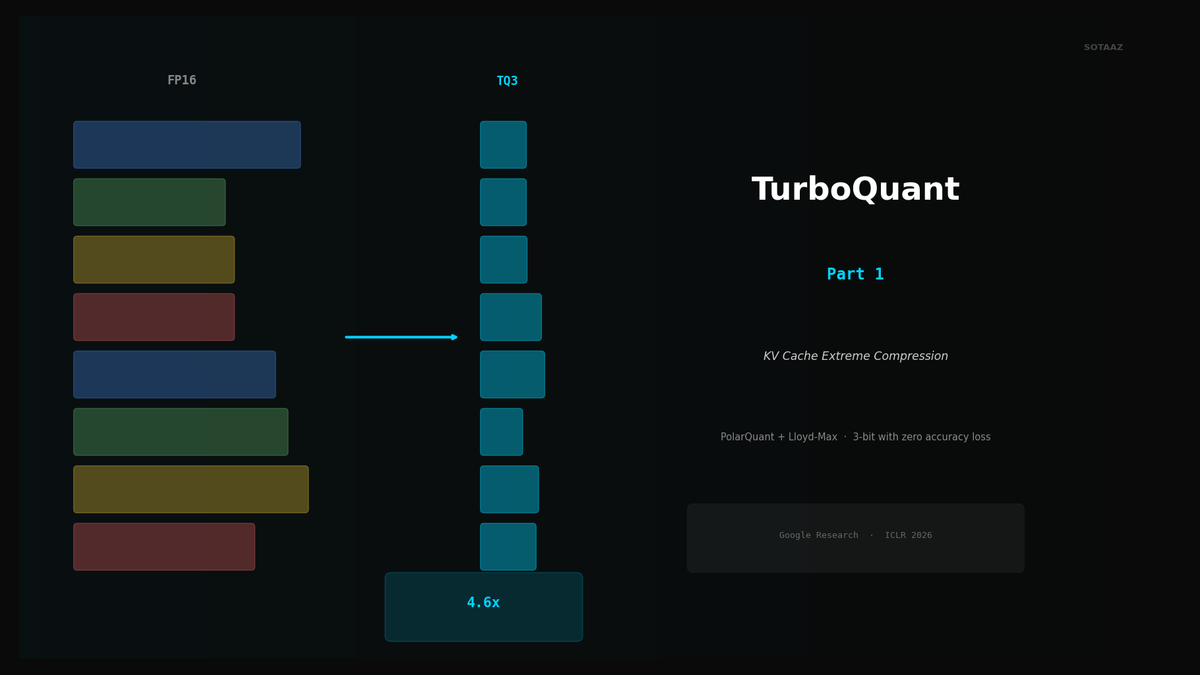
TurboQuant 완전 해부 — Google의 KV Cache 극한 압축 알고리즘
PolarQuant + Lloyd-Max로 KV Cache를 3비트까지 압축. 리트레이닝 없이 4.6배 메모리 절약, 정확도 손실 제로.
TurboQuant 완전 해부 — Google의 KV Cache 극한 압축 알고리즘
Transformer 기반 LLM의 추론 비용을 지배하는 요소는 무엇일까요? 모델 가중치? 아닙니다. 충분히 긴 컨텍스트를 다루는 순간, 진짜 병목은 KV Cache입니다.
8B 모델이 32K 토큰을 처리할 때, KV Cache만으로 약 4.6GB VRAM을 차지합니다. 70B 모델에 128K 컨텍스트라면? 수십 GB입니다. GPU 메모리의 대부분이 "이전에 계산한 Key-Value 벡터를 기억하는 데" 소모됩니다. 배치 크기를 늘리기 어렵고, 컨텍스트 길이에 천장이 생기며, 동시 사용자 수가 제한됩니다.
기존 해결책들 — vLLM의 FP8 양자화, Ollama의 q4_0/q8_0 — 은 있습니다. 하지만 FP8은 압축률이 2x에 불과하고, q4_0은 품질 저하가 눈에 띕니다. "메모리를 절반으로 줄이되, 성능은 거의 그대로"라는 양립 불가능해 보이는 요구를 충족하는 방법이 없었습니다.
