GPT-4o가 유독 빠른 이유: 멀티모달과 옴니(Omni) 모델의 결정적 차이
파이프라인 방식(STT→LLM→TTS)의 텍스트 병목 문제와 옴니 모델의 네이티브 토큰 융합 방식을 토큰 수준에서 비교 분석합니다. GPT-4o와 MiniCPM-o가 빠른 진짜 이유를 설명합니다.

GPT-4o가 유독 빠른 이유: 멀티모달과 옴니(Omni) 모델의 결정적 차이
GPT-4o가 나왔을 때 많은 사람이 놀란 건 성능이 아니었습니다. 속도였습니다. 음성으로 질문하면 거의 실시간으로 대답하고, 목소리에 감정까지 실립니다. 기존 음성 AI와는 차원이 다릅니다.
그리고 MiniCPM-o 4.5가 9B 파라미터로 이 GPT-4o급 성능을 따라잡았습니다. 어떻게?
답은 "옴니(Omni) 아키텍처"에 있습니다. 더 정확히 말하면, 서로 다른 모달리티의 데이터를 어떻게 토큰화(tokenize)하고 하나의 모델 안에서 섞는가에 있습니다.
이 글에서는 파이프라인 방식과 네이티브 옴니 방식의 차이를 토큰 수준에서 파헤치겠습니다.
파이프라인 방식: 왜 느리고, 왜 어색한가
2024년 이전까지 "음성 AI"는 대부분 이런 구조였습니다:
사용자 음성 → [Whisper] → 텍스트 → [LLM] → 텍스트 → [TTS] → AI 음성세 개의 독립된 모델이 순차적으로 처리합니다. 각 단계에서 무슨 일이 벌어지는지 봅시다.
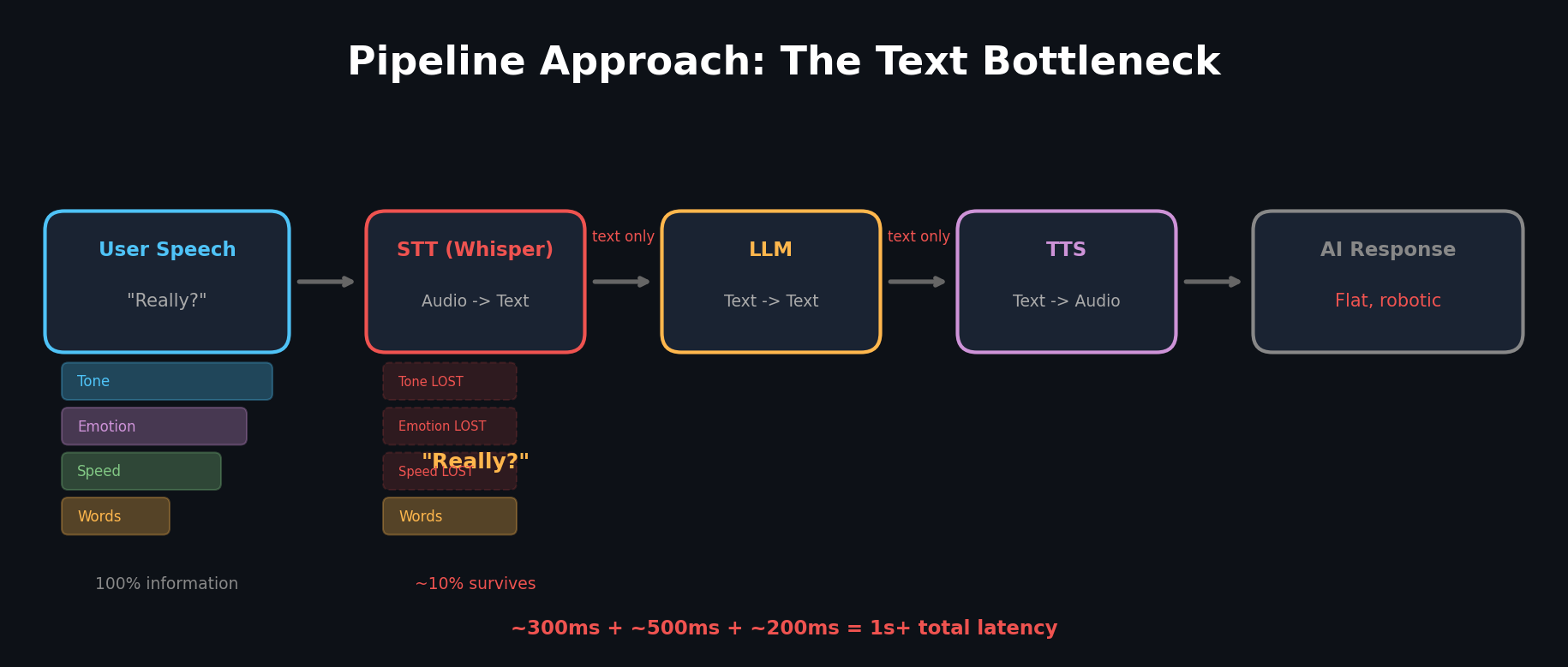
1단계: 음성 → 텍스트 (STT)
Whisper 같은 STT 모델이 음성을 텍스트로 변환합니다. 여기서 첫 번째 정보 손실이 발생합니다.
사용자가 "정말요?" 라고 말했다고 합시다. 이 한마디에도 풍부한 정보가 담겨 있습니다:
- 놀라움의 톤 (음높이가 올라감)
- 약간의 의심 (특정 억양 패턴)
- 말하는 속도 (빠르면 흥분, 느리면 의심)
