KV Cache 완전 정복 — LLM이 메모리를 먹는 진짜 이유
KV Cache가 뭔지, 왜 이렇게 메모리를 먹는지, 모델별 실제 메모리 계산법까지. GQA/MQA 차이, VRAM 버짓 계산기 포함.
KV Cache 완전 정복 — LLM이 메모리를 먹는 진짜 이유
LLM을 로컬에서 돌려본 분이라면 한 번쯤 경험했을 겁니다 — 프롬프트가 길어질수록 VRAM이 폭발적으로 늘어나고, 어느 순간 OOM(Out of Memory)으로 멈춰버리는 현상. 이 메모리 병목의 핵심에 KV Cache가 있습니다.
이 글에서는 KV Cache가 무엇인지, 왜 메모리를 이렇게 먹는지, 그리고 모델별로 실제 메모리를 계산하는 방법까지 코드와 함께 다룹니다.
Attention 동작 원리 — 30초 리캡
Transformer의 핵심은 Self-Attention입니다. 입력 토큰들이 서로의 관계를 계산하는 메커니즘인데, 핵심 연산은 다음과 같습니다:
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V각 토큰은 세 가지 벡터로 변환됩니다:
- Query (Q): "나는 어떤 정보가 필요한가?"
- Key (K): "나는 어떤 정보를 가지고 있는가?"
- Value (V): "실제로 전달할 정보"
Q와 K의 내적(dot product)으로 "어떤 토큰에 집중할지" 결정하고, 그 가중치로 V를 합산합니다.
문제는 모든 토큰이 이전의 모든 토큰과 관계를 계산해야 한다는 점입니다. 시퀀스 길이가 $n$이면 연산량은 $O(n^2)$으로 증가합니다.
KV Cache가 필요한 이유
LLM은 토큰을 하나씩 순서대로 생성합니다. "서울의 수도는"이라는 프롬프트에서 다음 토큰을 생성할 때, 이전 토큰들의 Key와 Value를 다시 계산해야 합니다.
KV Cache가 없다면:
- 첫 번째 토큰 생성: 프롬프트 전체의 K, V 계산
- 두 번째 토큰 생성: 프롬프트 + 첫 번째 토큰의 K, V 다시 전부 계산
- 세 번째 토큰: 또 전부 다시 계산...
매번 처음부터 다시 계산하는 건 엄청난 낭비입니다. 그래서 이미 계산한 K, V를 메모리에 저장해두는 것이 KV Cache입니다.
[KV Cache 없이]
토큰 1 생성: K,V 계산 → 4개 토큰
토큰 2 생성: K,V 계산 → 5개 토큰 (전부 재계산)
토큰 3 생성: K,V 계산 → 6개 토큰 (전부 재계산)
→ 총 연산: 4 + 5 + 6 = 15
[KV Cache 사용]
토큰 1 생성: K,V 계산 → 4개 토큰 (캐시에 저장)
토큰 2 생성: 새 토큰 1개만 K,V 계산 + 캐시 재사용
토큰 3 생성: 새 토큰 1개만 K,V 계산 + 캐시 재사용
→ 총 연산: 4 + 1 + 1 = 6연산량은 크게 줄어들지만, 캐시가 차지하는 메모리는 시퀀스 길이에 비례해서 증가합니다.