Google Research가 ICLR 2026에서 발표한 TurboQuant는 이 문제에 대한 가장 우아한 답입니다. 핵심 아이디어는 놀랍도록 단순합니다: KV Cache 벡터를 랜덤 직교 회전으로 "예측 가능하게" 만든 뒤, 수학적으로 최적인 양자화를 적용하는 것. 결과는 4.6x 압축에 perplexity 차이 1.3% 이내, 속도는 오히려 2% 빠름.
이 글에서는 TurboQuant의 수학적 원리, 기존 양자화 방법과의 차이, 실전 벤치마크, 그리고 현재 생태계 현황까지 완전히 해부합니다.
왜 KV Cache가 문제인가
Transformer의 추론은 두 단계로 나뉩니다.
1단계 — Prefill: 입력 프롬프트의 모든 토큰을 한꺼번에 처리합니다. 각 어텐션 레이어에서 Key와 Value 벡터를 계산하고 저장합니다.
2단계 — Decode: 새 토큰을 하나씩 생성합니다. 매 스텝마다 이전의 모든 Key-Value 벡터를 참조해야 합니다.
문제는 2단계입니다. 생성할 때마다 KV Cache 전체를 GPU 메모리에서 읽어야 하고, 새 토큰이 생성될 때마다 Cache가 커집니다. 시퀀스 길이에 선형으로 증가합니다.
구체적인 숫자를 봅시다.
| 모델 | 컨텍스트 | KV Cache 크기 (FP16) |
|---|---|---|
| Llama 3.1 8B | 8K | ~1.2 GB |
| Llama 3.1 8B | 32K | ~4.6 GB |
| Llama 3.1 70B | 32K | ~40 GB |
| Llama 3.1 70B | 128K | ~160 GB |
70B 모델에 128K 컨텍스트를 FP16으로 유지하면 KV Cache만으로 A100 80GB 두 장을 채웁니다. 모델 가중치 올릴 메모리가 없습니다.
이것이 왜 KV Cache 양자화가 가중치 양자화만큼이나 — 어쩌면 더 — 중요한지 보여주는 이유입니다.
기존 접근법의 한계
현재 가장 널리 쓰이는 KV Cache 압축 방법들은 이렇습니다:
FP8 (vLLM 기본): 2x 압축. 단순하고 품질 저하가 적지만, 압축률이 부족합니다. 70B + 128K를 80GB 하나에 못 넣습니다.
q8_0 (Ollama): 역시 약 2x. 블록 단위 양자화로 FP8과 비슷한 수준입니다.
q4_0 (Ollama): 약 3.6x 압축. 나쁘지 않지만 perplexity 저하가 눈에 띕니다. 특히 긴 컨텍스트에서 품질이 떨어집니다.
KIVI: 2~4비트 KV Cache 양자화. 아웃라이어 채널 문제로 복잡한 처리가 필요합니다.
KVQuant: 복잡한 캘리브레이션 과정이 필요합니다. 모델마다 별도의 캘리브레이션 데이터와 시간이 요구됩니다.
TurboQuant는 이 모든 방법과 다른 접근을 택합니다. 캘리브레이션 없이(zero-shot), 수학적으로 최적인 양자화를 달성합니다.
TurboQuant 핵심 원리 — 2단계 압축
TurboQuant의 논문 제목에서 핵심이 드러납니다: PolarQuant + QJL. 두 단계의 압축을 순차적으로 적용합니다.
Stage 1: PolarQuant (b-1 bits)
PolarQuant의 출발점은 간단한 관찰입니다: 일반적인 KV Cache 벡터는 양자화하기 어렵습니다. 값의 분포가 불규칙하고, 아웃라이어가 존재하며, 채널마다 스케일이 다릅니다.
그렇다면 양자화하기 전에, 벡터의 분포를 "예측 가능하게" 바꾸면 어떨까요?
Step 1: 랜덤 직교 회전 (Walsh-Hadamard Transform)
KV Cache 벡터 v에 랜덤 직교 행렬 R을 곱합니다:
v' = R · v
왜 이것이 효과적인가? 직교 회전은 벡터의 노름(크기)을 보존하면서, 에너지를 모든 좌표에 균등하게 분배합니다. 마치 편향된 주사위를 공정한 주사위로 바꾸는 것과 같습니다.
