Claude Sonnet 4.6: Opus급 성능, 40% 저렴 — 벤치마크 심층 분석
Claude Sonnet 4.6은 SWE-bench 79.6%, OSWorld 72.5%, GDPval-AA 1633 Elo로 실무 태스크에서 Opus 4.6과 동급이거나 우위. $3/$15 vs $5/$25. Adaptive Thinking, Context Compaction, OSWorld 성장 추이 분석.
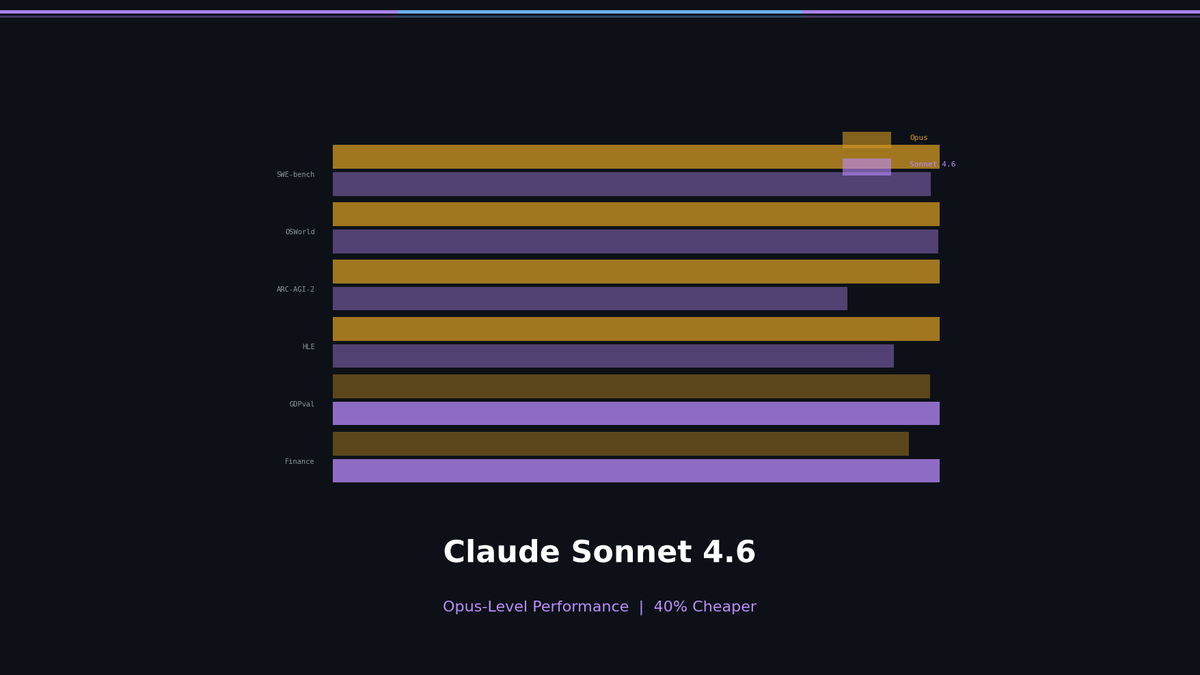
Sonnet이 Opus를 이겼다? — Claude Sonnet 4.6 벤치마크 심층 분석
Anthropic이 2월 17일 공개한 Claude Sonnet 4.6가 특정 벤치마크에서 플래그십 모델 Opus 4.6를 능가하는 결과가 나왔습니다. 가격은 약 40% 저렴. 비결은 '싸게 만든 열화판'이 아니라, 아키텍처 레벨의 구조 변경에 있습니다.
Opus vs Sonnet, 뭐가 달랐나?
기존의 Opus-Sonnet 관계는 명확했습니다. Opus는 '풀스펙 두뇌', Sonnet은 '경량화 두뇌'. 같은 아키텍처를 압축하니 당연히 성능이 깎였죠.
4.6 세대에서 이 공식이 깨집니다.
