Are LLMs Really Smart? Dissecting AI's Reasoning Failures
Stanford researchers analyzed 500+ papers to systematically map LLM reasoning failures. From cognitive biases to the reversal curse, discover where and why AI reasoning breaks down.

Are LLMs Really Smart? A Complete Guide to AI Reasoning Failures
Large Language Models like ChatGPT and Claude write complex code, compose poetry, and hold philosophical conversations. Yet they occasionally produce baffling answers to remarkably simple questions.
"Why does such a smart AI make such basic mistakes?"
A survey paper from Stanford -- "Large Language Model Reasoning Failures" by Song, Han, and Goodman (TMLR 2026) -- is the first comprehensive taxonomy of where and why LLMs break. Drawing from over 500 research papers, it maps out dozens of failure categories across reasoning types and failure modes.
This post walks through the paper's framework and key findings. Inspired by their taxonomy, we also designed 10 hands-on experiments and ran them across 7 current models. Detailed results are in Parts 1-3; this post is the overview.
The Paper's Framework
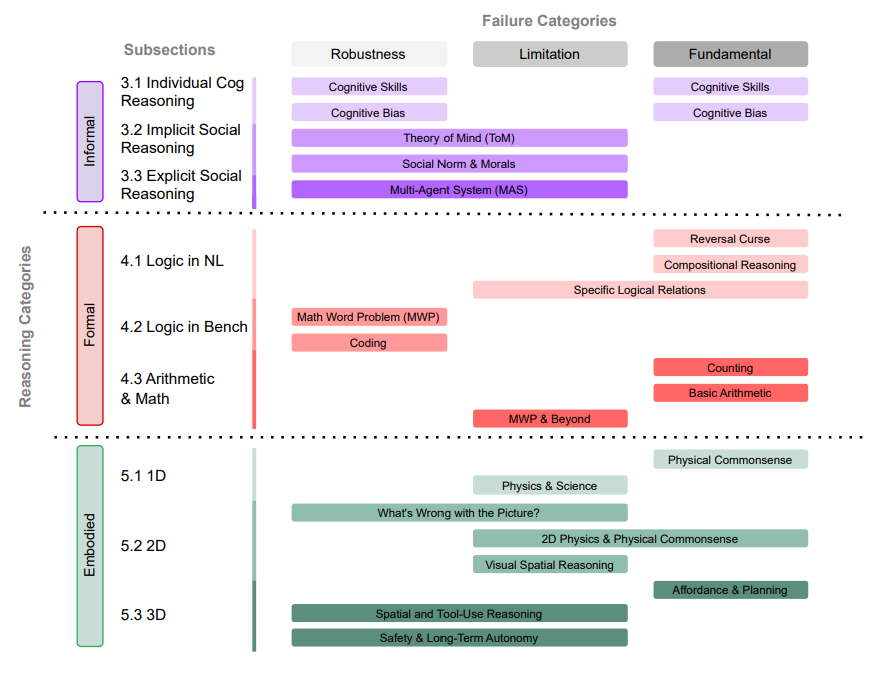
The paper classifies LLM reasoning failures along two axes.
Axis 1 -- Reasoning Type:
- Informal (Intuitive) Reasoning: cognitive skills (working memory, inhibitory control, cognitive flexibility), cognitive biases, Theory of Mind, social norms, moral reasoning, emotional intelligence
- Formal (Logical) Reasoning: logical inference, compositional reasoning, arithmetic, math word problems, coding, benchmark robustness
- Embodied Reasoning: text-based physical commonsense, 2D perception and spatial reasoning, 3D real-world planning and tool use
Axis 2 -- Failure Type:
- Fundamental Failures: architectural limitations intrinsic to LLMs that broadly affect downstream tasks. Cannot be solved by scaling.
- Application-Specific Limitations: shortcomings tied to particular domains -- e.g., math word problem brittleness, coding benchmark gaps.
- Robustness Issues: inconsistent performance across minor variations -- rephrasing, reordering, or adding distractors changes the answer.
This three-way distinction matters. Fundamental flaws require architectural innovation. Application-specific gaps need targeted training data or tooling. Robustness issues call for better evaluation and alignment. Matching the right solution to the right failure type is the first step.
What the Paper Covers
The survey catalogs failures across the full spectrum of LLM reasoning. Here are the major categories:
Informal Reasoning:
- Cognitive biases: anchoring, order/position bias, confirmation bias, framing effects, content effects, group attribution, negativity bias, narrative perspective sensitivity, prompt length sensitivity, distraction by irrelevant information
- Cognitive skills: working memory, inhibitory control, cognitive flexibility, abstract reasoning
- Social reasoning: Theory of Mind, social norms, moral values, emotional intelligence
- Multi-agent failures: long-horizon planning, inter-agent communication, strategic coordination
Formal Reasoning:
- Logic: Reversal Curse, compositional reasoning, syllogistic reasoning, causal inference, converse relation failures
- Arithmetic: counting, basic arithmetic (multiplication, multi-digit), math word problems
- Benchmarks: math word problem robustness (numeric/entity perturbations), coding benchmark robustness (docstring/variable renaming), MCQ option-order sensitivity
Embodied Reasoning:
- 1D (text-based): physical commonsense, physics and scientific reasoning
- 2D (perception-based): image anomaly detection, visual spatial reasoning, physical commonsense from images
- 3D (real-world): affordance understanding, tool-use planning, safety reasoning, long-term autonomy
The paper provides detailed analysis, benchmark results, and mitigation strategies for each of these. What follows is our attempt to reproduce a representative sample.
Our Experiments: 7 Models x 10 Tests
From the paper's 30+ failure categories, we selected 10 that are reproducible with API calls and tested them across 7 models: GPT-4o, GPT-4o-mini, o3-mini, Claude Sonnet 4.5, Claude Haiku 4.5, Gemini 2.5 Flash, and Gemini 2.5 Flash-Lite.
Where Our Tests Sit in the Paper's Taxonomy
| Our Test | Paper Category | Reasoning Type | Failure Type |
|---|---|---|---|
| Reversal Curse | Reversal Curse | Formal | Fundamental |
| Counting | Counting | Formal | Fundamental |
| Compositional Reasoning | Compositional Reasoning | Formal | Fundamental |
| Anchoring Bias | Anchoring Bias | Informal | Robustness |
| Order Bias | Order/Position Bias | Informal | Robustness |
| Sycophancy | Cognitive Biases | Informal | Robustness |
| Confirmation Bias | Confirmation Bias | Informal | Robustness |
| Theory of Mind | Theory of Mind | Informal | Fundamental |