구체적으로 Walsh-Hadamard Transform(WHT)을 사용합니다. WHT는 O(d log d)로 계산 가능하기 때문에 d x d 행렬 곱셈의 O(d^2)보다 훨씬 빠릅니다. 실시간 추론에 적용할 수 있는 이유입니다.
Step 2: 예측 가능한 분포
회전된 벡터의 각 좌표는 수학적으로 예측 가능한 분포를 따르게 됩니다.
- 저차원에서: Beta 분포
- 고차원 극한에서: Gaussian 분포 (중심극한정리에 의해)
핵심은 이 분포가 데이터에 무관하다는 것입니다. 어떤 모델이든, 어떤 입력이든, 회전 후의 분포는 동일합니다. 이것이 "캘리브레이션이 불필요한" 이유입니다.
Step 3: Lloyd-Max 최적 양자화
분포를 알고 있으니, 해당 분포에 대한 최적 양자화 버킷을 사전 계산할 수 있습니다. Lloyd-Max 알고리즘은 주어진 분포에 대해 평균 제곱 오차(MSE)를 최소화하는 양자화 경계(boundaries)와 대표값(reconstruction levels)을 찾아줍니다.
이 버킷들은 한 번만 계산하면 됩니다. 모델이 바뀌어도, 입력이 바뀌어도 같은 버킷을 재사용합니다. 룩업 테이블 하나로 양자화와 역양자화가 끝납니다.
Step 4: 극좌표 변환 (Polar Transform)
일반적인 양자화에서는 각 벡터마다 스케일(정규화 상수)을 따로 저장해야 합니다. 이 오버헤드가 저비트 양자화에서 상당합니다 — 3비트 양자화인데 스케일에 16비트를 쓰면 효율이 떨어집니다.
PolarQuant는 극좌표 변환으로 이 문제를 해결합니다. 벡터를 반경(radius)과 각도(angle)로 분리합니다:
- 반경: ||v'|| (벡터의 크기) → 별도 저장 (FP16, 벡터당 1개)
- 각도: v' / ||v'|| (단위 벡터) → Lloyd-Max로 양자화
단위 벡터의 각 좌표는 [-1, 1] 범위의 알려진 분포를 따르므로, Lloyd-Max가 최적으로 작동합니다. 정규화 상수 오버헤드가 벡터당 단 16비트로 줄어듭니다.
Stage 2: QJL 잔차 보정 (1 bit)
PolarQuant로 양자화한 후에도 잔차(residual)가 남습니다. 원래 벡터와 양자화된 벡터의 차이입니다.
TurboQuant의 두 번째 단계는 이 잔차를 1비트만 사용해서 보정합니다.
Johnson-Lindenstrauss 프로젝션
잔차 벡터 e = v - Q(v)를 랜덤 가우시안 행렬 G로 프로젝션합니다:
p = G · e
그리고 프로젝션 결과의 부호(sign)만 저장합니다:
s = sign(p) → +1 또는 -1
좌표당 정확히 1비트입니다.
왜 이것이 작동하는가?
Johnson-Lindenstrauss 보조정리(lemma)는 랜덤 프로젝션이 내적을 근사적으로 보존한다는 것을 보장합니다. 부호만 저장해도 비편향(unbiased) 내적 추정기를 얻을 수 있습니다:
E[<Q(v) + correction, u>] = <v, u>
어텐션 스코어 계산의 핵심은 Query와 Key의 내적입니다. 이 내적이 비편향으로 추정되면, 어텐션 분포가 원래와 유사하게 유지됩니다.
실전 발견: QJL은 불필요했다
여기서 이야기가 흥미로워집니다.
TurboQuant 논문이 공개된 후, llama.cpp 커뮤니티에서 여러 개발자가 독립적으로 구현을 시작했습니다. 그리고 이들은 놀랍게도 동일한 결론에 도달합니다:
"Algorithm 1 (PolarQuant/Lloyd-Max)만으로 충분하다. QJL을 빼도 perplexity가 거의 같다."
