온디바이스 GPT-4o의 등장? MiniCPM-o 4.5 완벽 분석 및 활용 가이드
OpenBMB의 MiniCPM-o 4.5는 9B 파라미터로 GPT-4o급 비전 성능을 달성하고, Int4 양자화 시 11GB VRAM으로 구동됩니다. 아키텍처, 벤치마크 분석, 실전 활용 가이드까지 깊이 있게 다룹니다.

온디바이스 GPT-4o의 등장? MiniCPM-o 4.5 완벽 분석 및 활용 가이드
AI 모델을 사용할 때 우리는 항상 트레이드오프에 직면합니다. 성능을 원하면 거대한 GPU 클러스터가 필요하고, 온디바이스를 원하면 성능을 포기해야 합니다. 그런데 최근 이 공식을 깨는 모델이 등장했습니다.
OpenBMB가 공개한 MiniCPM-o 4.5는 9B 파라미터로 GPT-4o급 비전 성능을 달성하면서, Int4 양자화 시 단 11GB VRAM으로 구동됩니다. 텍스트, 이미지, 음성을 하나의 모델에서 처리하는 진정한 옴니(Omni) 모델입니다.
이 글에서는 단순한 소개를 넘어, MiniCPM-o의 아키텍처가 왜 효율적인지, 벤치마크 숫자가 실제로 의미하는 것이 무엇인지, 그리고 여러분의 프로젝트에서 어떻게 활용할 수 있는지까지 깊이 있게 다루겠습니다.
멀티모달 AI의 현재: 왜 옴니 모델인가?
잠깐 뒤로 물러나서 큰 그림을 봅시다.
2023년까지 AI 모델은 대부분 단일 모달리티 전문가였습니다. 텍스트는 GPT, 이미지는 CLIP, 음성은 Whisper. 이들을 조합해서 멀티모달 시스템을 만들었지만, 각 모듈 사이의 정보 손실이 불가피했습니다.
