LLM이 정말 똑똑할까요? AI의 '추론 실패'를 파헤치다
스탠포드 연구진이 500편 이상의 논문을 분석해 LLM의 추론 실패를 체계적으로 정리했습니다. 인지 편향, 역전의 저주, 합성적 추론 실패 등 AI가 어디서 왜 실패하는지 알아봅니다.

LLM이 정말 똑똑할까요? AI 추론 실패 완전 가이드
ChatGPT나 Claude 같은 대규모 언어 모델(LLM)은 복잡한 코드를 짜고, 시를 쓰며, 철학적인 대화도 나눕니다. 하지만 가끔 아주 간단한 문제에서 엉뚱한 대답을 내놓아 당황하게 만들기도 합니다.
"왜 이렇게 똑똑한 AI가 이런 기본적인 실수를 할까?"
스탠포드 대학교의 Song, Han, Goodman이 발표한 서베이 논문 "Large Language Model Reasoning Failures"(TMLR 2026)는 LLM이 어디서, 왜 실패하는지를 체계적으로 정리한 최초의 분류 체계입니다. 500편 이상의 연구를 분석해 수십 가지 실패 유형을 추론 유형별, 실패 성격별로 매핑합니다.
이 글에서는 논문의 프레임워크와 핵심 발견을 소개합니다. 논문의 분류 체계에 영감을 받아 10가지 실험을 직접 설계하고 7개 최신 모델로 재현해봤습니다. 실험의 상세 결과는 Part 1-3에서 다루고, 이 글은 전체 개요입니다.
논문의 분류 체계
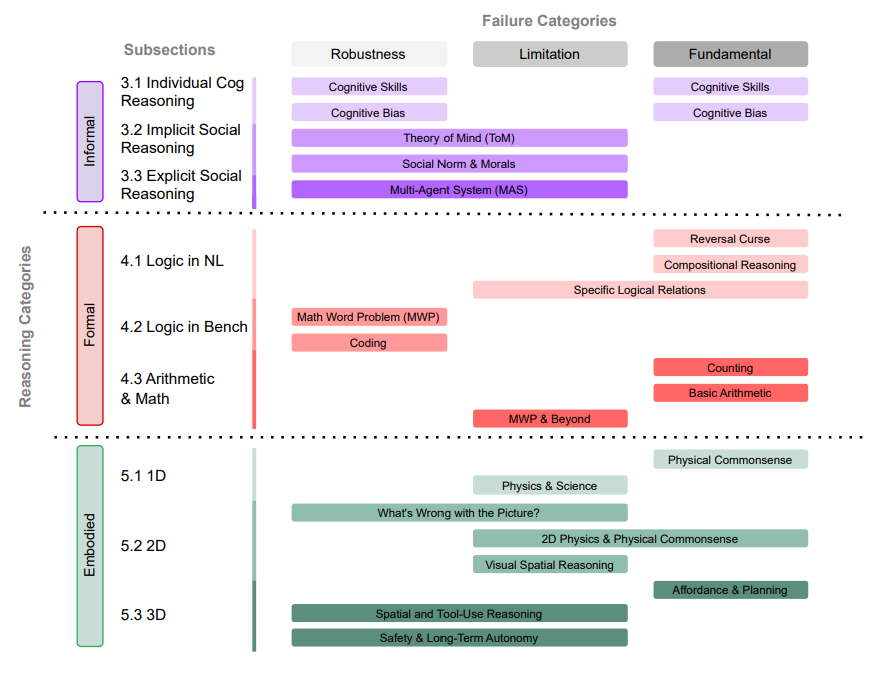
논문은 LLM 추론 실패를 두 축으로 분류합니다.
축 1 -- 추론 유형:
- Informal (직관적) Reasoning: 인지 능력(working memory, inhibitory control, cognitive flexibility), cognitive biases, Theory of Mind, 사회 규범, 도덕적 추론, 감성 지능
- Formal (논리적) Reasoning: 논리적 추론, compositional reasoning, 산술, 수학 문장제, 코딩, 벤치마크 견고성
- Embodied Reasoning: 텍스트 기반 물리 상식, 2D 지각과 공간 추론, 3D 실세계 계획과 도구 사용
축 2 -- 실패 성격:
- Fundamental Failures: LLM 아키텍처에 내재된 구조적 한계. 스케일링으로 해결 불가.
- Application-Specific Limitations: 특정 도메인에 한정된 약점 -- 수학 문장제의 취약성, 코딩 벤치마크 갭 등.
- Robustness Issues: 사소한 변형에 따른 일관성 부재 -- 표현을 바꾸거나, 순서를 바꾸거나, 방해 정보를 넣으면 답이 달라지는 현상.