이유를 분석해보면 이렇습니다:
- PolarQuant + Lloyd-Max 자체가 이미 이론적으로 최적에 가까운 양자화입니다
- QJL의 1비트 보정은 분산(variance)을 줄이지만, 실제 perplexity 개선은 미미합니다
- QJL은 추가 메모리(프로젝션 행렬 저장)와 연산(행렬 곱)을 필요로 합니다
- QJL을 제거하면 구현이 단순해지고, 디코딩 속도가 빨라집니다
결과적으로 llama.cpp의 TurboQuant 구현(turbo3, turbo4 타입)은 PolarQuant + Lloyd-Max만 사용합니다. 논문의 Algorithm 1만으로도 기존 q4_0, q8_0을 명확히 능가합니다.
이것은 이론과 실전의 간극을 보여주는 좋은 사례입니다. 수학적으로 더 정교한 방법이 항상 실전에서 더 좋은 것은 아닙니다. 때로는 단순한 방법이 이깁니다.
기존 양자화와 비교
양자화 방법을 이해하려면 먼저 "무엇을 양자화하는가"를 구분해야 합니다.
가중치 양자화 vs KV Cache 양자화
가중치 양자화 (GPTQ, AWQ, GGUF Q4_K_M 등)는 모델의 파라미터를 압축합니다. 추론 전에 한 번 변환하고, 이후 고정입니다. 목적은 모델 로딩에 필요한 VRAM을 줄이는 것입니다.
KV Cache 양자화 (TurboQuant, KIVI, KVQuant 등)는 추론 중 생성되는 Key-Value 벡터를 실시간으로 압축합니다. 시퀀스가 길어질수록 효과가 커집니다.
핵심 포인트: 이 둘은 직교적(orthogonal)입니다. 동시에 적용할 수 있습니다. GGUF Q4_K_M으로 모델 가중치를 양자화하고, TurboQuant로 KV Cache를 양자화하면, 이중으로 메모리를 절약합니다.
방법별 비교표
| Method | 타입 | 대상 | 비트 | KV Cache 압축 | 리트레이닝 |
|---|---|---|---|---|---|
| GPTQ | 가중치 양자화 | 모델 웨이트 | 3-4bit | 아니오 | 캘리브레이션 필요 |
| AWQ | 가중치 양자화 | 모델 웨이트 | 3-4bit | 아니오 | 캘리브레이션 필요 |
| GGUF Q4_K_M | 가중치 양자화 | 모델 웨이트 | 4bit (혼합) | 아니오 | 불필요 |
| KIVI | KV Cache 양자화 | KV Cache | 2-4bit | 예 | 아웃라이어 문제 |
| KVQuant | KV Cache 양자화 | KV Cache | 2-4bit | 예 | 복잡한 캘리브레이션 |
| TurboQuant | KV Cache 양자화 | KV Cache | 3-4bit | 예 | 불필요 (제로샷) |
TurboQuant가 다른 KV Cache 양자화와 구별되는 지점은 제로샷 특성입니다. 캘리브레이션 데이터도, 모델별 튜닝도 필요 없습니다. Walsh-Hadamard 회전 후의 분포가 데이터에 무관하기 때문입니다.
KIVI는 아웃라이어 채널을 별도 처리해야 하고, KVQuant는 모델마다 최적 양자화 파라미터를 찾기 위한 캘리브레이션이 필요합니다. TurboQuant는 그런 과정 없이, 어떤 모델에든 즉시 적용 가능합니다.
벤치마크 결과
이론이 아무리 우아해도, 실전 성능이 뒷받침되지 않으면 의미가 없습니다. llama.cpp 커뮤니티에서 측정한 벤치마크 결과를 봅시다.
CPU 벤치마크: Qwen3.5-35B-A3B Q4_K_M
MoE 모델인 Qwen3.5-35B-A3B을 Q4_K_M 가중치 양자화 상태에서, KV Cache만 바꿔가며 측정한 결과입니다.
| KV Cache | Prompt (t/s) | Gen (t/s) | Context MiB | 압축률 |
|---|---|---|---|---|
| f16 | 19.3 | 10.6 | 5,182 | 1.0x |
| q8_0 | 19.9 | 10.4 | ~2,591 | 2.0x |
| q4_0 | 19.5 | 12.5 | ~1,440 | 3.6x |
| tq3_0 | 20.1 | 11.4 | 1,182 | 4.4x |
주목할 점이 여러 가지 있습니다.