STT는 이 모든 걸 "정말요?" 라는 텍스트 4글자로 압축합니다. 톤, 감정, 속도, 화자의 특성 전부 사라집니다.
2단계: 텍스트 → 텍스트 (LLM)
LLM은 "정말요?" 라는 텍스트만 받습니다. 놀라서 한 말인지, 비꼬는 건지, 진심으로 궁금한 건지 구분할 수 없습니다. 문맥에서 추측할 뿐이죠.
3단계: 텍스트 → 음성 (TTS)
LLM이 생성한 텍스트를 TTS가 읽어줍니다. 그런데 TTS도 "어떤 감정으로 읽을지" 정보가 없습니다. 결과적으로 무미건조한 음성이 나옵니다.
근본적인 문제: 텍스트 병목
이 구조의 근본적인 문제는 텍스트가 병목(bottleneck)이라는 겁니다.
인간의 대화에서 텍스트(단어 자체)가 전달하는 정보는 전체의 일부에 불과합니다. 심리학에서는 대화에서 비언어적 요소(톤, 속도, 표정 등)가 감정 전달의 90% 이상을 차지한다고 봅니다.
파이프라인에서는 이 90%가 STT 단계에서 증발합니다.
그리고 지연시간(latency) 문제도 있습니다. 세 모델이 순차 실행되니까:
- STT: ~300ms
- LLM: ~500ms (첫 토큰까지)
- TTS: ~200ms
- 합계: ~1초 이상
자연스러운 대화에서 1초 지연은 매우 부자연스럽습니다. 전화 통화에서 0.5초만 지연돼도 "여보세요? 들리세요?" 하게 되는 걸 생각해보세요.
옴니(Omni) 방식: 모든 것을 토큰으로
GPT-4o와 MiniCPM-o가 이 문제를 어떻게 해결했는지 봅시다.
핵심 아이디어는 간단합니다: 텍스트, 음성, 이미지를 모두 같은 형식의 토큰으로 변환한 뒤, 하나의 트랜스포머에서 함께 처리합니다.

사용자 음성 + 영상 → [통합 인코더] → 혼합 토큰 시퀀스 → [하나의 LLM] → 혼합 토큰 → [디코더] → AI 음성 + 텍스트파이프라인과의 결정적 차이: 중간에 텍스트로 압축하는 단계가 없습니다.
각 모달리티의 토큰화 방법
옴니 모델이 서로 다른 데이터를 어떻게 "토큰"으로 만드는지 구체적으로 봅시다.
