MiniMax M2.5: 1시간 1달러로 Opus급 성능을 쓰는 시대
MiniMax M2.5는 230B MoE 아키텍처에서 10B만 활성화하여 SWE-bench 80.2%를 달성합니다. Claude Opus의 1/20 가격에 동등한 코딩 성능. Forge RL 프레임워크, 벤치마크 분석, 가격 비교.
MiniMax M2.5: 1시간 1달러로 Opus급 성능을 쓰는 시대
2026년 2월 12일, 상하이의 AI 스타트업 MiniMax가 M2.5를 공개했습니다. SWE-bench Verified 80.2%, BrowseComp 76.3%, Multi-SWE-Bench 51.3%. Claude Opus 4.6의 0.6%p 이내이면서, 가격은 1/20 수준입니다.
모델은 오픈 웨이트로 Hugging Face에 공개되었고, modified MIT 라이선스를 사용합니다. 230B 파라미터 MoE 아키텍처에서 추론 시 10B만 활성화합니다. 100 TPS(tokens per second)의 Lightning 변종을 1시간 연속 실행해도 비용은 1달러입니다.
이 글에서는 M2.5의 아키텍처, 학습 방법론, 벤치마크 성능, 가격 구조를 분석하고, 이것이 AI 산업에 어떤 의미인지를 살펴봅니다.
아키텍처: 230B인데 10B만 쓴다
MiniMax M2.5는 Mixture of Experts(MoE) 아키텍처입니다.
| 항목 | 수치 |
|---|---|
| 총 파라미터 | 230B (2,300억) |
| 활성 파라미터 | 10B (100억) — 전체의 약 4% |
| 컨텍스트 윈도우 | 204,800 토큰 (~205K) |
| 학습 언어 | 13개 (Python, Go, C, C++, TypeScript, Rust, Kotlin, Java, JavaScript, PHP, Lua, Dart, Ruby) |
MoE의 핵심 아이디어: 입력 토큰마다 전체 파라미터 중 일부 "전문가"만 활성화합니다. 230B의 지식 용량을 유지하면서, 실제 계산량은 10B 모델 수준입니다. 이것이 가격과 속도의 비밀입니다.
두 가지 변종으로 제공됩니다:
| 변종 | 속도 | 입력 (1M 토큰) | 출력 (1M 토큰) |
|---|---|---|---|
| M2.5 (Standard) | 50 TPS | $0.15 | $1.20 |
| M2.5-Lightning | 100 TPS | $0.30 | $2.40 |
Lightning은 Standard의 2배 가격에 2배 속도입니다. 성능(정확도)은 동일합니다.
Forge: Agent를 위한 강화학습 프레임워크
M2.5의 성능을 설명하는 핵심은 Forge라는 자체 강화학습(RL) 프레임워크입니다.
전통적인 LLM 학습은 "텍스트를 읽고 다음 토큰을 예측"하는 방식입니다. Forge는 다릅니다. 모델을 실제 환경에 배치하고, 작업 완료 여부로 보상을 줍니다.
학습 환경:
- 200,000개 이상의 실제 코드 저장소
- 웹 브라우저 (검색, 탐색, 정보 수집)
- 오피스 애플리케이션 (Word, Excel, PowerPoint)
- API 엔드포인트 및 도구 호출
Forge의 기술적 특징:
- CISPO(Clipping Importance Sampling Policy Optimization): MoE 모델의 대규모 RL 학습 안정성을 보장하는 알고리즘. Expert 간 gradient 불균형 문제를 해결합니다.
- Process Reward: Agent가 긴 작업(수만 토큰)을 수행할 때, 최종 결과뿐 아니라 중간 단계의 품질도 평가합니다. 이것이 긴 컨텍스트에서의 credit assignment 문제를 해결합니다.
- 비동기 스케줄링 + 트리 구조 샘플 병합: 약 40배의 학습 속도 향상을 달성했습니다.
- Trajectory 기반 속도 최적화: 같은 성능을 더 적은 토큰으로 달성하도록 학습합니다. M2.1 대비 토큰 사용량 20% 감소.
결과적으로, M2.5는 "코드를 작성할 수 있는 모델"이 아니라 "프로젝트를 설계하고 실행하는 agent"로 학습되었습니다. 코드를 쓰기 전에 아키텍처를 분석하고, 기능을 분해하고, UI를 설계하는 방식으로 접근합니다.
