MiniMax M2.5: Opus-Level Performance at $1 per Hour
MiniMax M2.5 achieves SWE-bench 80.2% using only 10B active parameters from a 230B MoE architecture. 1/20th the cost of Claude Opus with comparable coding performance. Forge RL framework, benchmark analysis, pricing comparison.
MiniMax M2.5: Opus-Level Performance for $1 per Hour
On February 12, 2026, Shanghai-based AI startup MiniMax released M2.5. SWE-bench Verified 80.2%, BrowseComp 76.3%, Multi-SWE-Bench 51.3%. All within 0.6%p of Claude Opus 4.6, at 1/20th the price.
The model is available as open weights on Hugging Face under a modified MIT license. It runs on a 230B parameter MoE architecture, activating only 10B at inference time. Running the 100 TPS (tokens per second) Lightning variant continuously for one hour costs about $1.
This post analyzes M2.5's architecture, training methodology, benchmark performance, and pricing structure, and examines what it means for the AI industry.
Architecture: 230B Total, 10B Active
MiniMax M2.5 uses a Mixture of Experts (MoE) architecture.
| Spec | Value |
|---|---|
| Total Parameters | 230B |
| Active Parameters | 10B — roughly 4% of total |
| Context Window | 204,800 tokens (~205K) |
| Training Languages | 13 (Python, Go, C, C++, TypeScript, Rust, Kotlin, Java, JavaScript, PHP, Lua, Dart, Ruby) |
The core idea behind MoE: for each input token, only a subset of "expert" parameters are activated. This preserves the knowledge capacity of a 230B model while keeping actual compute at the level of a 10B model. That is the secret behind the price and speed.
It ships in two variants:
| Variant | Speed | Input (1M tokens) | Output (1M tokens) |
|---|---|---|---|
| M2.5 (Standard) | 50 TPS | $0.15 | $1.20 |
| M2.5-Lightning | 100 TPS | $0.30 | $2.40 |
Lightning costs twice as much at twice the speed. Accuracy is identical.
Forge: A Reinforcement Learning Framework for Agents
The key to M2.5's performance is Forge, an in-house reinforcement learning (RL) framework.
Traditional LLM training works by "reading text and predicting the next token." Forge takes a different approach. It places the model in real environments and rewards it based on task completion.
Training environments:
- Over 200,000 real code repositories
- Web browsers (search, navigation, information gathering)
- Office applications (Word, Excel, PowerPoint)
- API endpoints and tool calls
Technical highlights of Forge:
- CISPO (Clipping Importance Sampling Policy Optimization): An algorithm that ensures stability during large-scale RL training of MoE models. It addresses gradient imbalance across experts.
- Process Reward: When the agent performs long tasks (tens of thousands of tokens), it evaluates not just the final result but also the quality of intermediate steps. This solves the credit assignment problem in long-context scenarios.
- Asynchronous scheduling + tree-structured sample merging: Achieved roughly 40x training speedup.
- Trajectory-based speed optimization: Trains the model to achieve the same performance with fewer tokens. 20% reduction in token usage compared to M2.1.
As a result, M2.5 was not trained as "a model that can write code" but as "an agent that designs and executes projects." It analyzes architecture, decomposes features, and designs UI before writing a single line of code.
Internally at MiniMax, M2.5-generated code reportedly accounts for 80% of newly committed code.