| Physical Common Sense | Physical Commonsense | Embodied | Fundamental |
| Working Memory | Working Memory | Informal | Fundamental |
Scorecard
| Model | Reversal Curse | Counting | ToM | Compositional | Sycophancy | Physical | Working Memory | Total |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 4/4 | 2/5 | 3/4 | 3/4 | 4/4 | 5/5 | 5/5 | 26/31 |
| GPT-4o-mini | 4/4 | 3/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 28/31 |
| o3-mini | 4/4 | 4/5 | 4/4 | 1/4 | 4/4 | 4/5 | 4/5 | 25/31 |
| Claude Sonnet 4.5 | 4/4 | 5/5 | 4/4 | 4/4 | 4/4 | 5/5 | 5/5 | 31/31 |
| Claude Haiku 4.5 | 3/4 | 4/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 28/31 |
| Gemini 2.5 Flash | 3/4 | 5/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 29/31 |
| Gemini 2.5 Flash-Lite | 3/4 | 5/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 29/31 |
Anchoring Bias, Order Bias, and Confirmation Bias are excluded from the scorecard because they measure the degree of bias rather than pass/fail accuracy.
Part 1: Structural Limitations
Reversal Curse, Counting, and Compositional Reasoning -- all rooted in the next-token prediction architecture. RAG can patch the Reversal Curse but not fix it. Reasoning models work around counting via character enumeration, but this is a workaround, not a solution. Compositional reasoning degrades sharply with hop count and distractors.
Detailed results and code: Part 1 -- Structural Limitations
Part 2: Cognitive Biases
Anchoring Bias, Order Bias, Sycophancy, and Confirmation Bias -- inherited from RLHF and biased training data. Anchoring was the most severe: 6 out of 7 models copied the anchor verbatim rather than being pulled toward it. Confirmation Bias was the weakest, but Gemini models showed persona mirroring -- matching the user's stated identity.
Detailed results and code: Part 2 -- Cognitive Biases
Part 3: Common Sense and Cognition
Theory of Mind, Physical Common Sense, and Working Memory -- the limits of learning from text alone. Basic ToM tests pass, but 3rd-order beliefs break 3 out of 7 models. Famous physics problems are memorized, but counter-intuitive scenarios expose gaps. Short-context memory updates are tracked, but real-world interference at scale remains an open problem.
Detailed results and code: Part 3 -- Common Sense and Cognition
Efforts Toward Solutions
The paper organizes mitigation strategies across four layers.
Data-centric: bias-reduced data curation, bidirectional fact exposure, graph-structured reasoning paths.
Training process: adversarial training, fine-tuning with deliberately injected interference, editing MHSA modules for compositional reasoning.
Inference-time: Chain-of-Thought prompting, RAG, activation steering, multi-persona debate.
Architecture: neuro-symbolic augmentations, attention mechanisms mimicking human cognition, multimodal approaches.
However, most mitigation strategies remain task-specific, vulnerable to prompt manipulation, and often produce surface-level improvements rather than structural fixes.
Key Takeaways
- Distinguish fundamental failures from application-specific limitations from robustness issues. The solutions are different for each.
- Scaling alone is not enough. Even reasoning-specialized models like o3 remain brittle under simple perturbations.
- LLM failures resemble human cognitive limitations. This is not just about biased data -- there may be deeper structural parallels.
- RAG is a bandage, not a cure. The Reversal Curse disappears when facts are placed in context, but the fundamental asymmetry in the model's internal knowledge persists.
- Current benchmarks are dangerous. Accuracy-only evaluation misses failure patterns. We need stress tests that vary question order, inject distractors, and rephrase prompts to check for consistency.
Series Table of Contents
- Overview: Are LLMs Really Smart? (this post)
- Part 1: Structural Limitations -- Reversal Curse, Counting, Compositional Reasoning
- Part 2: Cognitive Biases -- Anchoring, Order Bias, Sycophancy, Confirmation Bias
- Part 3: Common Sense and Cognition -- Theory of Mind, Physical Common Sense, Working Memory
- Notebook: Full Experiment Code (Jupyter Notebook)
Reference: Song, P., Han, P., & Goodman, N. (2025). Large Language Model Reasoning Failures. Transactions on Machine Learning Research (TMLR), 2026.
Subscribe to Newsletter
Related Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.

Self-Evolving AI Agents — The New Paradigm of 2026
GenericAgent, Evolver, Open Agents — comparing 3 self-evolving agent frameworks that learn, adapt, and grow without human coding.

Build Your Own LLM Knowledge Base — A Karpathy-Style Knowledge System
Complete guide to building a permanent personal knowledge system with Obsidian + Claude Code. Wiki + Memory dual-axis architecture.