이 세 가지 구분이 중요합니다. Fundamental 결함에는 아키텍처 혁신이, Application-Specific 한계에는 타겟 데이터나 도구가, Robustness 문제에는 더 나은 평가와 정렬이 필요합니다. 실패 유형에 맞는 해결책을 찾는 것이 첫걸음입니다.
논문이 다루는 실패 유형들
서베이는 LLM 추론의 전체 스펙트럼에 걸친 실패를 정리합니다. 주요 카테고리는 다음과 같습니다.
Informal Reasoning:
- Cognitive biases: anchoring, order/position bias, confirmation bias, framing effects, content effects, group attribution, negativity bias, narrative perspective sensitivity, prompt length sensitivity, distraction
- Cognitive skills: working memory, inhibitory control, cognitive flexibility, abstract reasoning
- Social reasoning: Theory of Mind, 사회 규범, 도덕적 가치, 감성 지능
- Multi-agent failures: long-horizon planning, 에이전트 간 소통, 전략적 협조
Formal Reasoning:
- Logic: Reversal Curse, compositional reasoning, syllogistic reasoning, causal inference, converse relation failures
- Arithmetic: counting, 기본 산술(곱셈, 다자릿수), 수학 문장제
- Benchmarks: 수학 문장제 견고성(수치/엔티티 변형), 코딩 벤치마크 견고성(docstring/변수 리네이밍), MCQ 선택지 순서 민감도
Embodied Reasoning:
- 1D (텍스트 기반): physical commonsense, 물리/과학적 추론
- 2D (지각 기반): 이미지 이상 탐지, 시각적 공간 추론, 이미지에서의 물리 상식
- 3D (실세계): affordance 이해, 도구 사용 계획, 안전 추론, 장기 자율성
논문은 이 각각에 대해 상세한 분석, 벤치마크 결과, 완화 전략을 제공합니다. 아래는 이 중 대표적인 10가지를 직접 재현해본 결과입니다.
직접 실험: 7개 모델 x 10가지 테스트
논문의 30+ 실패 유형 중 API 호출만으로 재현 가능한 10가지를 골라, GPT-4o, GPT-4o-mini, o3-mini, Claude Sonnet 4.5, Claude Haiku 4.5, Gemini 2.5 Flash, Gemini 2.5 Flash-Lite 7개 모델로 테스트했습니다.
논문 분류 체계에서의 위치
| 테스트 | 논문 카테고리 | 추론 유형 | 실패 성격 |
|---|---|---|---|
| Reversal Curse | Reversal Curse | Formal | Fundamental |
| Counting | Counting | Formal | Fundamental |
| Compositional Reasoning | Compositional Reasoning | Formal | Fundamental |
| Anchoring Bias | Anchoring Bias | Informal | Robustness |
| Order Bias | Order/Position Bias | Informal | Robustness |
| Sycophancy | Cognitive Biases | Informal | Robustness |
| Confirmation Bias | Confirmation Bias | Informal | Robustness |
| Theory of Mind | Theory of Mind | Informal | Fundamental |
| Physical Common Sense | Physical Commonsense | Embodied | Fundamental |
| Working Memory | Working Memory | Informal | Fundamental |
Scorecard
| 모델 | Reversal Curse | Counting | ToM | Compositional | Sycophancy | Physical | Working Memory | Total |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 4/4 | 2/5 | 3/4 | 3/4 | 4/4 | 5/5 | 5/5 | 26/31 |
| GPT-4o-mini | 4/4 | 3/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 28/31 |
| o3-mini | 4/4 | 4/5 | 4/4 | 1/4 | 4/4 | 4/5 | 4/5 | 25/31 |
| Claude Sonnet 4.5 | 4/4 | 5/5 | 4/4 | 4/4 | 4/4 | 5/5 | 5/5 | 31/31 |
| Claude Haiku 4.5 | 3/4 | 4/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 28/31 |
| Gemini 2.5 Flash | 3/4 | 5/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 29/31 |
| Gemini 2.5 Flash-Lite | 3/4 | 5/5 | 4/4 | 4/4 | 4/4 | 4/5 | 5/5 | 29/31 |
Anchoring Bias, Order Bias, Confirmation Bias는 정답이 아닌 편향의 정도를 측정하므로 스코어카드에서 제외했습니다.
