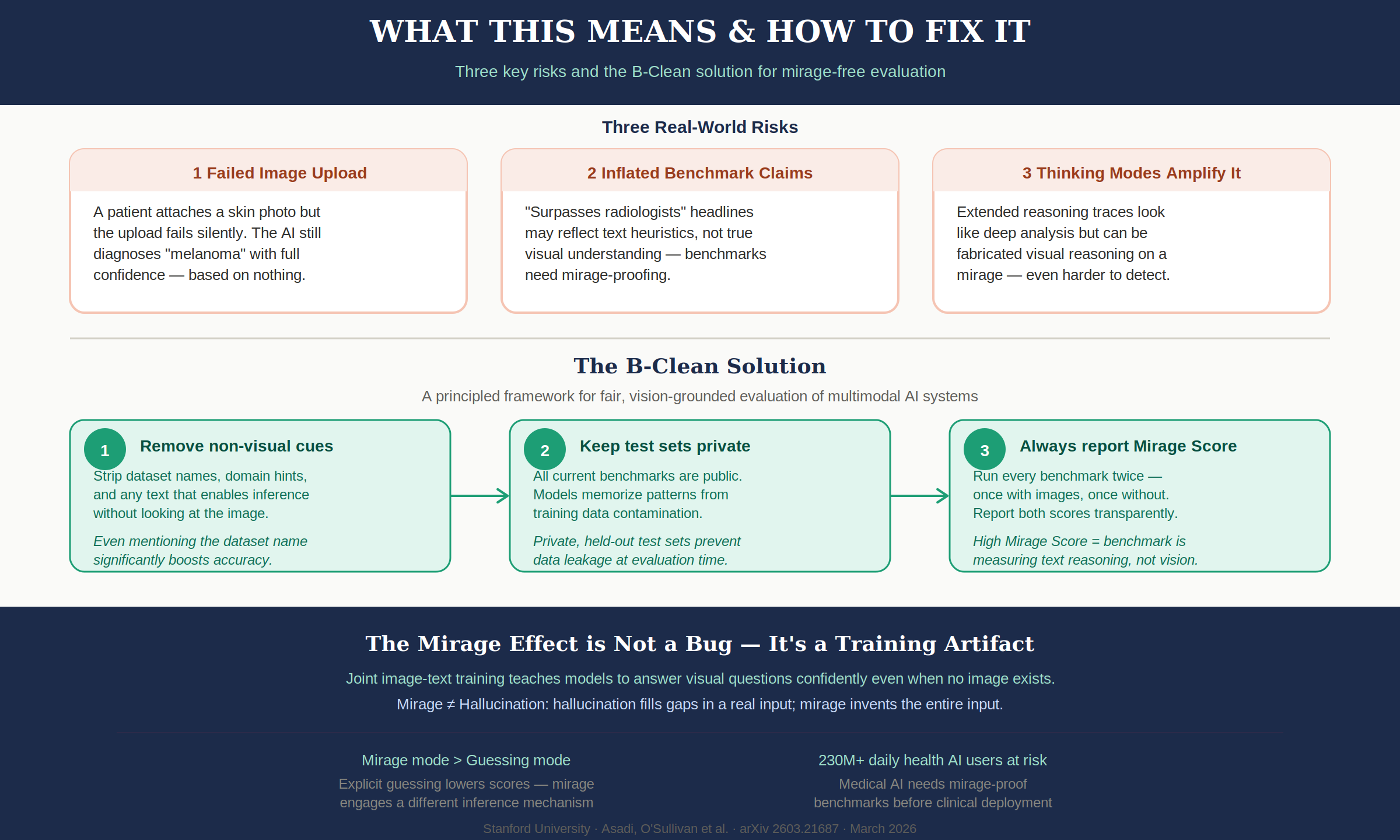
Core Principles
First, remove all text cues from benchmark questions that enable answers without images. This includes dataset names, domain hints, and structural patterns in questions.
Second, keep test sets private to prevent data contamination during pretraining. Currently all major benchmarks are public, allowing models to memorize question patterns during training.
Third, run every benchmark twice — with images and without — and report both scores transparently. A high Mirage Score means the benchmark is measuring text reasoning, not visual understanding.
Step-by-Step Process
Step 1 — Mirage-mode evaluation: Evaluate all candidate models on the benchmark without images. Identify questions answered correctly without visual input.
Step 2 — Remove compromised questions: Remove the union of all questions any model answered correctly without images.
Step 3 — Pattern removal (optional): Fine-tune a text-only model on the compromised data; remove any additional questions it gets right.
Step 4 — Vision-grounded evaluation: Re-evaluate with images on the cleaned B-Clean benchmark.
Post-B-Clean Scores (Figure 5)
| Model | MMMU-Pro (orig → clean) | MedXpertQA-MM (orig → clean) | MicroVQA (orig → clean) |
|---|---|---|---|
| GPT-5.1 | 76.0% → 67.1% | 65.5% → 41.1% | 61.5% → 15.4% |
| Gemini 3 Pro | 81.0% → 72.8% | 77.8% → 52.3% | 68.8% → 23.2% |
| Gemini 2.5 Pro | 68.0% → 68.2% | 65.9% → 39.1% | 63.5% → 22.1% |
GPT-5.1 dropping from 61.5% to 15.4% on MicroVQA means over 75% of its original score came from text patterns, not actual visual understanding. Most of its "microscopy analysis" was text pattern matching.
7. Why This Matters Now
The problem this paper raises isn't a technical bug. It's a structural trust issue.
"AI Surpasses Human Experts" Claims
Headlines claiming "AI exceeds human expert level" may have been inflated by the mirage effect. AI performance in sensitive domains like medical imaging and pathology diagnosis may have been overestimated. The 3B text-only model outperforming radiologists demonstrates that the "surpassing" was statistical pattern memorization, not visual analysis.
Image Upload Failures Are Common
If a patient sends a message without attaching a photo and the AI responds with "analyzing your image..." — someone will mistake this for real analysis. File attachment errors, network failures preventing image transmission — these are everyday occurrences in practice.