2024년 GPT-4o가 이 패러다임을 바꿨습니다. 텍스트, 이미지, 음성을 하나의 모델에서 end-to-end로 처리하니, 대화가 자연스러워지고 반응 속도가 극적으로 개선됐습니다.
문제는? GPT-4o는 클로즈드 소스이고, API 비용이 만만치 않습니다.
MiniCPM-o는 이 격차를 메웁니다. Apache 2.0 라이선스로 완전 공개되어, 누구나 자신의 하드웨어에서 파인튜닝하고 배포할 수 있습니다.
아키텍처: 작은 모델이 어떻게 큰 모델을 이기는가?
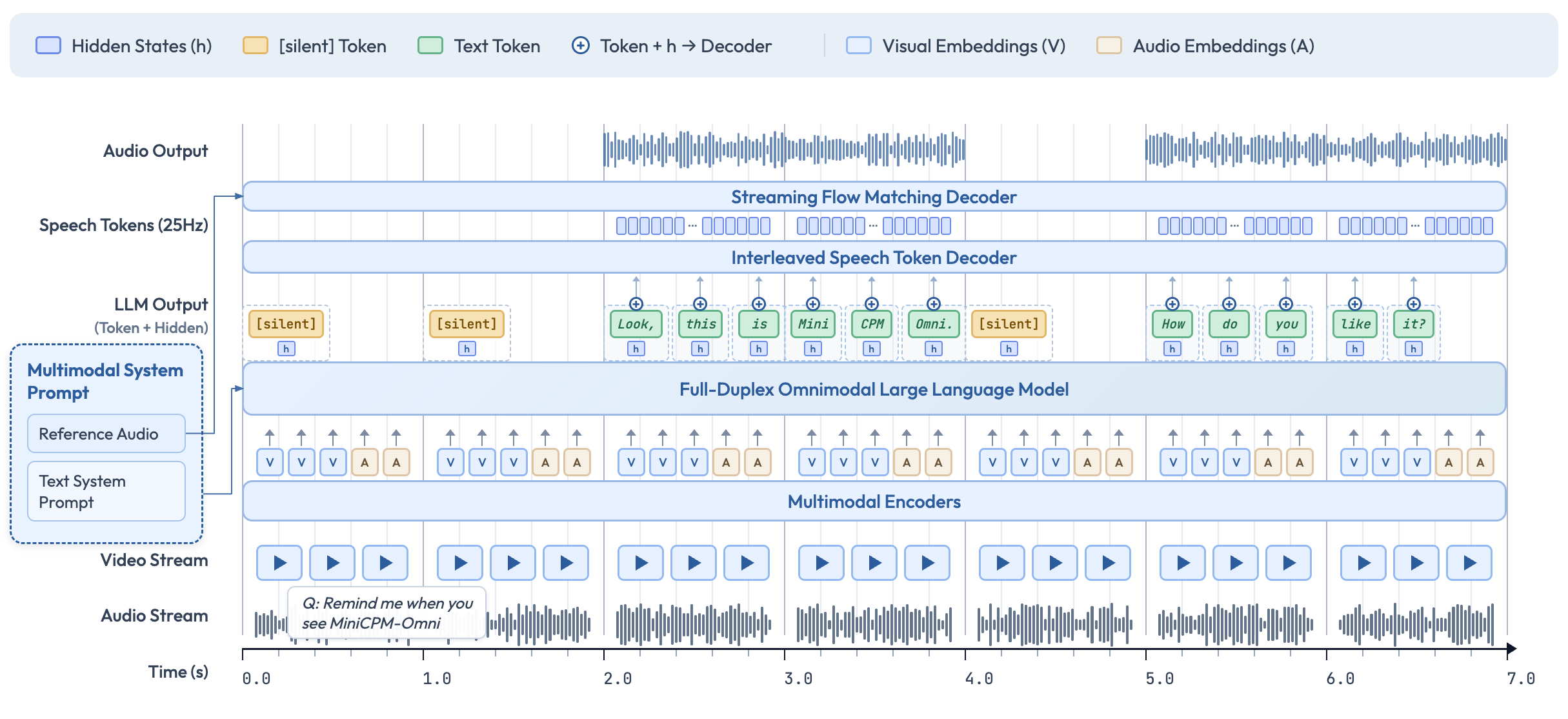
MiniCPM-o 4.5의 아키텍처를 이해하면, 왜 9B 파라미터로 이런 성능이 나오는지 납득이 됩니다.
핵심은 "각 모달리티에 최적의 전문가를 배치하고, 이를 하나의 언어 모델로 통합하는" 접근입니다.
| 역할 | 모델 | 왜 이 선택인가? |
|---|---|---|
| 비전 | SigLip2 | 최대 180만 픽셀 고해상도 처리. OCR에 강함 |
| 음성 인식 | Whisper-medium | 다국어 ASR의 de facto 표준 |
| 음성 합성 | CosyVoice2 | 보이스 클로닝, 감정 제어 지원 |
| 언어 | Qwen3-8B | 30개 이상 언어 지원, 강력한 추론력 |
여기서 주목할 점은 Qwen3-8B의 선택입니다. 8B급 언어 모델 중에서도 Qwen3는 reasoning 능력이 뛰어나고, instruct와 thinking 모드를 하나의 모델에서 지원합니다. MiniCPM-o는 이 두 모드를 모두 활용합니다.
벤치마크: 숫자 너머의 이야기
벤치마크 숫자만 나열하는 건 의미가 없습니다. 각 숫자가 실제로 무엇을 의미하는지 풀어보겠습니다.