텍스트 토큰화: 이건 이미 잘 알려져 있습니다
텍스트는 BPE(Byte Pair Encoding)나 SentencePiece로 토큰화합니다. "안녕하세요"가 토큰 몇 개로 분리되고, 각 토큰이 정수 ID로 매핑되는 방식입니다. 여기서 혁신은 없습니다.
이미지 토큰화: 패치를 임베딩으로
이미지는 ViT(Vision Transformer) 계열 인코더가 처리합니다. MiniCPM-o의 경우 SigLip2를 사용합니다.
과정은 이렇습니다:
- 이미지를 작은 패치(예: 14x14 픽셀)로 분할
- 각 패치를 선형 투사(linear projection)로 벡터화
- 위치 임베딩(position embedding) 추가
- 트랜스포머 인코더 통과 → 시각 토큰(visual tokens) 생성
핵심: 해상도가 높을수록 패치 수가 많아지고, 따라서 시각 토큰 수도 많아집니다. SigLip2가 최대 180만 픽셀을 처리할 수 있다는 것은, 그만큼 세밀한 시각 토큰을 생성한다는 뜻입니다. OCR 성능이 뛰어난 이유가 바로 여기에 있습니다.
음성 토큰화: 여기가 핵심
음성 토큰화에는 크게 두 가지 접근이 있습니다.
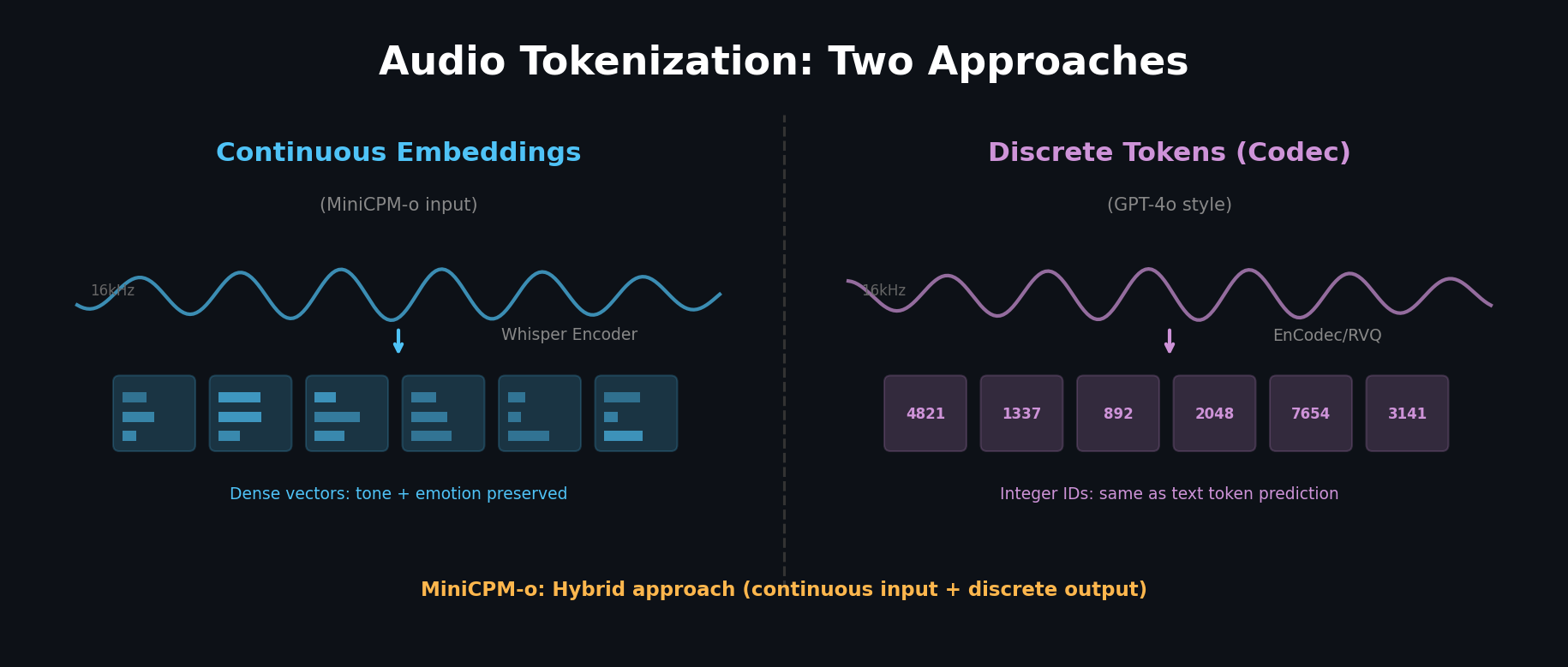
방법 1: 연속 임베딩 (Continuous Embeddings)
Whisper 같은 인코더를 사용해 오디오를 연속적인 벡터 시퀀스로 변환합니다.
