역전파를 처음부터: Chain Rule, 계산 그래프, 위상 정렬
microgpt.py의 backward() 15줄이 작동하는 원리. 고등학교 미분부터 시작해 chain rule, 계산 그래프, 위상 정렬, 역전파까지 연결합니다.
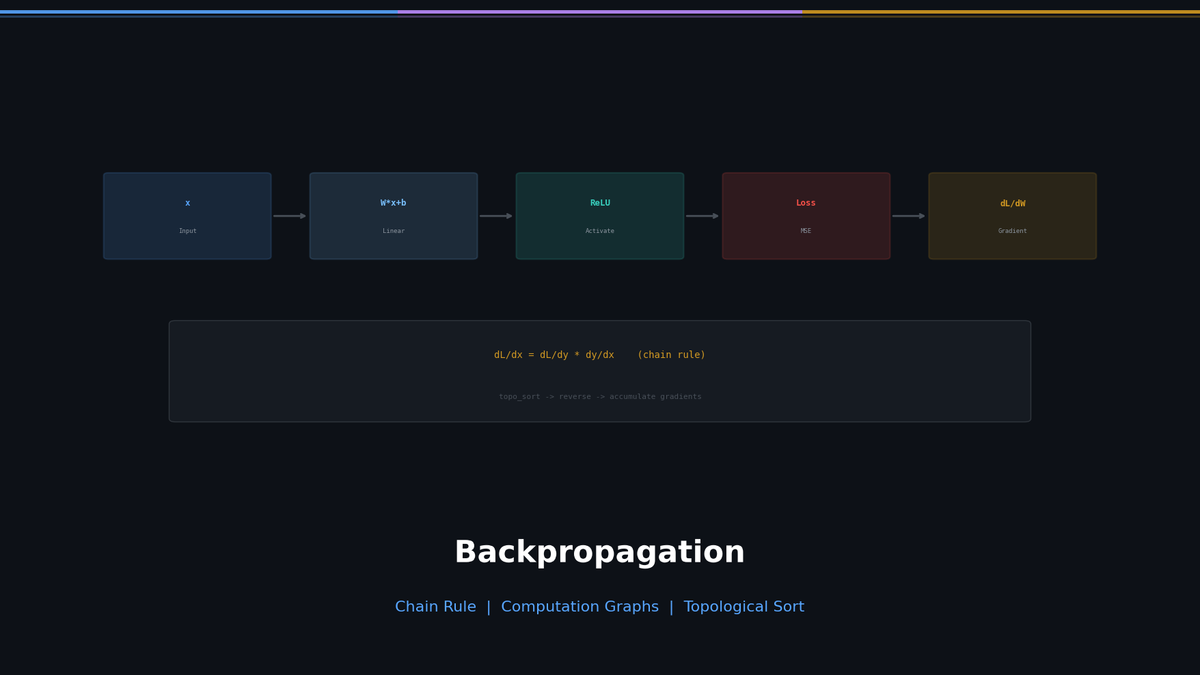
역전파를 처음부터: Chain Rule, 계산 그래프, 위상 정렬
microgpt.py의 backward() 함수는 15줄입니다. 하지만 이 15줄이 딥러닝 전체를 떠받치는 핵심 알고리즘 -- 역전파(backpropagation) -- 의 완전한 구현입니다.
이 글에서는 "왜 위상 정렬이 필요한가?"와 "chain rule이 뭔가?"를 고등학교 미분부터 시작해 microgpt.py의 backward()까지 연결합니다.
딥러닝의 핵심 질문
신경망을 학습시킨다는 것은 이런 뜻입니다:
- 입력을 넣고 출력을 계산한다 (forward pass)
- 출력이 정답과 얼마나 다른지 측정한다 (loss)
- 각 파라미터가 loss에 얼마나 기여했는지 계산한다 (gradient)
- loss를 줄이는 방향으로 파라미터를 조금씩 수정한다 (update)
3번이 어렵습니다. 파라미터가 4,192개(microgpt.py)든 70억 개(LLaMA)든, 각각에 대해 "이 파라미터를 살짝 바꾸면 loss가 얼마나 변하는가?"를 계산해야 합니다.
관련 포스트

MIRAGE — 멀티모달 AI는 정말로 이미지를 "보고" 있을까?
GPT-5.1, Gemini 3 Pro, Claude Opus 4.5가 이미지 없이도 벤치마크 점수의 70-80%를 유지. 3B 텍스트 전용 모델이 흉부 X-ray 벤치마크에서 모든 멀티모달 모델과 방사선과 전문의를 능가. 스탠포드 MIRAGE 논문 리뷰.

InternVL-U: 4B 파라미터로 이해+생성+편집을 동시에 -- 통합 멀티모달의 새 기준
Shanghai AI Lab의 InternVL-U. 4B 파라미터 단일 모델로 이미지 이해, 생성, 편집, 추론 기반 생성을 모두 수행. 디커플드 비주얼 표현으로 14B BAGEL을 GenEval과 DPG-Bench에서 능가.

Hybrid Mamba-Transformer MoE: 세 팀이 동시에 도달한 같은 결론 -- 2026년 LLM 아키텍처의 수렴
NVIDIA Nemotron 3 Nano, Qwen 3.5, Mamba-3가 독립적으로 75% 선형 레이어 + 25% 어텐션 + MoE 구조에 수렴. 88% KV-cache 절감, O(n) 복잡도로 긴 컨텍스트 처리.