Benchmarks: What the Numbers Say
Coding Performance
| Benchmark | M2.5 | Claude Opus 4.6 | GPT-5.2 |
|---|---|---|---|
| SWE-bench Verified | 80.2% | 80.8% | 80.0% |
| Multi-SWE-Bench | 51.3% (1st) | - | - |
| Droid Harness | 79.7% | 78.9% | - |
| OpenCode Harness | 76.1% | 75.9% | - |
| SWE-bench Completion Time | 22.8 min | 22.9 min | - |
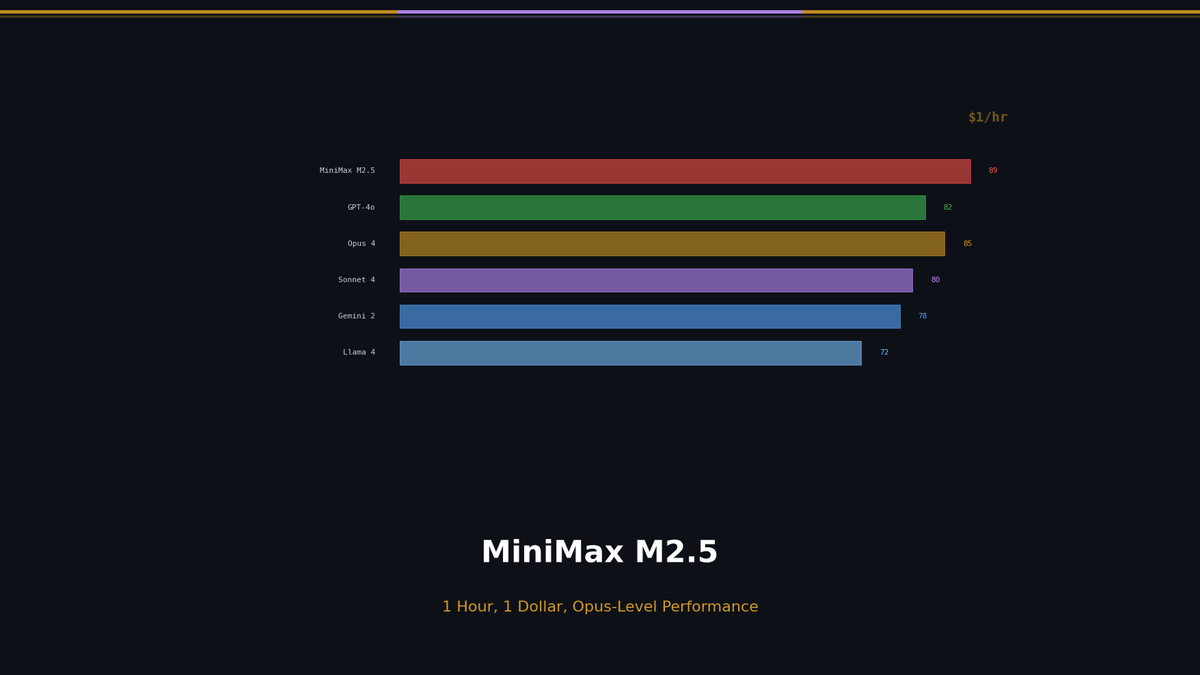
Only 0.6%p separates M2.5 from Opus 4.6 on SWE-bench Verified. On Droid and OpenCode harnesses, M2.5 actually comes out ahead. Task completion time is on par with Opus and 37% faster than M2.1.
On Multi-SWE-Bench (multilingual coding), it ranks first in the industry. The effect of Forge training across 13 programming languages is clear.
Search and Tool Use
| Benchmark | M2.5 | Notes |
|---|---|---|
| BrowseComp | 76.3% | Includes context management |
| BFCL (tool calling) | 76.8% | Industry-leading |
BrowseComp evaluates a model's ability to navigate the web and answer complex questions. M2.5 surpassed both GPT-5.2 and Gemini 3 Pro. It uses a strategy of discarding history when context exceeds 30% of the maximum length.
General Knowledge and Reasoning
| Benchmark | M2.5 | Opus 4.6 |
|---|---|---|
| AIME25 (math) | 86.3 | 95.6 |
| GPQA-D (graduate-level) | 85.2 | 90.0 |
| SciCode (science) | 44.4 | 52.0 |
In general reasoning, M2.5 falls behind Opus 4.6. A 9.3-point gap on AIME25, 4.8 points on GPQA-D. This is where M2.5 hits its ceiling. It matches Opus in coding and agentic tasks, but there is a clear gap in pure reasoning ability.
Office and Productivity
M2.5 scored a 59.0% win rate against mainstream models on GDPval-MM, a benchmark evaluating Word, PowerPoint, and Excel tasks. Through MiniMax Agent, it also offers automatic loading of Office Skills based on file type.
Pricing Comparison: The Real Story
More striking than the benchmark numbers is the pricing.
| Model | Input (1M) | Output (1M) | Representative Performance | Notes |
|---|---|---|---|---|
| MiniMax M2.5 | $0.15 | $1.20 | SWE-bench 80.2% | Open weights, 50 TPS |
| MiniMax M2.5-Lightning | $0.30 | $2.40 | Same as Standard (2x speed) | 100 TPS |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Third-party metrics only | Cheapest lightweight model |
| Gemini 3 Flash (preview) | $0.50 | $3.00 | SWE-bench 78% | 1M context, 64K output |
| gpt-5-mini | $0.25 | $2.00 | Third-party metrics only | OpenAI lightweight model |
| gpt-5.2 (Standard) | $1.75 | $14.00 | SWE-bench 80% | Flagship |
| Claude Sonnet 4.5 | $3.00 | $15.00 | SWE-bench 77.2% (third-party) | Reasoning-focused |
| Claude Opus 4.6 | $5.00 | $25.00 | SWE-bench 80.8% | Top performance |
For M2.5 Standard:
- vs. Opus 4.6: 1/33 input cost, 1/21 output cost. SWE-bench gap is just 0.6%p.