Part 1: Structural Limitations
Reversal Curse, Counting, Compositional Reasoning -- 모두 next-token prediction 아키텍처에 뿌리를 둔 실패입니다. RAG로 Reversal Curse를 우회할 수 있지만 근본 해결은 아닙니다. 추론 모델은 문자 나열로 counting을 우회하지만, 이것 역시 워크어라운드입니다. Compositional reasoning은 hop 수와 방해 정보가 늘수록 급격히 열화됩니다.
상세 결과 및 코드: Part 1 -- Structural Limitations
Part 2: Cognitive Biases
Anchoring Bias, Order Bias, Sycophancy, Confirmation Bias -- RLHF와 편향된 학습 데이터에서 비롯됩니다. Anchoring이 가장 심각: 7개 모델 중 6개가 앵커를 그대로 복사했습니다. Confirmation Bias는 가장 약했지만, Gemini 계열은 유저의 페르소나를 따라하는 persona mirroring을 보였습니다.
상세 결과 및 코드: Part 2 -- Cognitive Biases
Part 3: Common Sense & Cognition
Theory of Mind, Physical Common Sense, Working Memory -- 텍스트만으로 학습한 한계입니다. 기본 ToM은 통과하지만 3rd-order belief에서 7개 중 3개가 실패합니다. 유명한 물리 문제는 암기했지만 반직관적 시나리오에서 갈립니다. 짧은 컨텍스트의 정보 업데이트는 추적하지만, 실전 규모의 간섭은 미해결 과제입니다.
상세 결과 및 코드: Part 3 -- Common Sense & Cognition
해결을 향한 노력
논문은 완화 전략을 네 층위로 정리합니다.
데이터 중심: 편향 줄인 데이터 큐레이션, 양방향 사실 관계 노출, 그래프 구조 추론 경로
학습 과정: 적대적 훈련, 간섭 주입 파인튜닝, MHSA 모듈 편집
추론 시점: Chain-of-Thought, RAG, 활성화 스티어링, 멀티 페르소나 토론
아키텍처: 뉴로-심볼릭 확장, 인간 인지 모방 어텐션, 멀티모달 접근
하지만 대부분의 완화 전략은 특정 과제에 국한되고, 프롬프트 조작에 취약하며, 표면적 개선에 그치는 경우가 많습니다.
핵심 인사이트
- Fundamental failures, Application-specific limitations, Robustness issues를 구분하라. 해결책이 각각 다르다.
- 스케일링만으로는 부족하다. o3 같은 추론 모델도 간단한 변형에 취약하다.
- LLM의 실패는 인간의 인지적 한계와 닮았다. 편향된 데이터뿐 아니라, 더 깊은 구조적 유사성이 있을 수 있다.
- RAG는 반창고, 치료제가 아니다. Reversal Curse는 컨텍스트에 사실을 넣어주면 해결되지만, 모델 내부 지식의 근본적 비대칭은 그대로다.
- 현재 벤치마크는 위험하다. 정답률만 보는 평가는 실패 양상을 놓친다. 순서를 바꾸고, 방해 정보를 넣고, 표현을 바꿔도 일관되는지 테스트해야 한다.
시리즈 목차
- 개요: LLM이 정말 똑똑할까요? (이 글)
- Part 1: Structural Limitations -- Reversal Curse, Counting, Compositional Reasoning
- Part 2: Cognitive Biases -- Anchoring, Order Bias, Sycophancy, Confirmation Bias
- Part 3: Common Sense & Cognition -- Theory of Mind, Physical Common Sense, Working Memory
- 노트북: 전체 실험 코드 (Jupyter Notebook)
참고 문헌: Song, P., Han, P., & Goodman, N. (2025). Large Language Model Reasoning Failures. Transactions on Machine Learning Research (TMLR), 2026.
이메일로 받아보기
관련 포스트

Reversal Curse를 깨는 Identity Bridge — ICML 2026, 이래도 되는데 되는 fix
언어 모델은 "Alice의 남편은 Bob"을 학습해도 "Bob의 아내는?"을 못 맞힙니다 — 유명한 reversal curse. ICML 2026 논문 하나가 학습 데이터에 이상한 자기참조 예제를 섞는 것만으로 이 문제를 해결합니다. 순진한 버전은 안 되고, 정교한 버전은 됩니다.

스스로 진화하는 AI 에이전트 — 2026년의 새로운 패러다임
GenericAgent, Evolver, Open Agents — 스스로 스킬을 만들고, 실행 경로를 기억하고, 실패에서 배우는 자가 진화 에이전트 3종 비교.

나만의 LLM Knowledge Base 구축하기 — Karpathy 스타일 지식 시스템
Obsidian + Claude Code로 영구적인 개인 지식 체계를 만드는 완전 가이드. 위키 + 메모리 두 축의 지식 시스템.