Sonnet이 이기거나 동급인 영역
| 벤치마크 | Sonnet 4.6 | Opus 4.6 | 차이 |
|---|---|---|---|
| SWE-bench Verified (코딩) | 79.6% | 80.8% | 1.2%p (동급) |
| OSWorld Verified (컴퓨터 사용) | 72.5% | 72.7% | 사실상 동률 |
| GDPval-AA (지식 업무, Elo) | 1633 | 1606 | Sonnet 승 |
| Finance Agent (에이전틱 금융, Vals AI) | 63.30% | 60.05% | Sonnet 승 |
코딩과 에이전트 태스크에서 Sonnet이 Opus와 동급이거나 이기고 있습니다. $3/$15 per M tokens으로.
Opus가 확실히 이기는 영역
| 벤치마크 | Sonnet 4.6 | Opus 4.6 | 차이 |
|---|---|---|---|
| ARC-AGI-2 (추상 추론) | 58.3% | 68.8% | Opus 크게 앞섬 |
| HLE 툴 없이 (난문제) | 33.2% | 40.0% | Opus 승 |
| HLE 툴 포함 | 49.0% | 53.0% | Opus 승 |
| MRCR v2 1M (롱컨텍스트) | — | 76% | 비교: Sonnet 4.5 = 18.5% |
패턴이 보이시나요? Opus가 확실히 이기는 건 '추론 깊이'와 '초장문 컨텍스트 정확도'입니다.
비유하자면 이렇습니다. Sonnet 4.6은 수능 만점자입니다. 정해진 범위 내에서는 거의 완벽하게 풀어냅니다. Opus 4.6은 수학 올림피아드 금메달리스트입니다. 본 적 없는 문제, 여러 개념을 엮어야 하는 문제에서 차이가 벌어지죠.
대부분의 실무 코딩, 문서 작업, 에이전트 태스크는 '수능 범위'입니다. Opus가 필요한 건 미지의 추론이 요구되는 연구급 태스크뿐.
컴퓨터 사용 능력의 진화 속도
진짜 주목해야 할 건 개별 벤치마크 숫자가 아닙니다.
OSWorld 벤치마크 추이를 보면:
| 모델 | 시기 | OSWorld |
|---|---|---|
| Sonnet 3.5 | 2024.10 | 14.9% |
| Sonnet 3.7 | 2025.02 | 28.0% |
| Sonnet 4.0 | 2025.06 | 42.2% |
| Sonnet 4.5 | 2025.10 | 61.4% |
| Sonnet 4.6 | 2026.02 | 72.5% |
16개월 만에 5배. 3개월마다 약 10-15%p씩 올라가고 있습니다.
이 커브가 유지되면 올해 안에 90%를 넘깁니다. 'AI가 컴퓨터를 인간처럼 조작한다'가 연내 현실이 된다는 뜻입니다. 마우스 클릭, 드래그 앤 드롭, 폼 입력, 파일 관리를 AI가 직접 수행하는 시대가 오고 있어요.
Adaptive Thinking: 사고 깊이 자동 조절
기존 Extended Thinking은 항상 '깊게 생각'했습니다. 간단한 질문에도 토큰을 소모하며 과잉 추론하는 문제가 있었죠.
Adaptive Thinking은 4단계(low/medium/high/max)로 자동 조절됩니다.
| 레벨 | 용도 | 예시 |
|---|---|---|
| low | 즉답 가능한 질문 | "서울 날씨 알려줘" |
| medium | 일반 분석, 번역 | "이 이메일 한국어로 번역해줘" |
| high | 복잡한 디버깅, 설계 | "이 코드 리팩토링해줘" |
| max | 연구급 문제 | "이 논문의 방법론적 결함 분석해줘" |
사람이 문제 난이도에 따라 고민 시간을 조절하는 것과 같습니다. 결과적으로 같은 품질에 토큰 비용이 줄어듭니다.
개발자 입장에서 중요한 건: budget_tokens 파라미터로 "이 요청에는 최대 이만큼만 생각해"라고 제어할 수 있다는 점입니다. 비용 예측이 가능해졌어요.
Context Compaction: 가장 과소평가된 기능
1M 토큰 컨텍스트 윈도우 자체는 이전에도 있었지만, 문제는 'Lost-in-the-middle'이었습니다. 100만 토큰을 넣어도 중간 내용을 까먹으면 의미가 없으니까요.
Context Compaction은 서버 단에서 오래된 컨텍스트를 자동 요약합니다. 핵심 정보는 유지하면서 토큰을 절약하는 거죠.