- vs. GPT-5.2: 1/12 input cost, 1/12 output cost. SWE-bench is actually 0.2%p higher.
- vs. Sonnet 4.5: 1/20 input cost, 1/13 output cost. SWE-bench is 3%p higher.
With the same budget ($100), M2.5 lets you process 20-30x more tokens than Opus. In agent workflows, this difference shifts the boundary between "possible" and "not possible."
Hourly cost for continuous operation:
| Model | Cost per Hour at 100 TPS |
|---|---|
| M2.5-Lightning | ~$1 |
| GPT-5.2 | ~$5 |
| Claude Opus 4.6 | ~$9 |
Running 4 instances year-round: M2.5 costs roughly $10,000, Opus roughly $200,000.
Benchmark Caveats
There is important context when interpreting SWE-bench Verified/Pro scores.
These benchmarks measure the combined performance of "model + agent harness + tools + prompt + number of runs," not the model in isolation. The same model can vary by 5-10%p depending on which scaffold (agent framework) is used.
For example:
- OpenAI reported GPT-5.2's SWE-bench Verified at 80%, marking it "not plotted" and describing the evaluation setup separately.
- M2.5's 80.2% is based on MiniMax's own agent scaffold.
- Scores may differ when measured through OpenHands (a third-party framework).
So rather than concluding "M2.5 = Opus," the real takeaway is that this level of performance is now achievable at this price point. It is important to distinguish between third-party measurements (Artificial Analysis, OpenHands Index, etc.) and vendor-reported numbers.
Budget Model Showdown: M2.5 vs Gemini 2.5 Flash vs Flash-Lite
M2.5's pricing is striking, but Google's Gemini lineup is no pushover either. Gemini 2.5 Flash targets the balanced middle ground, while Flash-Lite goes for ultra-low cost. The three models occupy entirely different positions.
| Metric | MiniMax M2.5 | Gemini 2.5 Flash | Gemini 2.5 Flash-Lite |
|---|---|---|---|
| Positioning | Coding/Agent specialist | Balanced | Ultra-low cost/speed |
| Input Price (1M tokens) | $0.15 | $0.30 | $0.10 |
| Output Price (1M tokens) | $1.20 | $2.50 | $0.40 |
| Total Cost (3:1 input:output ratio) | $0.53 | $1.08 | $0.18 |
| Intelligence Index v4.0 | 42 (top-tier) | 21 (upper-mid) | 13 (below average) |
| SWE-bench Verified | 80.2% (SOTA-level) | 54% | Not disclosed |
| Output Speed | 68 tok/s / 100 tok/s (Lightning) | 257 tok/s | 406 tok/s |
| Context Window | 205K tokens | 1M tokens | 1M tokens |
| Open Weights | Yes (modified MIT) | No | No |
Total cost is calculated at a 3:1 input:output ratio (a typical agent usage pattern). M2.5 costs half as much as Flash while scoring 2x on Intelligence Index and 1.5x on SWE-bench.
Artificial Analysis's Intelligence Index v4.0 aggregates 10 benchmarks including GDPval-AA, Terminal-Bench Hard, SciCode, GPQA Diamond, and Humanity's Last Exam. M2.5 (42) is 2x Flash (21) and 3x Flash-Lite (13).
Selection criteria for the three models:
- Complex coding, agent workflows, hard reasoning -> MiniMax M2.5 (performance first)
- Decent performance + fast responses + wide context -> Gemini 2.5 Flash (balanced)
- High-volume simple classification, translation, summarization -> Gemini 2.5 Flash-Lite (cost first)
M2.5 is "affordable Opus," Flash is "affordable Sonnet," and Flash-Lite is "affordable Haiku."
What Open Weights Means
M2.5 is released on Hugging Face under a modified MIT license. There is one condition: commercial use requires displaying "MiniMax M2.5" in the UI.
