AI Agent 첫걸음 — ReAct 패턴으로 LLM이 행동하게 만들기
Agent의 기초 ReAct 패턴을 이해합니다. 챗봇과 Agent의 차이, Thought-Action-Observation 루프, 그리고 프로덕션에서 ReAct가 부족한 이유.
AI Agent 첫걸음 — ReAct 패턴으로 LLM이 행동하게 만들기
ChatGPT에게 "오늘 서울 날씨 알려줘"라고 하면? "저는 실시간 정보에 접근할 수 없습니다." 하지만 Agent라면 날씨 API를 호출하고, 결과를 해석해서, 자연어로 답을 줍니다. 이 차이가 챗봇과 에이전트를 가르는 핵심입니다.
이 글에서는 Agent의 가장 기본이 되는 ReAct 패턴을 이해하고, 순수 Python으로 직접 구현한 뒤, 왜 Tool Calling으로 진화했는지까지 다룹니다.
시리즈: Part 1 (이 글) | Part 2: LangGraph + Reflection | Part 3: MCP + Multi-Agent | Part 4: 프로덕션 배포
챗봇 vs Agent: 무엇이 다른가?
대부분의 LLM 애플리케이션은 "챗봇"입니다. 사용자가 질문하면 모델이 학습된 지식으로 답변합니다. Input → Output, 끝.
Agent는 다릅니다. LLM이 도구(Tools)를 사용해서 외부 세계와 상호작용합니다. 검색하고, 계산하고, API를 호출하고, 데이터베이스를 조회합니다. 그리고 그 결과를 바탕으로 다음 행동을 스스로 결정합니다.
| 구분 | 챗봇 | Agent |
|---|---|---|
| 동작 방식 | Input → LLM → Output | Input → LLM → Tool → Observation → ... → Output |
| 지식 범위 | 학습 데이터에 한정 | 실시간 정보 접근 가능 |
| 외부 연동 | 불가능 | API, DB, 파일 시스템 등 연동 |
| 의사결정 | 단일 응답 | 다단계 추론 및 행동 |
| 오류 대응 | 없음 | 재시도, 대안 도구 선택 가능 |
핵심 인사이트: Agent = LLM + Tools + Loop. LLM이 "무엇을 할지" 판단하고, Tool이 "실제 행동"을 수행하고, Loop가 "완료될 때까지" 반복합니다.
ReAct: Reasoning + Acting
2022년 Yao et al.이 발표한 ReAct(Reasoning and Acting) 논문은 LLM Agent의 기초를 놓았습니다. 핵심 아이디어는 단순합니다: LLM이 생각(Thought)하고 행동(Action)하는 과정을 번갈아 반복하게 만드는 것입니다.
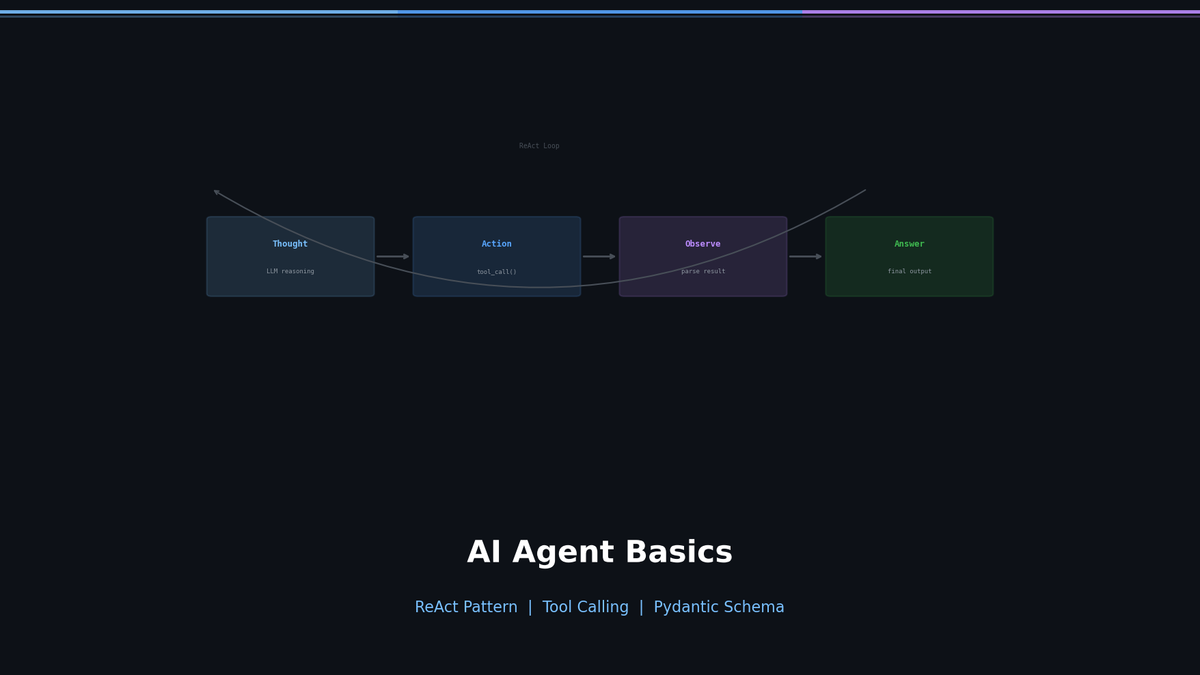
Thought → Action → Observation 루프
ReAct 에이전트는 세 단계를 반복합니다:
- Thought — "지금 상황에서 무엇을 해야 하는가?" 추론합니다
- Action — 적절한 도구를 선택하고 실행합니다
- Observation — 도구의 결과를 받아 다음 판단에 활용합니다
사용자: "테슬라 현재 주가와 시가총액을 알려줘"
Thought: 테슬라의 현재 주가를 검색해야 합니다.
