Claude Sonnet 4.6: Opus-Level Performance, 40% Cheaper — Benchmark Deep Dive
Claude Sonnet 4.6 scores 79.6% on SWE-bench, 72.5% on OSWorld, and 1633 Elo on GDPval-AA — matching or beating Opus 4.6 on production tasks. $3/$15 vs $5/$25 per M tokens. Analysis of Adaptive Thinking, Context Compaction, and OSWorld growth trajectory.
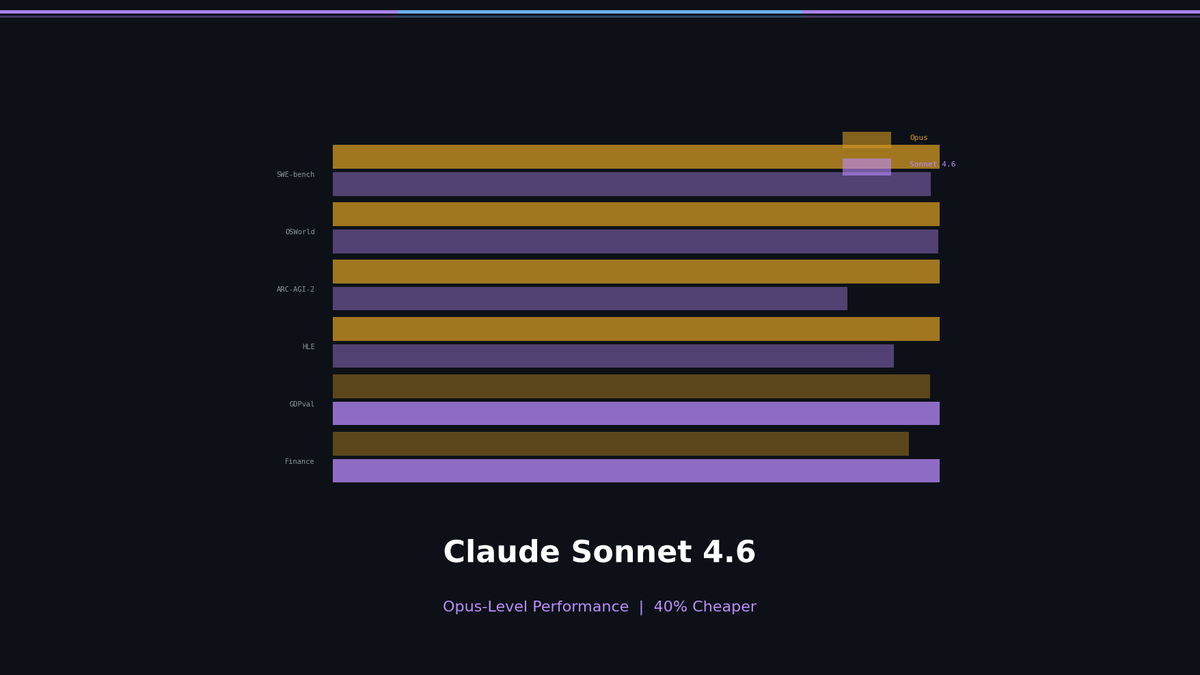
Did Sonnet Just Beat Opus? — Claude Sonnet 4.6 Benchmark Deep Dive
Anthropic released Claude Sonnet 4.6 on February 17, and it outperforms the flagship Opus 4.6 on several key benchmarks. At roughly 40% less cost. The secret isn't a "cheaper knock-off" — it's architectural-level structural changes.
Opus vs Sonnet: What Changed?
The old Opus-Sonnet dynamic was straightforward. Opus was the full-spec brain; Sonnet was the compressed version. Same architecture, smaller size, naturally lower performance.
In the 4.6 generation, that formula breaks.
Where Sonnet Wins or Ties
| Benchmark | Sonnet 4.6 | Opus 4.6 | Gap |
|---|---|---|---|
| SWE-bench Verified (Coding) | 79.6% | 80.8% | 1.2%p (Tied) |
| OSWorld Verified (Computer Use) | 72.5% | 72.7% | Effectively tied |
| GDPval-AA (Knowledge Work, Elo) | 1633 | 1606 | Sonnet wins |
| Finance Agent (Agentic Finance, Vals AI) | 63.30% | 60.05% | Sonnet wins |
In coding and agentic tasks, Sonnet matches or beats Opus. At $3/$15 per M tokens.
Where Opus Clearly Wins
| Benchmark | Sonnet 4.6 | Opus 4.6 | Gap |
|---|---|---|---|
| ARC-AGI-2 (Abstract Reasoning) | 58.3% | 68.8% | Opus leads significantly |
| HLE without Tools (Hard Problems) | 33.2% | 40.0% | Opus wins |
| HLE with Tools | 49.0% | 53.0% | Opus wins |
| MRCR v2 1M (Long Context) | — | 76% | Ref: Sonnet 4.5 = 18.5% |
See the pattern? Opus decisively wins on reasoning depth and ultra-long context accuracy.