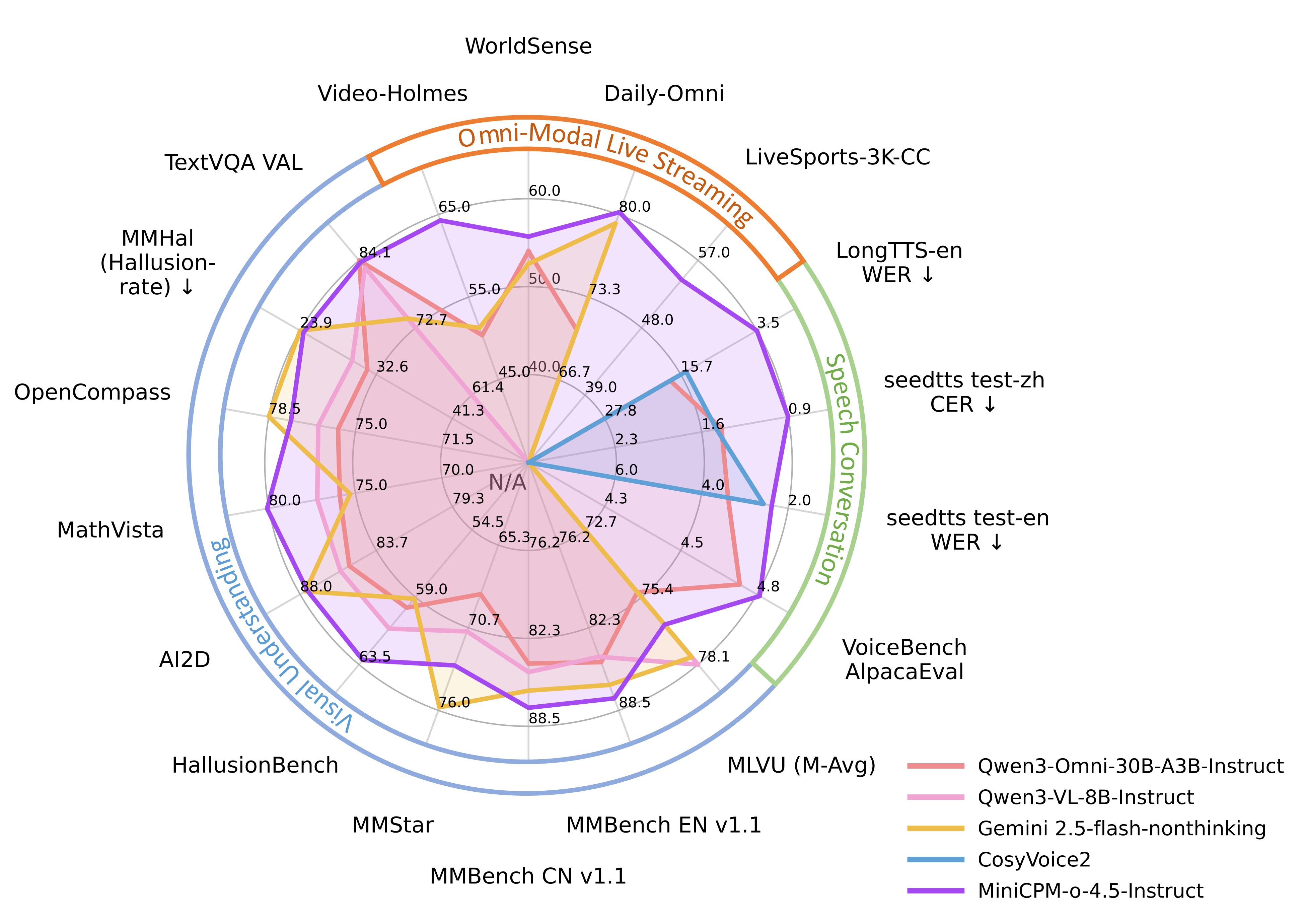
비전 이해력
| 벤치마크 | MiniCPM-o 4.5 | Gemini 2.5 Flash | 의미 |
|---|---|---|---|
| OpenCompass 평균 | 77.6 | 78.5 | 종합적인 시각 이해. 0.9점 차이는 사실상 동급 |
| MMBench EN | 87.6 | 85.8 | 일상적인 이미지 이해. MiniCPM-o가 앞섬 |