이게 왜 중요한가? RAG 파이프라인의 설계가 바뀔 수 있기 때문입니다.
- 기존: 문서 -> 청킹 -> 임베딩 -> 벡터DB -> 리랭킹 -> LLM (5단계 파이프라인)
- 4.6: 문서 -> LLM (1단계, Compaction이 알아서 관리)
물론 아직 1M 컨텍스트는 베타이고, Usage Tier 4 이상에서만 접근 가능합니다. MRCR v2에서 Opus는 76%를 찍었지만 Sonnet 4.6의 수치는 아직 미공개. 이 부분은 검증이 필요합니다.
언제 Opus, 언제 Sonnet?
이번 벤치마크 결과를 종합하면 결론은 명확합니다.
Sonnet 4.6을 기본으로 쓰세요
- 코딩, 디버깅, 코드 리뷰 (SWE-bench 79.6%)
- 데이터 분석, 문서 작성, 지식 업무 (GDPval-AA 1633 Elo)
- 에이전트 워크플로우, 도구 사용 (Finance Agent 63.3%)
- 컴퓨터 직접 조작 (OSWorld 72.5%)
- 가격: $3 input / $15 output per M tokens
Opus 4.6은 이럴 때만
- 본 적 없는 문제를 풀어야 할 때 (ARC-AGI-2 68.8%)
- 수학 올림피아드급 추론이 필요할 때 (HLE 53.0%)
- 100만 토큰 문서에서 바늘 찾기를 해야 할 때 (MRCR v2 76%)
- 가격: $5 input / $25 output per M tokens
개발자라면 기본 스택을 Sonnet 4.6으로 바꾸고, Opus는 추론이 필요한 노드에만 쓰는 하이브리드 구조를 추천합니다. 같은 예산으로 약 1.67배 더 많은 작업을 처리할 수 있어요.
핵심 정리
Sonnet 4.6은 '저가형 Opus'가 아닙니다. 실무 최적화 모델입니다. 코딩, 에이전트, 지식 업무에서는 Opus와 동급이거나 앞서고, 비용은 약 40% 저렴. Opus가 필요한 순간은 "이 문제, 본 적 없는데?"라는 상황뿐입니다.
| 항목 | Sonnet 4.6 | Opus 4.6 |
|---|---|---|
| 가격 (input/output) | $3/$15 per M | $5/$25 per M |
| 코딩 (SWE-bench) | 79.6% | 80.8% |
| 컴퓨터 사용 (OSWorld) | 72.5% | 72.7% |
| 지식 업무 (GDPval-AA) | 1633 Elo | 1606 Elo |
| 추상 추론 (ARC-AGI-2) | 58.3% | 68.8% |
| 난문제 (HLE 툴) | 49.0% | 53.0% |
| 추천 용도 | 일상 업무 전부 | 연구급 추론 |
참고 소스: Anthropic 공식 블로그, Anthropic 시스템 카드, SWE-bench, OSWorld, ARC-AGI-2, Vals AI, Artificial Analysis
이메일로 받아보기
관련 포스트

MIRAGE — 멀티모달 AI는 정말로 이미지를 "보고" 있을까?
GPT-5.1, Gemini 3 Pro, Claude Opus 4.5가 이미지 없이도 벤치마크 점수의 70-80%를 유지. 3B 텍스트 전용 모델이 흉부 X-ray 벤치마크에서 모든 멀티모달 모델과 방사선과 전문의를 능가. 스탠포드 MIRAGE 논문 리뷰.

AgentScope vs LangGraph vs CrewAI — 2026 멀티 에이전트 프레임워크 비교
AgentScope(알리바바), LangGraph(LangChain), CrewAI 세 프레임워크를 실제 데이터와 코드 예제로 비교. 아키텍처, LLM 지원, 멀티모달, 메모리, 프로덕션 배포까지 완전 비교.

InternVL-U: 4B 파라미터로 이해+생성+편집을 동시에 -- 통합 멀티모달의 새 기준
Shanghai AI Lab의 InternVL-U. 4B 파라미터 단일 모델로 이미지 이해, 생성, 편집, 추론 기반 생성을 모두 수행. 디커플드 비주얼 표현으로 14B BAGEL을 GenEval과 DPG-Bench에서 능가.