첫째, tq3_0이 f16보다 빠릅니다. Prompt 처리 속도가 19.3 → 20.1 t/s로 오히려 올랐습니다. KV Cache가 작으니 메모리 bandwidth 병목이 줄어든 것입니다. CPU에서 LLM 추론은 거의 항상 memory-bound이기 때문에, 데이터 크기를 줄이면 속도가 올라갑니다.
둘째, 4.4x 압축률입니다. 5,182 MiB → 1,182 MiB. 같은 메모리로 4배 이상 긴 컨텍스트를 처리할 수 있습니다.
셋째, 생성 속도에서 q4_0이 12.5 t/s로 가장 빠르고 tq3_0은 11.4 t/s입니다. 이는 tq3_0의 양자화/역양자화 연산이 q4_0보다 약간 복잡하기 때문입니다. 하지만 압축률에서 tq3_0이 3.6x vs 4.4x로 크게 앞서고, 품질도 더 좋습니다.
Metal GPU 벤치마크: M5 Max, 최적화 후
Apple Silicon에서의 결과도 인상적입니다.
| 압축률 | PPL | Prefill tok/s | vs q8_0 | |
|---|---|---|---|---|
| q8_0 | 2.0x | 5.41 | 2694 | baseline |
| turbo3 | 4.6x | 5.46 | 2747 | 1.02x |
이 결과가 말하는 것은 명확합니다:
- 4.6x 압축인데 q8_0보다 오히려 2% 빠름
- PPL(perplexity) 차이: 5.41 → 5.46, 약 0.9% 증가
- 사실상 "공짜 점심"에 가깝습니다
왜 압축률이 높은데 더 빠를까요? 다시 한 번 memory bandwidth입니다. GPU에서도 LLM 추론의 병목은 연산이 아니라 메모리 대역폭입니다. KV Cache를 4.6배 작게 만들면, 메모리에서 읽어야 할 데이터가 줄어들고, 양자화/역양자화 연산의 추가 비용보다 대역폭 절감 효과가 더 큽니다.
실전 영향 — 70B Q4_K_M 모델, 34GB 여유 VRAM
이론적 수치보다 더 중요한 건 "내가 가진 GPU로 뭘 할 수 있는가"입니다. 70B 모델을 Q4_K_M으로 로드한 후 34GB의 여유 VRAM이 있다고 가정해봅시다.
| KV Cache | 가능한 컨텍스트 |
|---|---|
| FP16 | ~109K tokens |
| Q8_0 | ~218K tokens |
| TQ3 | ~536K tokens |
FP16에서 109K가 한계인 상황에서, TurboQuant를 적용하면 536K tokens — 거의 5배 — 까지 컨텍스트를 확장할 수 있습니다. Q8_0 대비로도 2.5배입니다.
이것은 단순히 "좀 더 긴 문서를 넣을 수 있다"가 아닙니다.
- RAG에서 더 많은 청크를 컨텍스트에 포함 → 답변 품질 향상
- 코드 에이전트가 더 많은 파일을 동시 참조 → 프로젝트 전체를 이해
- 배치 크기 증가 → 동시 사용자 수 확대 → 서빙 비용 절감
수학적 직관: 왜 직교 회전이 핵심인가
TurboQuant의 핵심 기여를 한 문장으로 요약하면 이렇습니다:
"양자화를 잘하려면, 양자화 대상의 분포를 먼저 정리하라."
이것을 비유로 설명해봅시다.
비유: 박스 포장
100개의 물건을 상자에 넣어야 합니다.
방법 A (기존 양자화): 물건들의 크기가 제각각입니다. 어떤 건 아주 크고(아웃라이어), 어떤 건 아주 작습니다. 큰 상자와 작은 상자를 섞어 써야 하고, 큰 물건 때문에 상자가 비효율적으로 사용됩니다.