| MathVista | 80.1 | 75.3 | 수학적 시각 추론. 5점 차이는 유의미 |
| OCRBench | 876 | - | 문서 내 텍스트 인식 정확도 |
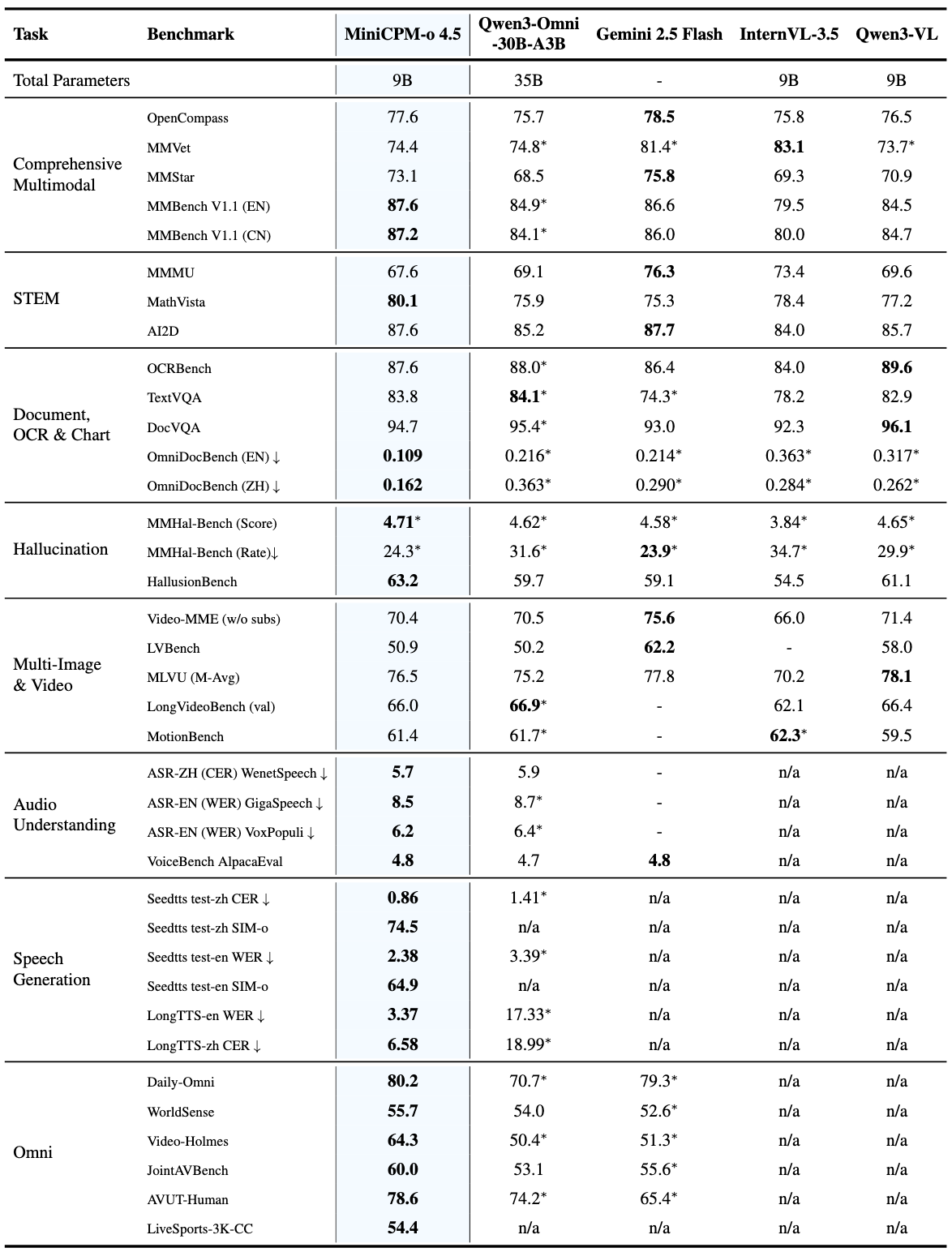
OpenCompass 77.6이 와닿지 않을 수 있습니다. 이렇게 생각해보세요: GPT-4o를 능가하고, 구글의 최신 모델과 1점 이내 차이입니다. 그런데 파라미터 수는 수십 분의 1입니다.