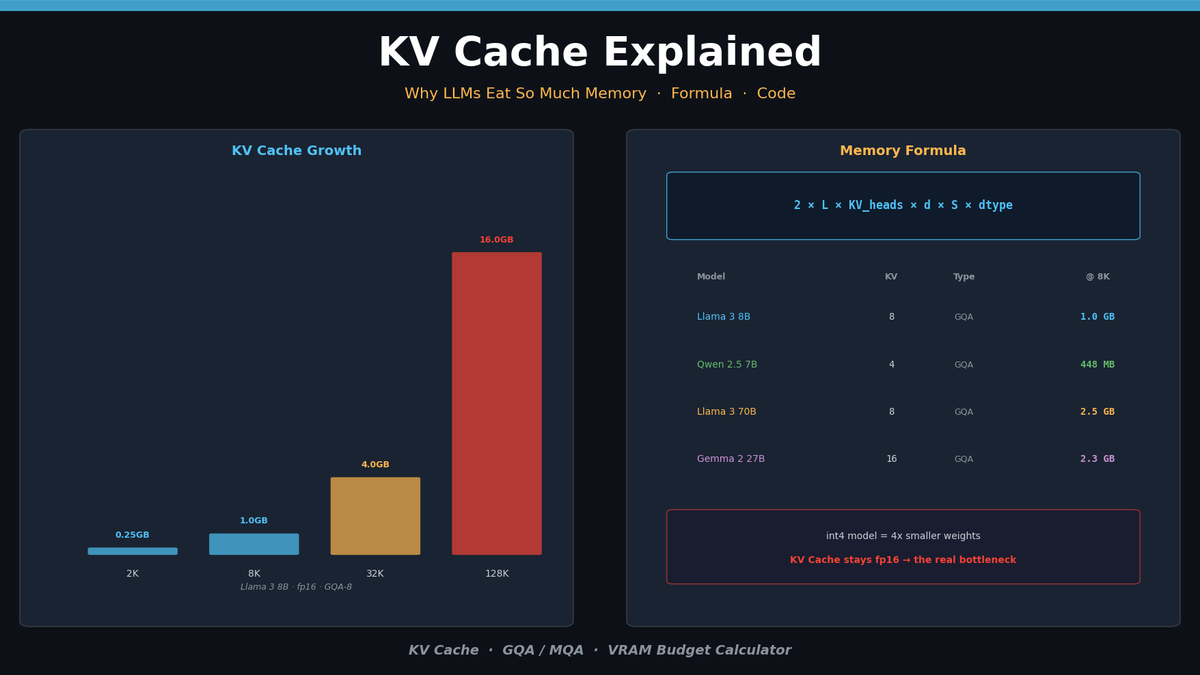
KV Cache 메모리 계산 공식
KV Cache의 메모리 사용량은 다음 공식으로 정확히 계산할 수 있습니다:
\text{KV Cache} = 2 \times L \times n_{kv} \times d_{head} \times S \times b| 변수 | 의미 | 예시 |
|---|---|---|
| $2$ | Key와 Value 두 가지 | 고정 |
| $L$ | Transformer 레이어 수 | 32 (Llama 3 8B) |
| $n_{kv}$ | KV Head 수 | 8 (GQA), 32 (MHA) |
| $d_{head}$ | Head 차원 | 128 |
| $S$ | 시퀀스 길이 | 8,192 |
| $b$ | 바이트/원소 | 2 (fp16), 1 (int8) |
핵심은 $n_{kv}$입니다. 전통적인 Multi-Head Attention(MHA)에서는 Query Head 수와 KV Head 수가 동일하지만, 최근 모델들은 GQA (Grouped-Query Attention) 를 사용해서 KV Head 수를 대폭 줄입니다.
모델별 KV Cache 크기 비교
실제 모델들의 KV Cache 메모리를 계산해보겠습니다. 시퀀스 길이 8K, fp16 기준입니다.
| 모델 | 레이어 | KV Heads | Head Dim | Attention | 토큰당 | 8K 시 | 128K 시 |
|---|---|---|---|---|---|---|---|
| Llama 3 8B | 32 | 8 | 128 | GQA | 128 KB | 1.0 GB | 16 GB |
| Llama 3 70B | 80 | 8 | 128 | GQA | 320 KB | 2.5 GB | 40 GB |
| Qwen 2.5 7B | 28 | 4 | 128 | GQA | 56 KB | 448 MB | 7 GB |
| Mistral 7B | 32 | 8 | 128 | GQA | 128 KB | 1.0 GB | 16 GB |
| Gemma 2 27B | 46 | 16 | 128 | GQA | 288 KB | 2.3 GB | 36 GB |
같은 파라미터 규모라도 GQA의 KV Head 수에 따라 캐시 크기가 완전히 달라집니다. Qwen 2.5 7B는 KV Head가 4개뿐이라 Llama 3 8B의 절반도 안 되는 메모리를 사용합니다.
128K 컨텍스트에서 Llama 3 70B의 KV Cache만 40GB — 모델 가중치(fp16 기준 140GB)와 별도로 이 메모리가 추가로 필요합니다.