MiniMax 내부에서는 M2.5가 생성한 코드가 새로 커밋되는 코드의 80%를 차지한다고 합니다.
벤치마크: 숫자가 말하는 것
코딩 성능
| 벤치마크 | M2.5 | Claude Opus 4.6 | GPT-5.2 |
|---|---|---|---|
| SWE-bench Verified | 80.2% | 80.8% | 80.0% |
| Multi-SWE-Bench | 51.3% (1위) | - | - |
| Droid Harness | 79.7% | 78.9% | - |
| OpenCode Harness | 76.1% | 75.9% | - |
| SWE-bench 완료 시간 | 22.8분 | 22.9분 | - |
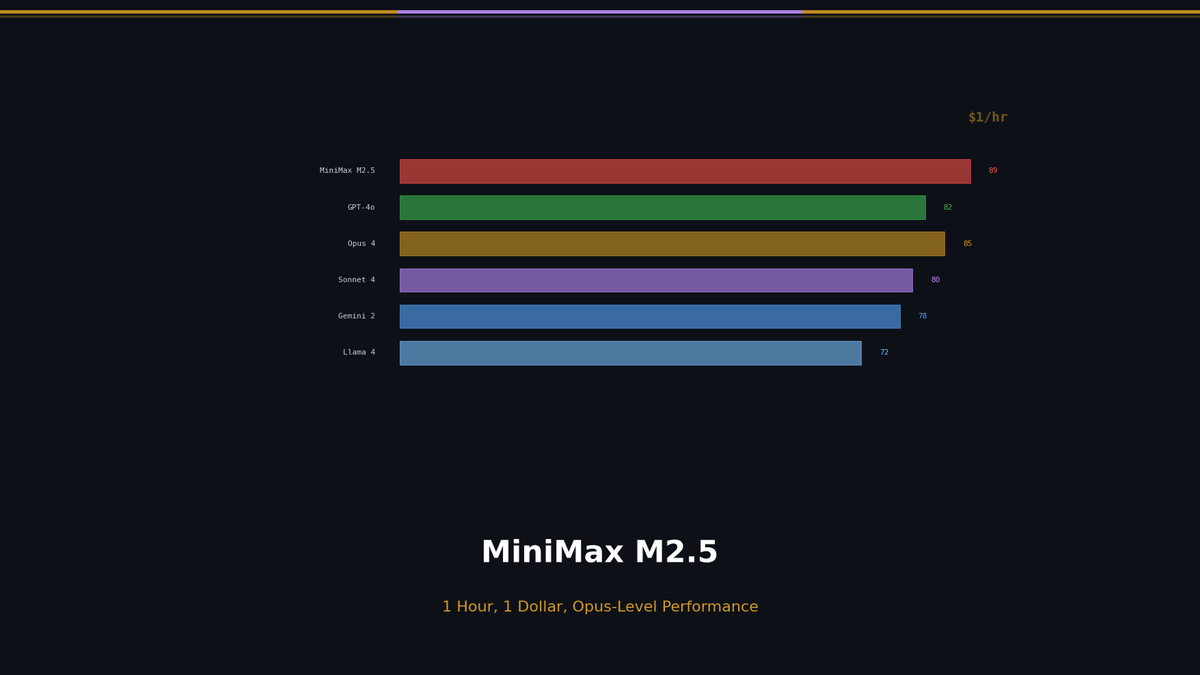
SWE-bench Verified에서 Opus 4.6과 0.6%p 차이입니다. Droid과 OpenCode 하네스에서는 오히려 M2.5가 앞섭니다. 작업 완료 시간도 Opus와 동등한 수준이며, M2.1 대비 37% 빨라졌습니다.
Multi-SWE-Bench(다국어 코딩)에서는 업계 1위입니다. 13개 프로그래밍 언어에 대한 Forge 학습의 효과가 드러납니다.
검색 및 도구 사용
| 벤치마크 | M2.5 | 비고 |
|---|---|---|
| BrowseComp | 76.3% | 컨텍스트 관리 포함 |
| BFCL (도구 호출) | 76.8% | 업계 최고 수준 |
BrowseComp는 모델이 웹을 탐색해 복잡한 질문에 답하는 벤치마크입니다. M2.5는 GPT-5.2와 Gemini 3 Pro를 모두 넘었습니다. 컨텍스트가 최대 길이의 30%를 초과하면 히스토리를 폐기하는 전략을 사용합니다.