Action: search["Tesla current stock price"]
Observation: Tesla (TSLA) is currently trading at $248.50...
Thought: 주가를 찾았습니다. 이제 시가총액을 계산해야 합니다.
Action: search["Tesla market cap 2024"]
Observation: Tesla's market capitalization is $792 billion...
Thought: 두 정보를 모두 찾았으므로 답변할 수 있습니다.
Final Answer: 테슬라의 현재 주가는 $248.50이며, 시가총액은 약 7,920억 달러입니다.이 패턴이 강력한 이유는 추론 과정이 투명하다는 것입니다. 모델이 왜 그런 행동을 했는지, 중간 결과가 무엇이었는지 전부 볼 수 있습니다.
직접 만드는 ReAct Agent
이론은 충분합니다. 순수 Python과 OpenAI API만으로 ReAct Agent를 구현해봅시다.
1단계: 도구 정의
먼저 Agent가 사용할 도구를 만듭니다.
import math
import requests
def search(query: str) -> str:
"""웹 검색을 시뮬레이션합니다."""
# 실제로는 Tavily, SerpAPI 등을 사용합니다
responses = {
"서울 날씨": "서울 현재 기온 22°C, 맑음, 습도 45%",
"파이썬 최신 버전": "Python 3.13.0 (2024년 10월 릴리스)",
}
return responses.get(query, f"'{query}'에 대한 검색 결과가 없습니다.")
def calculate(expression: str) -> str:
"""수학 표현식을 계산합니다."""
try:
result = eval(expression, {"__builtins__": {}}, {"math": math})
return str(result)
except Exception as e:
return f"계산 오류: {e}"
# 도구 레지스트리
TOOLS = {
"search": search,
"calculate": calculate,
}2단계: 시스템 프롬프트
ReAct 패턴의 핵심은 시스템 프롬프트입니다. LLM에게 "어떤 형식으로 생각하고 행동할지" 명확히 알려줘야 합니다.
SYSTEM_PROMPT = """You are a helpful assistant that can use tools to answer questions.
Available tools:
- search[query]: Search the web for information
- calculate[expression]: Evaluate a mathematical expression
You MUST follow this exact format for each step:
Thought: <your reasoning about what to do next>
Action: <tool_name>[<argument>]
After receiving an Observation, continue with another Thought/Action,
or provide your final response:
Thought: <I now have enough information>
Final Answer: <your complete answer to the user>
Always think step by step. Use tools when you need external information."""3단계: Agent 루프 구조
나머지 구현은 두 가지입니다: LLM 응답에서 Action을 파싱하는 것, 그리고 이 전체를 루프로 엮는 것입니다. 구조를 의사코드로 보면:
def react_agent(question):
messages = [system_prompt, user_question]
반복 (최대 5회):
response = LLM(messages)
if "Final Answer" in response:
return 최종 답변
if "Action: tool[arg]" in response:
result = 도구 실행(tool, arg)
messages에 Observation 추가
return "최대 반복 초과"핵심은 LLM의 텍스트 출력에서 정규표현식으로 Action을 추출한다는 것입니다. 이 접근법은 작동하지만, 프로덕션에서 심각한 문제를 일으킵니다 (뒤에서 다룹니다).
이 Agent에 "서울 날씨가 어때? 화씨로 변환해줘"라고 물으면 이런 결과가 나옵니다:
--- Step 1 ---
Thought: 서울의 현재 날씨를 검색해야 합니다.