Python 코드로 직접 확인
직접 모델을 로드해서 KV Cache를 확인해보겠습니다.
KV Cache Shape 확인
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "Qwen/Qwen2.5-7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
# 프롬프트 토큰화
prompt = "Explain the KV cache in transformers."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# use_cache=True로 KV Cache 반환
with torch.no_grad():
outputs = model(**inputs, use_cache=True)
# KV Cache 구조 확인
past_kv = outputs.past_key_values
print(f"레이어 수: {len(past_kv)}")
print(f"Key shape: {past_kv[0][0].shape}") # (batch, kv_heads, seq_len, head_dim)
print(f"Value shape: {past_kv[0][1].shape}")
# 전체 KV Cache 메모리 계산
total_bytes = sum(
k.element_size() * k.nelement() + v.element_size() * v.nelement()
for k, v in past_kv
)
print(f"KV Cache 메모리: {total_bytes / 1024**2:.1f} MB")출력 예시 (Qwen 2.5 7B, 프롬프트 8 토큰):
레이어 수: 28
Key shape: torch.Size([1, 4, 8, 128])
Value shape: torch.Size([1, 4, 8, 128])
KV Cache 메모리: 0.4 MB컨텍스트 길이별 메모리 프로파일링
import torch
import matplotlib.pyplot as plt
def measure_kv_cache_memory(model, tokenizer, seq_lengths):
"""시퀀스 길이별 KV Cache 메모리 측정"""
results = []
for length in seq_lengths:
# 원하는 길이의 입력 생성
input_ids = torch.randint(
100, 30000, (1, length), device=model.device
)
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
mem_before = torch.cuda.memory_allocated()
with torch.no_grad():
outputs = model(input_ids, use_cache=True)
# KV Cache 메모리만 측정
past_kv = outputs.past_key_values
kv_bytes = sum(
k.element_size() * k.nelement() + v.element_size() * v.nelement()
for k, v in past_kv
)
results.append({
'seq_len': length,
'kv_cache_mb': kv_bytes / 1024**2,
'total_gpu_mb': torch.cuda.max_memory_allocated() / 1024**2,
})
# 메모리 정리
del outputs, past_kv
torch.cuda.empty_cache()
return results
# 측정
seq_lengths = [512, 1024, 2048, 4096, 8192, 16384]
results = measure_kv_cache_memory(model, tokenizer, seq_lengths)
# 시각화
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
lengths = [r['seq_len'] for r in results]
kv_sizes = [r['kv_cache_mb'] for r in results]
total_sizes = [r['total_gpu_mb'] for r in results]
ax1.plot(lengths, kv_sizes, 'o-', color='#4FC3F7', linewidth=2, markersize=8)
ax1.set_xlabel('Sequence Length')
ax1.set_ylabel('KV Cache (MB)')
ax1.set_title('KV Cache Memory vs Sequence Length')
ax1.grid(True, alpha=0.3)
# KV Cache가 전체 GPU 메모리에서 차지하는 비율
kv_ratio = [kv / total * 100 for kv, total in zip(kv_sizes, total_sizes)]
ax2.bar(range(len(lengths)), kv_ratio, color='#FFB74D', alpha=0.8)
ax2.set_xticks(range(len(lengths)))
ax2.set_xticklabels([f'{l//1024}K' for l in lengths])
ax2.set_ylabel('KV Cache / Total GPU Memory (%)')
ax2.set_title('KV Cache Ratio in Total GPU Usage')
ax2.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig('kv_cache_profile.png', dpi=150, bbox_inches='tight')
plt.show()이 코드를 실행하면 KV Cache 메모리가 시퀀스 길이에 정확히 비례해서 증가하는 직선 그래프를 확인할 수 있습니다. 그리고 컨텍스트가 길어질수록 KV Cache가 전체 GPU 메모리에서 차지하는 비율이 점점 커지는 것도 볼 수 있습니다.
GQA / MQA — KV Cache를 줄이는 핵심 기술
KV Cache 크기를 결정하는 가장 큰 변수는 KV Head 수입니다. Attention의 종류에 따라 이 수가 크게 달라집니다.