일반 지식 및 추론
| 벤치마크 | M2.5 | Opus 4.6 |
|---|---|---|
| AIME25 (수학) | 86.3 | 95.6 |
| GPQA-D (대학원 수준) | 85.2 | 90.0 |
| SciCode (과학) | 44.4 | 52.0 |
일반 추론에서는 Opus 4.6에 뒤집니다. AIME25에서 9.3점 차이, GPQA-D에서 4.8점 차이. 이것이 M2.5의 한계입니다. 코딩과 agent 작업에서는 Opus와 대등하지만, 순수 추론 능력에서는 명확한 격차가 있습니다.
오피스 및 실무
M2.5는 Word, PowerPoint, Excel 작업을 평가하는 GDPval-MM 벤치마크에서 주류 모델 대비 59.0% 승률을 기록했습니다. MiniMax Agent를 통해 파일 유형에 따라 자동으로 Office Skills를 로드하는 기능도 제공합니다.
가격 비교: 진짜 이야기
벤치마크 숫자보다 더 충격적인 것은 가격입니다.
| 모델 | 입력 (1M) | 출력 (1M) | 대표 성능 | 비고 |
|---|---|---|---|---|
| MiniMax M2.5 | $0.15 | $1.20 | SWE-bench 80.2% | 오픈 웨이트, 50 TPS |
| MiniMax M2.5-Lightning | $0.30 | $2.40 | Standard와 동일 (속도 2배) | 100 TPS |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 제3자 지표만 | 가장 저렴한 경량 모델 |
| Gemini 3 Flash (preview) | $0.50 | $3.00 | SWE-bench 78% | 1M 컨텍스트, 64K 출력 |
| gpt-5-mini | $0.25 | $2.00 | 제3자 지표만 | OpenAI 경량 모델 |
| gpt-5.2 (Standard) | $1.75 | $14.00 | SWE-bench 80% | 플래그십 |
| Claude Sonnet 4.5 | $3.00 | $15.00 | SWE-bench 77.2% (제3자) | 추론 특화 |
| Claude Opus 4.6 | $5.00 | $25.00 | SWE-bench 80.8% | 최고 성능 |
M2.5 Standard 기준으로:
- Opus 4.6 대비: 입력 1/33, 출력 1/21. SWE-bench는 0.6%p 차이.
- GPT-5.2 대비: 입력 1/12, 출력 1/12. SWE-bench는 오히려 0.2%p 높음.
- Sonnet 4.5 대비: 입력 1/20, 출력 1/13. SWE-bench는 3%p 높음.
동일 예산($100)으로 M2.5를 쓰면, Opus 대비 20~30배 더 많은 토큰을 처리할 수 있습니다. Agent 워크플로우에서 이 차이는 "할 수 있다/없다"의 경계를 바꿉니다.
1시간 연속 실행 비용:
| 모델 | 100 TPS 기준 시간당 비용 |
|---|---|
| M2.5-Lightning | ~$1 |
| GPT-5.2 | ~$5 |
| Claude Opus 4.6 | ~$9 |
연간 4개 인스턴스 상시 운영: M2.5는 약 $10,000, Opus는 약 $200,000.
벤치마크 주의사항
SWE-bench Verified/Pro 점수를 해석할 때 중요한 맥락이 있습니다.
이 벤치마크들은 "모델 자체"의 성능이 아니라 "모델 + agent 하네스 + 도구 + 프롬프트 + 실행 횟수"의 종합 성능입니다. 같은 모델이라도 어떤 scaffold(에이전트 프레임워크)를 사용하느냐에 따라 5~10%p 차이가 날 수 있습니다.
예를 들어:
- OpenAI는 GPT-5.2의 SWE-bench Verified 80%를 발표하면서, "not plotted"로 표기하고 평가 세팅을 별도 설명합니다.
- M2.5의 80.2%는 MiniMax 자체 agent scaffold 기준입니다.
- OpenHands(제3자 프레임워크)에서 측정하면 순위가 달라질 수 있습니다.
따라서 "M2.5 = Opus"라고 단순 비교하기보다는, "동일 가격대에서 이 수준의 성능이 가능하다"는 것이 핵심입니다. 제3자 측정치(Artificial Analysis, OpenHands Index 등)와 벤더 발표 수치를 구분해서 봐야 합니다.