Local deployment options:
| Framework | Status |
|---|---|
| SGLang | Recommended |
| vLLM | Recommended |
| Transformers (HuggingFace) | Supported |
| KTransformers | Supported |
| Ollama (GGUF) | Community-supported |
Although it is a 230B MoE, the active parameter count is only 10B, making it feasible to run on consumer GPUs with appropriate quantization. Unsloth provides GGUF quantized versions.
Why this matters: you can run Opus 4.6-class coding performance without API calls, on your own infrastructure, without sending data externally. This becomes a meaningful option for environments with enterprise security requirements.
Limitations and Caveats
M2.5 is not a silver bullet. It has clear weaknesses.
Gap in pure reasoning: AIME25 86.3 vs Opus 95.6, GPQA-D 85.2 vs 90.0. In mathematical reasoning and science problems, it clearly trails the Western flagship models.
Real-world issues (per OpenHands reports):
- Occasionally targets the wrong git branch
- Misses instructions (ignores directives to use specific markup tags)
- Inconsistent instruction following
Scaffold dependency: Benchmark performance depends heavily on the scaffold. MiniMax's own scaffold yields 80.2%, but other frameworks may produce different results.
China-based company risk: There are non-technical considerations around data sovereignty, regulatory environment changes, and service reliability. Being open weights, local deployment mitigates some of these concerns.
What Has Changed
M2.5 carries the slogan "Intelligence too cheap to meter" — a riff on the 1954 prediction that nuclear power would become "too cheap to meter."
It is an exaggerated slogan, but the direction is right:
- Opus-level coding performance is now available at 1/20th the price.
- An open-weights model has surpassed Claude Sonnet-level performance for the first time (per OpenHands).
- Achieving frontier performance with 4% parameter activation (10B out of 230B) validates the efficiency of MoE architecture.
- Forge's "learn in the environment" paradigm presents a training methodology suited for the agent era.
Six months ago, "SWE-bench 80% was only possible with Opus." Now it is possible at $0.15/M input tokens.
The price-performance curve for AI models is dropping faster than Moore's Law. M2.5 is the latest data point on that curve.
Summary
| Item | Details |
|---|---|
| Model | MiniMax M2.5 / M2.5-Lightning |
| Architecture | 230B MoE, 10B active parameters |
| Context | 204,800 tokens |
| Price (Standard) | $0.15/M input, $1.20/M output |
| Price (Lightning) | $0.30/M input, $2.40/M output |
| SWE-bench Verified | 80.2% (Opus 4.6: 80.8%) |
| Open Weights | Modified MIT license |
| Training | Forge RL, 200K+ real environments, CISPO algorithm |
| Speed | 50 TPS (Standard), 100 TPS (Lightning) |
| Key Strengths | Coding, agent tasks, search, office productivity |
| Key Weaknesses | Pure reasoning (math, science) |
References
- MiniMax, "MiniMax M2.5: Built for Real-World Productivity." MiniMax News, 2026.
- OpenHands, "MiniMax M2.5: Open Weights Models Catch Up to Claude Sonnet." OpenHands Blog, 2026.
- Artificial Analysis, "MiniMax-M2.5 - Intelligence, Performance & Price Analysis." 2026.
- MiniMaxAI, "MiniMax-M2.5." Hugging Face Model Card, 2026.
- VentureBeat, "MiniMax's new open M2.5 and M2.5 Lightning near state-of-the-art while costing 1/20th of Claude Opus 4.6." 2026.
Subscribe to Newsletter
Related Posts

Breaking the Reversal Curse with Identity Bridges — the ICML 2026 fix that shouldn't work but does
LLMs trained on "Alice's husband is Bob" famously fail on "Bob's wife is?" — the reversal curse. A new ICML 2026 paper fixes it by adding one weird kind of self-referential example to the training set. The naive version doesn't work; the right version does.
Fine-tuning Gemma 4 MoE — Customizing Arena #6 with 3.8B Active Parameters
Apply QLoRA to Gemma 4 26B MoE. Expert layer LoRA strategies, Dense vs MoE comparison, MoE-specific training tips, and Ollama deployment. LoRA Series Part 4.

Gemma 4 — Google's Open Model That Rewrites the Rules
First Gemma model under Apache 2.0. Arena #3 overall. 31B Dense, 26B MoE (3.8B active), E4B/E2B edge models. AIME 89.2%, Codeforces ELO 2150, 256K context, multimodal.