Backpropagation From Scratch: Chain Rule, Computation Graphs, and Topological Sort
How microgpt.py's 15-line backward() works. From high school calculus to chain rule, computation graphs, topological sort, and backpropagation.
Backpropagation From Scratch: Chain Rule, Computation Graphs, and Topological Sort
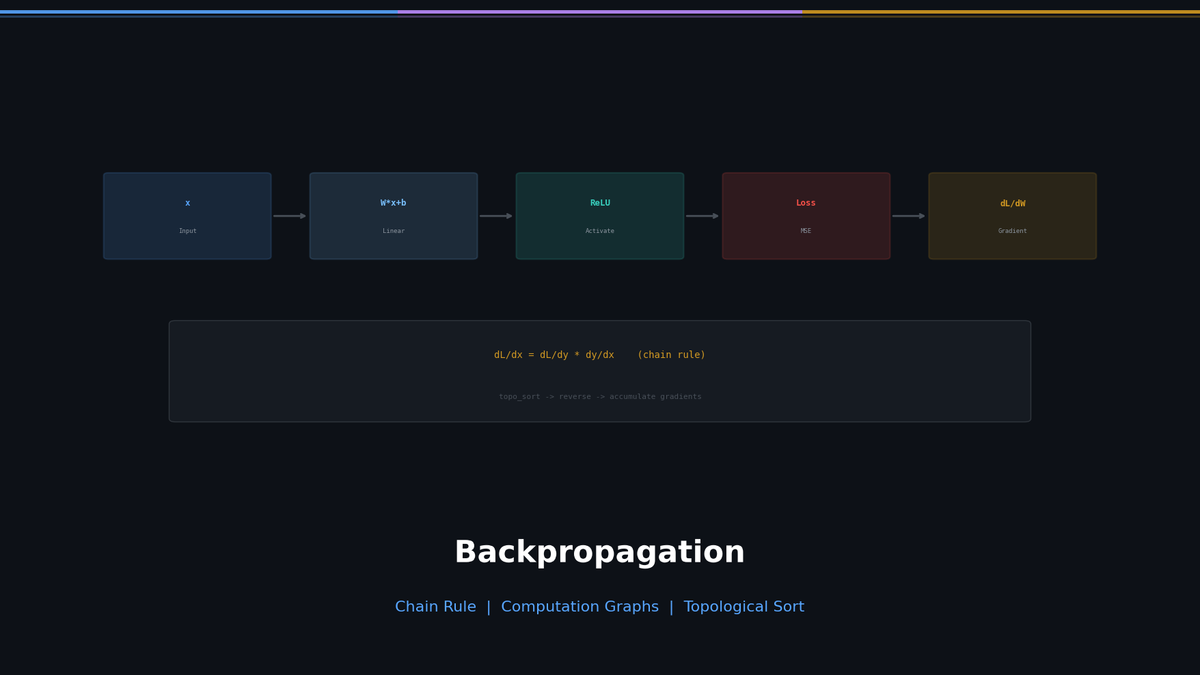
The backward() function in microgpt.py is 15 lines long. But these 15 lines are a complete implementation of the core algorithm that underpins all of deep learning -- backpropagation.
This post connects "why do we need topological sort?" and "what is the chain rule?" starting from high school calculus all the way to the backward() function in microgpt.py.
The Central Question of Deep Learning
Training a neural network means this:
- Feed an input and compute the output (forward pass)
- Measure how far the output is from the correct answer (loss)
- Compute how much each parameter contributed to the loss (gradient)
- Adjust each parameter slightly in the direction that reduces the loss (update)
Step 3 is the hard part. Whether there are 4,192 parameters (microgpt.py) or 70 billion (LLaMA), you need to compute "if I nudge this parameter slightly, how much does the loss change?" for each one.
Related Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.

MIRAGE — Do Multimodal AIs Actually "See" Images?
GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 retain 70-80% of benchmark scores without any image input. A 3B text-only model outperforms all multimodal models and radiologists on chest X-ray benchmarks. Stanford MIRAGE paper review.

InternVL-U: Understanding + Generation + Editing in One 4B Model -- A New Standard for Unified Multimodal AI
Shanghai AI Lab's InternVL-U. A single 4B parameter model handles image understanding, generation, editing, and reasoning-based generation. Decoupled visual representations outperform 14B BAGEL on GenEval and DPG-Bench.