- 16kHz 오디오 → 멜 스펙트로그램 → 인코더 → 임베딩 시퀀스
- 장점: 음성의 풍부한 정보(톤, 감정, 속도)가 벡터에 보존됨
- MiniCPM-o가 음성 입력에 사용하는 방식입니다
방법 2: 이산 토큰 (Discrete Tokens)
오디오 코덱(EnCodec, SoundStream 등)을 사용해 음성을 이산적인 토큰 시퀀스로 변환합니다.
- 16kHz 오디오 → 코덱 인코더 → 이산 토큰 ID 시퀀스
- RVQ(Residual Vector Quantization)로 여러 레벨의 코드북 사용
- 장점: 텍스트 토큰과 동일한 방식으로 다음 토큰 예측 가능
- GPT-4o가 사용하는 것으로 추정되는 방식입니다
MiniCPM-o는 두 방식을 조합합니다:
- 입력: Whisper의 연속 임베딩
- 출력: Streaming Flow Matching Decoder + Interleaved Speech Token Decoder
- 이 하이브리드 접근이 Full-Duplex(동시 입출력)를 가능하게 합니다
토큰이 LLM 안에서 만나는 순간
가장 중요한 부분입니다. 서로 다른 모달리티의 토큰들이 하나의 트랜스포머 안에서 어떻게 처리될까요?
[시각토큰1][시각토큰2]...[시각토큰N][음성토큰1][음성토큰2]...[텍스트토큰1][텍스트토큰2]...이 혼합 시퀀스가 통째로 트랜스포머의 셀프 어텐션(self-attention)을 거칩니다. 이 때:
- 음성 토큰이 시각 토큰에 어텐션할 수 있습니다
- 텍스트 토큰이 음성 토큰에 어텐션할 수 있습니다
- 모든 모달리티가 서로를 직접 참조합니다
파이프라인에서는 불가능한 일입니다. "이 그림을 보면서 설명해줘"라고 음성으로 요청하면, 옴니 모델은 음성의 톤과 이미지의 내용을 동시에 참조해서 응답을 생성합니다.
차원 정렬: 모든 토큰이 같은 언어를 말하게
서로 다른 인코더에서 나온 토큰들의 차원이 다를 수 있습니다. SigLip2의 출력 차원과 Whisper의 출력 차원, Qwen3의 임베딩 차원이 모두 다릅니다.
이를 맞추기 위해 프로젝션 레이어(projection layer)를 사용합니다:
시각 토큰 (SigLip2 출력) → Linear Projection → LLM 차원으로 변환
음성 토큰 (Whisper 출력) → Linear Projection → LLM 차원으로 변환
텍스트 토큰 → 임베딩 테이블 → LLM 차원이 프로젝션이 핵심입니다. 서로 다른 모달리티의 토큰들이 동일한 벡터 공간에 매핑되면, 트랜스포머는 이들을 구분 없이 처리할 수 있습니다. 마치 한국어와 영어가 같은 임베딩 공간에 매핑되면 번역 없이 이해할 수 있는 것과 비슷합니다.