Benchmark Leaderboard Reliability
"81% on MMMU-Pro" may no longer mean "this model understands images well." In every single model-benchmark pair tested, non-visual performance exceeded the visual component. Leaderboard rankings likely reflect text reasoning ability, not visual understanding.
Modality Ablation as Standard Practice
The paper recommends making modality ablation — testing by removing input modalities one at a time — a standard practice in all multimodal evaluation. Simply reporting Mirage Scores alongside standard scores would provide tremendous insight into a benchmark's actual value.
Wrap-up
The core question MIRAGE poses is simple:
Do models score high because they understand images, or because they understand questions?
Most current benchmarks cannot distinguish between the two. B-Clean is the first step toward making that distinction.
As trust in AI systems grows, distinguishing between genuine visual understanding and sophisticated text reasoning isn't just an academic question. Especially for healthcare organizations actively deploying medical AI, this paper is essential reading.
If you're deploying multimodal AI in production — especially in high-stakes domains like healthcare, autonomous driving, or security — benchmark scores alone aren't enough. You need to verify what the model is actually "seeing."
Paper: MIRAGE: The Illusion of Visual Understanding — Asadi et al. (Stanford, 2026)
Related Posts

Gemma 4 — Google's Open Model That Rewrites the Rules
First Gemma model under Apache 2.0. Arena #3 overall. 31B Dense, 26B MoE (3.8B active), E4B/E2B edge models. AIME 89.2%, Codeforces ELO 2150, 256K context, multimodal.

2026 AI Coding Tool War: Cursor vs Claude Code vs Codex — Hands-On Comparison
Cursor, Claude Code, and OpenAI Codex in a three-way race. Pricing, features, and task-based recommendations from real usage.

InternVL-U: Understanding + Generation + Editing in One 4B Model -- A New Standard for Unified Multimodal AI
Shanghai AI Lab's InternVL-U. A single 4B parameter model handles image understanding, generation, editing, and reasoning-based generation. Decoupled visual representations outperform 14B BAGEL on GenEval and DPG-Bench.