Here's an analogy: Sonnet 4.6 is a student who scores perfect on the SAT. Within defined boundaries, it executes near-flawlessly. Opus 4.6 is an International Math Olympiad gold medalist. The gap emerges on novel problems that require chaining multiple concepts.
Most real-world coding, document work, and agentic tasks fall within "SAT territory." Opus is only necessary for research-grade tasks requiring novel reasoning.
The Evolution of Computer Use
The individual benchmark numbers aren't the real story.
Look at the OSWorld benchmark trajectory:
| Model | Date | OSWorld |
|---|---|---|
| Sonnet 3.5 | Oct 2024 | 14.9% |
| Sonnet 3.7 | Feb 2025 | 28.0% |
| Sonnet 4.0 | Jun 2025 | 42.2% |
| Sonnet 4.5 | Oct 2025 | 61.4% |
| Sonnet 4.6 | Feb 2026 | 72.5% |
5x improvement in 16 months. Roughly 10-15 percentage points every three months.
If this curve holds, it crosses 90% within the year. "AI operating a computer like a human" becomes reality in 2026. Mouse clicks, drag-and-drop, form filling, file management — all performed directly by AI.
Adaptive Thinking: Automatic Reasoning Depth Control
Previous Extended Thinking always went deep. Even simple questions consumed tokens through excessive reasoning.
Adaptive Thinking auto-adjusts across 4 levels: low, medium, high, and max.
| Level | Use Case | Example |
|---|---|---|
| low | Quick-answer questions | "What's the weather in Seoul?" |
| medium | General analysis, translation | "Translate this email to Korean" |
| high | Complex debugging, architecture | "Refactor this codebase" |
| max | Research-grade problems | "Analyze methodological flaws in this paper" |
It's like how humans adjust thinking time based on problem difficulty. Same quality output, fewer tokens burned.
For developers, the key insight: the budget_tokens parameter lets you cap reasoning per request — "think this much and no more." Cost predictability is now possible.
Context Compaction: The Most Underrated Feature
The 1M token context window existed before, but the problem was "Lost-in-the-middle." Feeding a million tokens is pointless if the model forgets what's in the middle.
Context Compaction automatically summarizes older context server-side. It preserves key information while saving tokens.
Why does this matter? It could fundamentally change RAG pipeline design.
- Before: Document -> Chunking -> Embedding -> Vector DB -> Reranking -> LLM (5-stage pipeline)
- With 4.6: Document -> LLM (1 stage, Compaction handles the rest)
Of course, 1M context is still in beta and only accessible at Usage Tier 4+. Opus scored 76% on MRCR v2, but Sonnet 4.6's score hasn't been published yet. This part needs verification.
When Opus, When Sonnet?
Synthesizing these benchmarks, the conclusion is clear.
Default to Sonnet 4.6
- Coding, debugging, code review (SWE-bench 79.6%)
- Data analysis, documentation, knowledge work (GDPval-AA 1633 Elo)
- Agent workflows, tool use (Finance Agent 63.3%)
- Direct computer operation (OSWorld 72.5%)
- Price: $3 input / $15 output per M tokens
Use Opus 4.6 Only When
- Solving truly novel problems (ARC-AGI-2 68.8%)
- Olympiad-grade reasoning required (HLE 53.0%)
- Finding needles in million-token haystacks (MRCR v2 76%)
- Price: $5 input / $25 output per M tokens
If you're a developer, switch your default stack to Sonnet 4.6 and reserve Opus for reasoning-heavy nodes only. Same budget, ~1.67x more throughput.
Key Takeaways
Sonnet 4.6 isn't a "budget Opus." It's an optimized-for-production model. It matches or exceeds Opus on coding, agentic tasks, and knowledge work — at ~40% lower cost. The only time you need Opus is when the problem is genuinely novel.
| Category | Sonnet 4.6 | Opus 4.6 |
|---|---|---|
| Price (input/output) | $3/$15 per M | $5/$25 per M |
| Coding (SWE-bench) | 79.6% | 80.8% |
| Computer Use (OSWorld) | 72.5% | 72.7% |
| Knowledge Work (GDPval-AA) | 1633 Elo | 1606 Elo |
| Abstract Reasoning (ARC-AGI-2) | 58.3% | 68.8% |
| Hard Problems (HLE w/ Tools) | 49.0% | 53.0% |
| Recommended Use | All daily work | Research-grade reasoning |
Sources: Anthropic Official Blog, Anthropic System Card, SWE-bench, OSWorld, ARC-AGI-2, Vals AI, Artificial Analysis
Subscribe to Newsletter
Related Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.

MIRAGE — Do Multimodal AIs Actually "See" Images?
GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 retain 70-80% of benchmark scores without any image input. A 3B text-only model outperforms all multimodal models and radiologists on chest X-ray benchmarks. Stanford MIRAGE paper review.

AgentScope vs LangGraph vs CrewAI — 2026 Multi-Agent Framework Comparison
Full comparison of AgentScope (Alibaba), LangGraph (LangChain), and CrewAI with real data and code examples. Architecture, LLM support, multimodal, memory, and production deployment.