Multi-Head Attention (MHA)
원래의 Transformer 구조입니다. Query, Key, Value 모두 동일한 수의 Head를 가집니다.
Q Heads: [H0] [H1] [H2] [H3] [H4] [H5] [H6] [H7]
K Heads: [H0] [H1] [H2] [H3] [H4] [H5] [H6] [H7]
V Heads: [H0] [H1] [H2] [H3] [H4] [H5] [H6] [H7]
→ KV Cache: 8 × head_dim × 2 per token per layerGrouped-Query Attention (GQA)
여러 Query Head가 하나의 KV Head를 공유합니다. Llama 3, Qwen 2.5 등 대부분의 최신 모델이 사용합니다.
Q Heads: [H0] [H1] [H2] [H3] [H4] [H5] [H6] [H7]
K Heads: [K0 ] [K1 ] [K2 ] [K3 ]
V Heads: [V0 ] [V1 ] [V2 ] [V3 ]
→ KV Cache: 4 × head_dim × 2 per token per layer (절반!)Multi-Query Attention (MQA)
모든 Query Head가 단 하나의 KV Head를 공유합니다. 가장 공격적인 압축이지만, 품질 저하가 발생할 수 있습니다.
Q Heads: [H0] [H1] [H2] [H3] [H4] [H5] [H6] [H7]
K Heads: [K0 ]
V Heads: [V0 ]
→ KV Cache: 1 × head_dim × 2 per token per layer (1/8!)코드로 확인
from transformers import AutoConfig
models = [
"meta-llama/Llama-3.1-8B-Instruct",
"Qwen/Qwen2.5-7B-Instruct",
"mistralai/Mistral-7B-Instruct-v0.3",
"google/gemma-2-9b-it",
]
print(f"{'Model':<40} {'Layers':>7} {'Q Heads':>8} {'KV Heads':>9} {'Head Dim':>9} {'Type':>5}")
print("-" * 80)
for model_id in models:
config = AutoConfig.from_pretrained(model_id)
q_heads = config.num_attention_heads
kv_heads = getattr(config, 'num_key_value_heads', q_heads)
head_dim = config.hidden_size // q_heads
if kv_heads == q_heads:
attn_type = "MHA"
elif kv_heads == 1:
attn_type = "MQA"
else:
attn_type = "GQA"
print(f"{model_id:<40} {config.num_hidden_layers:>7} {q_heads:>8} {kv_heads:>9} {head_dim:>9} {attn_type:>5}")실전: VRAM 버짓 계산하기
실제 서비스에서 가장 중요한 질문은 "내 GPU에 이 모델이 돌아가는가?"입니다. VRAM 버짓을 정확히 계산하는 방법을 알아보겠습니다.
전체 VRAM = 모델 가중치 + KV Cache + 오버헤드
def calculate_vram_budget(
model_params_b: float, # 모델 파라미터 수 (billions)
num_layers: int,
kv_heads: int,
head_dim: int,
max_seq_len: int,
batch_size: int = 1,
model_dtype_bytes: int = 2, # fp16=2, int4=0.5
kv_dtype_bytes: int = 2, # fp16=2, int8=1
):
"""VRAM 사용량 계산 (GB)"""
# 1. 모델 가중치
model_memory_gb = model_params_b * 1e9 * model_dtype_bytes / 1024**3
# 2. KV Cache
kv_cache_bytes = (
2 # K + V
* num_layers
* kv_heads
* head_dim
* max_seq_len
* batch_size
* kv_dtype_bytes
)
kv_cache_gb = kv_cache_bytes / 1024**3
# 3. 오버헤드 (activation, CUDA context 등) — 약 10~20%
overhead_gb = (model_memory_gb + kv_cache_gb) * 0.15
total_gb = model_memory_gb + kv_cache_gb + overhead_gb