저가 모델 3파전: M2.5 vs Gemini 2.5 Flash vs Flash-Lite
M2.5의 가격이 충격적이라고 했지만, Google의 Gemini 라인업도 만만치 않습니다. Gemini 2.5 Flash는 밸런스형, Flash-Lite는 초저가형입니다. 세 모델의 포지셔닝이 완전히 다릅니다.
| 항목 | MiniMax M2.5 | Gemini 2.5 Flash | Gemini 2.5 Flash-Lite |
|---|---|---|---|
| 포지셔닝 | 코딩/Agent 특화 | 밸런스형 | 초저가/초고속 |
| 입력 가격 (1M 토큰) | $0.15 | $0.30 | $0.10 |
| 출력 가격 (1M 토큰) | $1.20 | $2.50 | $0.40 |
| 총 비용 (입력:출력 3:1 비율) | $0.53 | $1.08 | $0.18 |
| Intelligence Index v4.0 | 42 (상위급) | 21 (중상급) | 13 (평균 이하) |
| SWE-bench Verified | 80.2% (SOTA급) | 54% | 미공개 |
| 출력 속도 | 68 tok/s / 100 tok/s (Lightning) | 257 tok/s | 406 tok/s |
| 컨텍스트 윈도우 | 205K 토큰 | 1M 토큰 | 1M 토큰 |
| 오픈 웨이트 | O (modified MIT) | X | X |
총 비용은 입력:출력 3:1 비율(일반적인 Agent 사용 패턴)로 계산한 것입니다. M2.5는 Flash의 절반 가격이면서 Intelligence Index는 2배, SWE-bench는 1.5배입니다.
Artificial Analysis의 Intelligence Index v4.0은 GDPval-AA, Terminal-Bench Hard, SciCode, GPQA Diamond, Humanity's Last Exam 등 10개 벤치마크의 종합 점수입니다. M2.5(42)가 Flash(21)의 2배, Flash-Lite(13)의 3배입니다.
세 모델의 선택 기준:
- 복잡한 코딩, Agent 워크플로우, 고난도 추론 -> MiniMax M2.5 (성능 최우선)
- 적당한 성능 + 빠른 응답 + 넓은 컨텍스트 -> Gemini 2.5 Flash (밸런스)
- 대량의 단순 분류, 번역, 요약 -> Gemini 2.5 Flash-Lite (비용 최우선)
M2.5는 "저렴한 Opus", Flash는 "저렴한 Sonnet", Flash-Lite는 "저렴한 Haiku" 포지션입니다.
오픈 웨이트의 의미
M2.5는 modified MIT 라이선스로 Hugging Face에 공개되었습니다. 조건은 하나: 상업적 사용 시 UI에 "MiniMax M2.5"를 표시해야 합니다.
로컬 배포 옵션:
| 프레임워크 | 상태 |
|---|---|
| SGLang | 권장 |
| vLLM | 권장 |
| Transformers (HuggingFace) | 지원 |
| KTransformers | 지원 |
| Ollama (GGUF) | 커뮤니티 지원 |
230B MoE이지만 활성 파라미터가 10B이므로, 적절한 양자화를 적용하면 소비자 GPU에서도 실행 가능합니다. Unsloth에서 GGUF 양자화 버전을 제공하고 있습니다.
이것이 중요한 이유: Opus 4.6급 코딩 성능을 API 호출 없이, 자체 인프라에서, 데이터를 외부로 보내지 않고 실행할 수 있습니다. 기업 보안 요구사항이 있는 환경에서 의미 있는 선택지가 됩니다.
한계와 주의점
M2.5는 만능이 아닙니다. 명확한 약점들이 있습니다.
순수 추론 성능의 격차: AIME25 86.3 vs Opus 95.6, GPQA-D 85.2 vs 90.0. 수학적 추론과 과학 문제에서는 서양 플래그십 모델에 확실히 뒤집니다.
실사용 이슈 (OpenHands 리포트 기준):
- 잘못된 git 브랜치를 타깃하는 경우가 있음
- 지시사항 누락 (특정 마크업 태그를 쓰라는 지시를 무시)
- 일관성이 떨어지는 instruction following
Agent scaffold 의존성: 벤치마크 성능이 scaffold에 크게 의존합니다. MiniMax의 자체 scaffold에서는 80.2%이지만, 다른 프레임워크에서는 다를 수 있습니다.