방법 B (TurboQuant): 물건들을 섞고 재분배해서 크기를 비슷하게 만듭니다. 이제 같은 크기의 상자를 효율적으로 사용할 수 있습니다. 전체 부피(정보)는 보존되면서, 포장(양자화) 효율이 극적으로 올라갑니다.
직교 회전이 바로 이 "재분배"입니다. 벡터의 노름을 보존하면서(정보 손실 없이), 에너지를 균등하게 펼칩니다. 아웃라이어가 사라지고, 모든 좌표가 비슷한 스케일을 갖게 됩니다.
왜 캘리브레이션이 불필요한가
GPTQ나 AWQ 같은 가중치 양자화는 캘리브레이션 데이터가 필요합니다. 실제 입력을 넣어보고, 어떤 채널이 중요한지, 어떤 값이 아웃라이어인지 파악한 후 양자화 전략을 결정합니다.
TurboQuant에서 이 과정이 필요 없는 이유는 직교 회전 후의 분포가 데이터에 무관하기 때문입니다.
증명의 핵심: 임의의 벡터 v가 구면(sphere) 위에 균일하게 분포한다면, 직교 변환 R을 적용한 Rv도 구면 위에 균일하게 분포합니다. 단위 벡터의 각 좌표는 차원 d에 따라 결정되는 Beta 분포를 따르며, d가 크면 가우시안에 수렴합니다.
따라서 Lloyd-Max 양자화 버킷은 차원 d와 비트 수 b만 알면 사전 계산이 가능합니다. 모델이 바뀌어도, 입력이 바뀌어도 같은 버킷을 씁니다. 이것이 "제로샷" 양자화의 수학적 근거입니다.
왜 기존 방법들은 아웃라이어에 취약한가
TurboQuant를 제대로 이해하려면, 기존 KV Cache 양자화가 왜 어려운지를 알아야 합니다.
아웃라이어 문제
LLM의 KV Cache 벡터에는 일부 채널에 극단적으로 큰 값이 출현합니다. 나머지 채널의 값이 [-1, 1] 범위인데, 특정 채널만 [-50, 50]인 경우가 흔합니다.
균일 양자화(uniform quantization)를 적용하면, 이 아웃라이어 때문에 양자화 범위가 극단적으로 넓어집니다. 대부분의 값이 몰려 있는 좁은 범위에서의 해상도가 극히 떨어집니다. 마치 [-50, 50]을 16개 구간으로 나누면, [-1, 1] 범위의 미세한 차이를 전혀 구분하지 못하는 것과 같습니다.
KIVI와 KVQuant의 대응
KIVI는 아웃라이어 채널을 식별해서 별도의 높은 정밀도로 저장합니다. 하지만 어떤 채널이 아웃라이어인지는 모델과 레이어에 따라 다릅니다. 이를 파악하려면 실제 데이터를 통과시켜봐야 합니다.
KVQuant는 더 정교한 비균일 양자화와 채널별 스케일링을 사용합니다. 하지만 최적 파라미터를 찾기 위한 캘리브레이션 과정이 복잡하고 시간이 걸립니다.
TurboQuant의 해결
TurboQuant는 이 문제를 근본적으로 제거합니다. 직교 회전 후에는 아웃라이어가 존재하지 않습니다. 에너지가 균등 분배되었기 때문입니다. 따라서 아웃라이어 탐지도, 채널별 처리도, 캘리브레이션도 필요 없습니다.
HuggingFace에서 사용하기
TurboQuant의 HuggingFace 통합은 기존 transformers 파이프라인에 최소한의 변경으로 적용할 수 있도록 설계되었습니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
from turboquant import TurboQuantCache
# 모델 로드 (가중치 양자화는 별도)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct",
torch_dtype=torch.float16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B-Instruct")
# TurboQuant KV Cache 생성 (4비트)
cache = TurboQuantCache(bits=4)
# 추론 — 기존 코드에서 past_key_values만 교체
inputs = tokenizer("Explain quantum computing", return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
past_key_values=cache,
use_cache=True,
max_new_tokens=512
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))핵심은 TurboQuantCache 객체 하나입니다. past_key_values에 넣어주기만 하면, 내부적으로:
- 새 KV 벡터가 생성될 때마다 Walsh-Hadamard 회전 적용
- 극좌표 변환 후 Lloyd-Max 양자화
- 어텐션 계산 시 자동 역양자화
개발자가 양자화의 세부사항을 알 필요가 없습니다.