return {
'model_weights_gb': round(model_memory_gb, 1),
'kv_cache_gb': round(kv_cache_gb, 1),
'overhead_gb': round(overhead_gb, 1),
'total_gb': round(total_gb, 1),
}
# 예시: Llama 3 8B (fp16) + 8K 컨텍스트
result = calculate_vram_budget(
model_params_b=8,
num_layers=32,
kv_heads=8,
head_dim=128,
max_seq_len=8192,
)
print("Llama 3 8B @ 8K context (fp16):")
for k, v in result.items():
print(f" {k}: {v} GB")
# 예시: Llama 3 8B (int4 quantized) + 32K 컨텍스트
result_q = calculate_vram_budget(
model_params_b=8,
num_layers=32,
kv_heads=8,
head_dim=128,
max_seq_len=32768,
model_dtype_bytes=0.5, # int4
kv_dtype_bytes=2, # KV는 여전히 fp16
)
print("\nLlama 3 8B (int4) @ 32K context:")
for k, v in result_q.items():
print(f" {k}: {v} GB")출력 예시:
Llama 3 8B @ 8K context (fp16):
model_weights_gb: 14.9
kv_cache_gb: 1.0
overhead_gb: 2.4
total_gb: 18.3
Llama 3 8B (int4) @ 32K context:
model_weights_gb: 3.7
kv_cache_gb: 4.0
overhead_gb: 1.2
total_gb: 8.9여기서 흥미로운 점이 있습니다. 모델을 int4로 양자화하면 가중치는 4배 줄어들지만, KV Cache는 여전히 fp16입니다. 컨텍스트가 길어지면 KV Cache가 모델 가중치보다 더 많은 VRAM을 차지하게 됩니다.
이것이 바로 KV Cache 최적화가 중요한 이유입니다.
KV Cache 최적화 방향
KV Cache 메모리 문제를 해결하는 접근법은 크게 세 가지입니다:
1. KV Cache 양자화: fp16 → int8/int4로 캐시를 압축합니다. 메모리를 2~4배 줄일 수 있지만, 정밀도 손실이 발생합니다.
2. Sparse Attention: 모든 토큰 대신 중요한 토큰만 선택적으로 참조합니다. DeepSeek의 DSA, Nvidia의 DMS 등이 대표적입니다.
3. KV Cache 압축: PCA 같은 수학적 기법으로 캐시 데이터 자체를 압축합니다. Nvidia의 KVTC가 대표적이며, 20배까지 압축이 가능합니다.
LLM 추론 최적화 시리즈 — Attention부터 프로덕션 서빙까지
Part 1~4에서 Attention 해부, KV Cache 최적화, Sparse Attention, vLLM/TGI 프로덕션 배포를 코드와 함께 다룹니다.
정리
| 항목 | 핵심 |
|---|---|
| KV Cache란 | 이전 토큰의 Key/Value를 저장해 재계산을 방지하는 메모리 |
| 크기 결정 요인 | 레이어 수 × KV Head 수 × Head 차원 × 시퀀스 길이 |
| GQA의 역할 | KV Head를 줄여 캐시 메모리를 2~8배 절감 |
| 실전 주의점 | 양자화 모델도 KV Cache는 fp16 — 긴 컨텍스트에서 병목 |
KV Cache는 LLM 추론의 핵심 병목입니다. 모델 선택부터 서빙 아키텍처 설계까지, 이 메모리를 얼마나 효율적으로 관리하느냐가 성능과 비용을 결정합니다.
관련 포스트

Reversal Curse를 깨는 Identity Bridge — ICML 2026, 이래도 되는데 되는 fix
언어 모델은 "Alice의 남편은 Bob"을 학습해도 "Bob의 아내는?"을 못 맞힙니다 — 유명한 reversal curse. ICML 2026 논문 하나가 학습 데이터에 이상한 자기참조 예제를 섞는 것만으로 이 문제를 해결합니다. 순진한 버전은 안 되고, 정교한 버전은 됩니다.

스스로 진화하는 AI 에이전트 — 2026년의 새로운 패러다임
GenericAgent, Evolver, Open Agents — 스스로 스킬을 만들고, 실행 경로를 기억하고, 실패에서 배우는 자가 진화 에이전트 3종 비교.

나만의 LLM Knowledge Base 구축하기 — Karpathy 스타일 지식 시스템
Obsidian + Claude Code로 영구적인 개인 지식 체계를 만드는 완전 가이드. 위키 + 메모리 두 축의 지식 시스템.