Full-Duplex: 동시에 듣고 말하기
MiniCPM-o의 Full-Duplex 기능은 이 토큰화 아키텍처의 정점입니다.
기존 음성 AI는 반이중(half-duplex)입니다. VAD(Voice Activity Detection)로 사용자가 말하는지 감지하고, 말이 끝나면 응답합니다. 사용자가 끼어들 수 없습니다.
Full-Duplex에서는:
- 사용자 음성이 실시간으로 토큰화되어 모델에 입력됨
- 모델이 응답 토큰을 생성하는 동시에 새로운 입력 토큰을 받음
- 사용자가 끼어들면, 새 입력 토큰이 모델의 어텐션을 통해 즉시 반영됨
- 모델이 "아, 사용자가 끼어들었구나"를 인식하고 응답을 중단하거나 수정
이것이 가능한 이유는 입력과 출력이 모두 같은 토큰 공간에 있기 때문입니다. 파이프라인에서는 STT가 완전히 끝나야 LLM이 시작되니까, 구조적으로 Full-Duplex가 불가능합니다.
왜 9B로 충분한가
"그래도 9B가 GPT-4o를 어떻게?" 라는 의문이 남습니다.
1. 전문가 인코더의 힘
MiniCPM-o의 9B는 순수 LLM 파라미터입니다. 여기에 SigLip2(비전), Whisper(음성) 같은 사전학습된 전문가 인코더가 추가됩니다. 이들은 각자의 도메인에서 이미 수억 개의 데이터로 학습된 모델들입니다.
LLM은 "사고"만 하면 됩니다. 보는 건 SigLip2가, 듣는 건 Whisper가 해주니까요. 9B의 추론 능력이면 이 정보들을 종합하기에 충분합니다.
2. 토큰 효율성
파이프라인 방식에서는 음성 정보가 텍스트로 압축되면서 정보가 손실됩니다. 옴니 방식에서는 풍부한 토큰이 직접 들어가므로, 같은 파라미터로 더 많은 정보를 활용할 수 있습니다.
비유하자면: 파이프라인은 풀컬러 사진을 흑백으로 변환한 뒤 분석하는 것이고, 옴니는 풀컬러 그대로 분석하는 것입니다.
3. End-to-End 최적화
파이프라인의 각 모듈은 독립적으로 학습됩니다. STT는 "음성을 정확한 텍스트로" 변환하는 데만 최적화되어 있고, LLM의 필요를 모릅니다.
옴니 모델에서는 전체 시스템이 end-to-end로 최적화됩니다. 음성 인코더는 "LLM이 이해하기 좋은 형태"로 음성을 토큰화하도록 학습됩니다. 이 정렬(alignment)이 작은 모델에서도 높은 성능을 가능하게 합니다.
실무에서의 의미: 왜 이게 중요한가
보안이 중요한 데이터 처리
계약서를 음성으로 설명받으면서 동시에 문서 이미지를 분석하는 시나리오를 생각해봅시다.
파이프라인 방식: 음성 → 외부 STT API → 텍스트 → 외부 LLM API → 외부 TTS API. 민감한 계약 내용이 여러 외부 서비스를 거칩니다.
옴니 모델: 로컬에서 음성, 문서 이미지를 한 번에 처리. 데이터가 디바이스를 떠나지 않습니다. MiniCPM-o의 11GB VRAM이면 충분합니다.
실시간 통역
통역에서 0.5초 차이는 대화의 흐름을 바꿉니다.
파이프라인: 음성인식(300ms) + 번역(500ms) + 음성합성(200ms) = 최소 1초 지연
옴니 모델: 음성 토큰 → 즉시 번역된 음성 토큰 출력. TTFT 0.6초
멀티모달 분석
"이 X-ray 사진에서 이상한 점이 보이는데, 설명해주세요" — 음성으로 요청하면서 이미지를 보여주는 상황.