비트 수 선택
# 4비트: 안전한 선택. PPL 차이 ~0.5%
cache_4bit = TurboQuantCache(bits=4)
# 3비트: 극한 압축. PPL 차이 ~1.3%
cache_3bit = TurboQuantCache(bits=3)대부분의 경우 4비트를 추천합니다. 3비트는 메모리가 극도로 제한된 환경에서만 사용하되, 벤치마크에서 보았듯 품질 저하는 놀라울 만큼 적습니다.
llama.cpp에서의 구현 상태
HuggingFace보다 더 활발한 것은 llama.cpp 커뮤니티의 구현입니다. 이미 turbo3(tq3_0)과 turbo4(tq4_0) 타입으로 통합되어 있습니다.
llama.cpp 사용법
# 서버 실행 시 KV Cache 타입 지정
./llama-server \
-m models/qwen3.5-35b-a3b-q4_k_m.gguf \
--cache-type-k tq3_0 \
--cache-type-v tq3_0 \
-c 32768또는 Ollama에서 Modelfile로 지정할 수 있습니다:
FROM qwen3.5:35b-a3b-q4_k_m
PARAMETER num_ctx 32768
PARAMETER cache_type_k tq3_0
PARAMETER cache_type_v tq3_0가중치 양자화 + KV Cache 양자화 = 극한 효율
TurboQuant의 가장 강력한 특성은 가중치 양자화와 독립적으로 작동한다는 것입니다. 이 두 기법을 조합하면 메모리 효율이 극적으로 올라갑니다.
조합 예시: 70B 모델, A100 80GB
| 구성 | 모델 가중치 | KV Cache (32K) | 합계 | 가능? |
|---|---|---|---|---|
| FP16 + FP16 | ~140 GB | ~40 GB | ~180 GB | 불가능 |
| Q4_K_M + FP16 | ~38 GB | ~40 GB | ~78 GB | 빠듯 |
| Q4_K_M + Q8_0 | ~38 GB | ~20 GB | ~58 GB | 가능 |
| Q4_K_M + TQ3 | ~38 GB | ~9 GB | ~47 GB | 여유 |
마지막 구성을 보세요. Q4_K_M + TQ3 조합으로 70B 모델을 A100 하나에 여유 있게 올리고, 남는 33GB로 배치 처리나 더 긴 컨텍스트에 활용할 수 있습니다.
같은 구성에서 컨텍스트를 128K로 늘린다면:
| 구성 | KV Cache (128K) | 합계 | 가능? |
|---|---|---|---|
| Q4_K_M + FP16 | ~160 GB | ~198 GB | 불가능 |
| Q4_K_M + Q8_0 | ~80 GB | ~118 GB | 불가능 |
| Q4_K_M + TQ3 | ~36 GB | ~74 GB | 가능 |
TQ3만이 70B 모델 + 128K 컨텍스트를 단일 A100에 올릴 수 있습니다. 이것이 TurboQuant가 단순한 "최적화"가 아니라, 이전에 불가능했던 것을 가능하게 만드는 기술인 이유입니다.
현재 상태와 생태계
논문과 학계
- ICLR 2026 정식 논문으로 발표 (Google Research)
- PolarQuant의 이론적 프레임워크가 핵심 기여로 인정
- KV Cache 양자화 분야의 새로운 기준선(baseline)으로 자리잡는 중
커뮤니티 구현
- llama.cpp: turbo3 (tq3_0), turbo4 (tq4_0) 타입으로 통합 완료. Metal(Apple Silicon), CUDA, CPU 모두 지원
- 커뮤니티 독립 검증: 다수의 개발자가 논문의 주장을 재현. QJL 불필요 결론도 독립적으로 확인
- Metal 최적화: Apple Silicon에서의 커널 최적화가 활발. M4/M5 시리즈에서 최고 효율
공식 통합 전망
- Google 공식 구현: Q2 2026 예상. TensorFlow/JAX 기반 레퍼런스 구현
- vLLM 통합: 피처 리퀘스트 진행 중. 서빙 프레임워크에서의 통합은 기업 환경 도입의 핵심
- Ollama 네이티브 지원: llama.cpp 기반이므로, llama.cpp 통합이 완료되면 Ollama에서도 자동으로 사용 가능
산업 영향
TurboQuant 같은 KV Cache 압축 기술은 단순한 소프트웨어 최적화가 아닙니다. 하드웨어 수요에도 영향을 미칩니다.