중국 기업 리스크: 데이터 주권, 규제 환경 변화, 서비스 안정성 등 비기술적 고려사항이 있습니다. 오픈 웨이트이므로 로컬 배포로 일부 완화 가능합니다.
무엇이 바뀌었나
M2.5는 "Intelligence too cheap to meter"라는 슬로건을 내세웁니다. 핵전력이 "too cheap to meter"가 될 것이라는 1954년의 예측을 빗댄 것입니다.
과장된 슬로건이지만, 방향성은 맞습니다:
- Opus급 코딩 성능이 1/20 가격에 가능해졌습니다.
- 오픈 웨이트 모델이 처음으로 Claude Sonnet 수준을 넘었습니다 (OpenHands 기준).
- 4% 파라미터 활성화(230B 중 10B)로 프론티어 성능을 달성한 것은 MoE 아키텍처의 효율성을 증명합니다.
- Forge의 "환경에서 학습" 패러다임은 Agent 시대에 맞는 학습 방법론을 제시합니다.
6개월 전이라면 "SWE-bench 80%는 Opus에서만 가능"이었습니다. 지금은 $0.15/M 입력 토큰으로 가능합니다.
AI 모델의 가격-성능 곡선이 무어의 법칙보다 빠르게 떨어지고 있습니다. M2.5는 그 곡선의 최신 데이터 포인트입니다.
핵심 정리
| 항목 | 내용 |
|---|---|
| 모델명 | MiniMax M2.5 / M2.5-Lightning |
| 아키텍처 | 230B MoE, 10B 활성 파라미터 |
| 컨텍스트 | 204,800 토큰 |
| 가격 (Standard) | $0.15/M 입력, $1.20/M 출력 |
| 가격 (Lightning) | $0.30/M 입력, $2.40/M 출력 |
| SWE-bench Verified | 80.2% (Opus 4.6: 80.8%) |
| 오픈 웨이트 | Modified MIT 라이선스 |
| 학습 | Forge RL, 200K+ 실환경, CISPO 알고리즘 |
| 속도 | 50 TPS (Standard), 100 TPS (Lightning) |
| 핵심 강점 | 코딩, Agent, 검색, 오피스 작업 |
| 핵심 약점 | 순수 추론 (수학, 과학) |
참고 자료
- MiniMax, "MiniMax M2.5: Built for Real-World Productivity." MiniMax News, 2026.
- OpenHands, "MiniMax M2.5: Open Weights Models Catch Up to Claude Sonnet." OpenHands Blog, 2026.
- Artificial Analysis, "MiniMax-M2.5 - Intelligence, Performance & Price Analysis." 2026.
- MiniMaxAI, "MiniMax-M2.5." Hugging Face Model Card, 2026.
- VentureBeat, "MiniMax's new open M2.5 and M2.5 Lightning near state-of-the-art while costing 1/20th of Claude Opus 4.6." 2026.
이메일로 받아보기
관련 포스트
Gemma 4 MoE 파인튜닝 — 3.8B 활성 파라미터로 Arena #6 성능 커스터마이징
Gemma 4 26B MoE 모델에 QLoRA 적용. Expert 레이어 LoRA 전략, Dense 대비 비교, MoE 전용 학습 팁, Ollama 배포까지. LoRA 시리즈 Part 4.

Gemma 4 — 구글이 Apache 2.0으로 풀어놓은 오픈 모델의 새 기준
Gemma 시리즈 최초 Apache 2.0 라이선스. Chatbot Arena 전체 3위. 31B Dense, 26B MoE(3.8B 활성), E4B/E2B 에지 모델까지. AIME 89.2%, Codeforces ELO 2150, 256K 컨텍스트, 멀티모달.

MIRAGE — 멀티모달 AI는 정말로 이미지를 "보고" 있을까?
GPT-5.1, Gemini 3 Pro, Claude Opus 4.5가 이미지 없이도 벤치마크 점수의 70-80%를 유지. 3B 텍스트 전용 모델이 흉부 X-ray 벤치마크에서 모든 멀티모달 모델과 방사선과 전문의를 능가. 스탠포드 MIRAGE 논문 리뷰.