파이프라인에서는 음성과 이미지가 별개로 처리됩니다. 옴니 모델에서는 "이상한 점"이라는 음성 토큰과 X-ray 이미지 토큰이 어텐션을 통해 직접 연결됩니다. "어디가 이상한데?"라는 맥락을 음성 톤에서도 읽어냅니다.
현재 한계와 앞으로의 방향
솔직하게 현재 한계도 짚겠습니다.
토큰 수 폭발 문제
고해상도 이미지 + 긴 음성을 동시 입력하면 토큰 수가 급격히 증가합니다. 180만 픽셀 이미지의 시각 토큰 + 30초 음성의 오디오 토큰을 합치면 수천 개가 됩니다. 트랜스포머의 셀프 어텐션은 토큰 수의 제곱에 비례하는 연산량이 필요하므로, 이것이 병목이 될 수 있습니다.
모달리티 간 간섭
한 트랜스포머에서 모든 모달리티를 처리하면, 한 모달리티의 학습이 다른 모달리티의 성능을 떨어뜨리는 "간섭(interference)" 현상이 발생할 수 있습니다. MoE(Mixture of Experts)나 모달리티별 어댑터로 이를 완화하려는 연구가 진행 중입니다.
학습 데이터
옴니 모델의 학습에는 모달리티가 정렬된 데이터가 필요합니다. 예를 들어 "(이 이미지를 보면서) 이렇게 설명하세요"와 같이 이미지-음성-텍스트가 동시에 존재하는 데이터입니다. 이런 데이터는 텍스트만 있는 데이터에 비해 훨씬 희소합니다.
정리
| 항목 | 파이프라인 | 옴니(Native) |
|---|---|---|
| 정보 보존 | 텍스트로 압축, 감정/톤 손실 | 원본 정보 보존 |
| 지연시간 | 모듈 직렬 실행 (~1초+) | 단일 모델 (~0.6초) |
| Full-Duplex | 구조적으로 불가 | 가능 |
| 크로스모달 추론 | 제한적 | 어텐션으로 직접 참조 |
| 보안 | 여러 외부 API 의존 | 로컬 처리 가능 |
| 모델 크기 | 3개 모델 합산 | 단일 통합 모델 |
옴니 모델은 단순히 "여러 모달리티를 처리하는" 모델이 아닙니다. 서로 다른 감각의 토큰을 하나의 공간에서 융합하는 모델입니다.
GPT-4o가 빠른 건 "서버가 좋아서"가 아니라, 아키텍처 자체가 지연을 제거하도록 설계되었기 때문입니다. 그리고 MiniCPM-o가 9B로 이를 따라잡은 건, 이 아키텍처의 힘이 모델 크기를 넘어선다는 증거입니다.
관련 링크
- MiniCPM-o 4.5 분석: 온디바이스 GPT-4o의 등장?
- HuggingFace: openbmb/MiniCPM-o-4_5
- GitHub: OpenBMB/MiniCPM-o
이메일로 받아보기
관련 포스트

Google COSMO 해부 — 온디바이스 AI 에이전트의 새 아키텍처
Google이 실수로 공개한 차세대 AI 어시스턴트 COSMO. Gemini Nano + PI 서버 + 하이브리드 모드의 3-모드 아키텍처를 완전히 분석합니다. Google I/O 2026 직전 유출.

Gemma 4 — 구글이 Apache 2.0으로 풀어놓은 오픈 모델의 새 기준
Gemma 시리즈 최초 Apache 2.0 라이선스. Chatbot Arena 전체 3위. 31B Dense, 26B MoE(3.8B 활성), E4B/E2B 에지 모델까지. AIME 89.2%, Codeforces ELO 2150, 256K 컨텍스트, 멀티모달.

MIRAGE — 멀티모달 AI는 정말로 이미지를 "보고" 있을까?
GPT-5.1, Gemini 3 Pro, Claude Opus 4.5가 이미지 없이도 벤치마크 점수의 70-80%를 유지. 3B 텍스트 전용 모델이 흉부 X-ray 벤치마크에서 모든 멀티모달 모델과 방사선과 전문의를 능가. 스탠포드 MIRAGE 논문 리뷰.