같은 워크로드를 처리하는 데 필요한 GPU 메모리가 줄어든다는 것은:
- 데이터센터당 필요한 GPU 수 감소
- 동일 GPU에서 더 많은 동시 사용자 처리
- HBM(고대역폭 메모리) 수요 성장률 둔화
실제로 TurboQuant 논문 발표 이후 메모리 반도체 관련주 — 삼성전자, SK하이닉스, 마이크론 — 가 일시적 하락을 경험했습니다. AI 하드웨어 수요에 대한 장밋빛 전망에 균열이 생긴 것입니다. 물론 장기적으로 AI 워크로드 자체가 폭발적으로 증가하고 있으므로, 이는 일시적 조정에 가까웠지만요.
한눈에 보는 TurboQuant
| 항목 | 내용 |
|---|---|
| 핵심 원리 | 직교 회전 → 분포 균일화 → Lloyd-Max 최적 양자화 |
| 압축률 | 3비트: ~4.6x / 4비트: ~3.5x |
| 품질 저하 | PPL 차이 0.9~1.3% (사실상 무시 가능) |
| 속도 | 압축 전보다 오히려 빠름 (memory bandwidth 절감) |
| 캘리브레이션 | 불필요 (제로샷) |
| 가중치 양자화 호환 | 완전 호환 (직교적) |
| 지원 프레임워크 | llama.cpp, HuggingFace transformers |
| 논문 | ICLR 2026 (Google Research) |
결론
TurboQuant는 KV Cache 양자화의 패러다임을 바꾼 기술입니다. 핵심 통찰은 우아합니다: 양자화 대상의 분포를 먼저 정리하면, 양자화가 쉬워진다. Walsh-Hadamard 회전이라는 단순한 선형대수 연산으로 아웃라이어를 제거하고, Lloyd-Max라는 50년 된 알고리즘으로 최적 양자화를 달성합니다.
실전 영향은 즉각적입니다:
- 메모리: 같은 GPU에서 4~5배 긴 컨텍스트 처리 가능
- 속도: 오히려 빨라짐 (memory bandwidth 절감)
- 품질: PPL 차이 1% 이내
- 적용성: 캘리브레이션 없이 어떤 모델에든 즉시 적용
그리고 가중치 양자화와 직교적이라는 점이 결정적입니다. GGUF Q4_K_M + TurboQuant TQ3 조합은 현재 시점에서 단일 GPU로 대규모 모델을 운용하는 가장 효율적인 방법입니다.
다음 글: llama.cpp / Ollama에서 TurboQuant 실전 적용하기 — 모델별 최적 설정, 벤치마크 재현, 그리고 vLLM 서빙에서의 활용법을 다룹니다.
참고 자료:
- TurboQuant: Accurate KV Cache Quantization via Rotations and Lloyd-Max (ICLR 2026)
- llama.cpp TurboQuant PR
- QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead
- KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
- KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
이메일로 받아보기
관련 포스트
LLM 추론 최적화 Part 4 — 프로덕션 서빙
vLLM과 TGI로 프로덕션 배포. Continuous Batching, Speculative Decoding, 메모리 버짓 설계, 처리량 벤치마크.
LLM 추론 최적�� Part 3 — Sparse Attention 실전
Sliding Window, Sink Attention, DeepSeek DSA, IndexCache, Nvidia DMS. 동적 토큰 선별부터 Needle-in-Haystack 평가까지.
LLM 추론 최적화 Part 2 — KV Cache 최적화
KV Cache 양자화(int8/int4), PCA 압축(KVTC), PagedAttention(vLLM). 실전 메모리 절감 코드와 시나리오별 설정 가이드.