Action: search[서울 날씨]
Observation: 서울 현재 기온 22°C, 맑음, 습도 45%
--- Step 2 ---
Thought: 서울 기온은 22°C입니다. 화씨로 변환하겠습니다. 공식: F = C * 9/5 + 32
Action: calculate[22 * 9/5 + 32]
Observation: 71.6
--- Step 3 ---
Thought: 모든 정보를 얻었습니다.
Final Answer: 서울의 현재 날씨는 맑음이며, 기온은 22°C (71.6°F), 습도는 45%입니다.Thought → Action → Observation이 자연스럽게 이어지면서 최종 답에 도달합니다.
ReAct의 한계 — 왜 이대로는 안 되는가
위 Agent는 데모에서 잘 동작합니다. 하지만 프로덕션에 올리려면 치명적인 문제들이 있습니다.
| 문제 | ReAct (텍스트 파싱) | 해결책 |
|---|---|---|
| 형식 보장 | LLM이 형식을 어길 수 있음 | ? |
| 타입 안전성 | 모든 인자가 문자열 | ? |
| 다중 인자 | 파싱 규칙이 복잡해짐 | ? |
| 에러 처리 | 수동 구현 필요 | ? |
| 병렬 호출 | 불가능 | ? |
예를 들어, LLM이 Action: search[ 서울 날씨 ] (공백 추가)나 action: search[서울 날씨] (소문자)로 형식을 살짝 바꾸면 정규표현식 파싱이 깨집니다. Action: calculate[len([1,2,3])] 같은 중첩 괄호도 파싱 불가능합니다.
이 모든 문제를 해결하는 것이 Tool Calling — OpenAI의 Function Calling API와 Pydantic을 결합한 구조화된 접근법입니다. Part 2에서 이 진화를 다룹니다.
언제 Agent를 써야 하는가?
Agent는 강력하지만 만능이 아닙니다. 불필요한 곳에 Agent를 도입하면 복잡성만 높아집니다.
Agent가 필요한 경우
- 실시간 정보가 필요할 때: 날씨, 주가, 뉴스 등 실시간 데이터 조회
- 다단계 추론이 필요할 때: "A를 조회하고, 그 결과로 B를 계산해서, C와 비교해줘"
- 외부 시스템과 연동할 때: DB 조회, API 호출, 파일 읽기/쓰기
- 사용자 의도가 다양할 때: 하나의 인터페이스로 여러 기능을 제공해야 하는 경우
Agent가 불필요한 경우
- 단순 Q&A: 학습 데이터로 충분히 답변 가능한 질문
- 고정된 파이프라인: 입력 → 처리 → 출력이 항상 동일한 워크플로우
- 지연 시간이 중요할 때: 도구 호출은 추가 latency를 발생시킵니다
- 비용이 민감할 때: 루프를 돌 때마다 API 호출 비용이 발생합니다
질문이 들어왔을 때 의사결정 플로우:
외부 정보가 필요한가? ─── No ──→ 일반 LLM 호출
│
Yes
↓
단일 API 호출로 충분한가? ─── Yes ──→ 단순 함수 호출
│
No
↓
다단계 추론이 필요한가? ─── No ──→ RAG 파이프라인
│
Yes
↓
Agent 도입다음 편: Tool Calling + LangGraph + Reflection
Part 1에서는 Agent의 기초 — ReAct 패턴의 개념과 구조를 다뤘습니다. Part 2부터 본격적인 구현입니다:
- Tool Calling 구현 — ReAct의 정규표현식 파싱을 Pydantic + Function Calling으로 교체
- LangGraph — 에이전트 워크플로우를 그래프로 구조화
- Self-Critique (Reflection) — 에이전트가 자기 출력을 스스로 검증하고 개선
- Planning Agent — 복잡한 태스크를 단계별로 분해하고 실행
Part 3에서는 MCP + Multi-Agent, Part 4에서는 Guardrails + Docker 배포까지 다룹니다.
참고 자료
이메일로 받아보기
관련 포스트
LLM 추론 최적화 Part 4 — 프로덕션 서빙
vLLM과 TGI로 프로덕션 배포. Continuous Batching, Speculative Decoding, 메모리 버짓 설계, 처리량 벤치마크.
LLM 추론 최적�� Part 3 — Sparse Attention 실전
Sliding Window, Sink Attention, DeepSeek DSA, IndexCache, Nvidia DMS. 동적 토큰 선별부터 Needle-in-Haystack 평가까지.
LLM 추론 최적화 Part 2 — KV Cache 최적화
KV Cache 양자화(int8/int4), PCA 압축(KVTC), PagedAttention(vLLM). 실전 메모리 절감 코드와 시나리오별 설정 가이드.