OCR: 여기가 진짜 충격적인 부분
OmniDocBench 문서 파싱 결과를 보세요 (edit distance, 낮을수록 좋음):
| 모델 | 점수 |
|---|---|
| MiniCPM-o 4.5 | 0.109 |
| DeepSeek-OCR 2 | 0.119 |
| Gemini-3 Flash | 0.155 |
| GPT-5 | 0.218 |
9B 모델이 GPT-5보다 문서를 2배 더 정확하게 파싱합니다. 이것은 아키텍처의 힘입니다. SigLip2의 고해상도 처리(최대 180만 픽셀)가 문서의 작은 글씨까지 놓치지 않습니다.
실무적으로 이것이 의미하는 바: 계약서, 영수증, 학술 논문 등을 로컬에서 처리할 수 있습니다. 민감한 문서를 외부 API로 보낼 필요가 없어집니다.
추론 속도: 온디바이스의 핵심
| 지표 | MiniCPM-o (BF16) | MiniCPM-o (Int4) | Qwen3-Omni-30B (Int4) |
|---|---|---|---|
| 디코딩 속도 | 154.3 tok/s | 212.3 tok/s | 147.8 tok/s |
| 첫 토큰까지 시간 | 0.6s | 0.6s | 1.0s |
| GPU 메모리 | 19.0 GB | 11.0 GB | 20.3 GB |
Int4로 양자화하면 212 tokens/s를 달성합니다. 3배 이상 큰 Qwen3-Omni-30B보다 빠릅니다. 11GB VRAM이면 RTX 3060이나 RTX 4060에서도 돌릴 수 있다는 뜻입니다.
TTFT(Time to First Token) 0.6초는 실시간 대화형 AI에 필수적입니다. 사용자가 "기다리고 있다"는 느낌을 받지 않는 임계점이 바로 1초 이내입니다.
음성: 단순 STT를 넘어서
MiniCPM-o의 음성 기능은 단순히 "음성을 텍스트로 바꾸는" 수준이 아닙니다:
- 실시간 양방향 음성 대화 (Full-Duplex)
- 보이스 클로닝: 참조 오디오로 특정 목소리 복제
- 감정 제어: 기쁨, 슬픔, 놀라움 등 톤 조절
- Long TTS: 영어 WER 3.37% (CosyVoice2의 14.80% 대비)
- 비디오 + 오디오 동시 스트리밍 입출력
Full-Duplex라는 것은, 모델이 말하는 중간에 사용자가 끼어들 수 있다는 의미입니다. 전화 통화처럼 자연스러운 대화가 가능해집니다.
실전 가이드: 30분 안에 돌려보기
1단계: 설치
# 기본 (비전 + 텍스트)
pip install "transformers==4.51.0" accelerate "torch>=2.3.0,<=2.8.0" "torchaudio<=2.8.0" "minicpmo-utils>=1.0.2"
# 음성까지 포함
pip install "transformers==4.51.0" accelerate "torch>=2.3.0,<=2.8.0" "torchaudio<=2.8.0" "minicpmo-utils[all]>=1.0.2"2단계: 이미지 이해 테스트
from transformers import AutoModel, AutoTokenizer
from PIL import Image
model = AutoModel.from_pretrained('openbmb/MiniCPM-o-4_5', trust_remote_code=True, torch_dtype='auto')
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-o-4_5', trust_remote_code=True)
image = Image.open('your_image.jpg').convert('RGB')
question = 'Describe this image in detail.'
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(msgs=msgs, tokenizer=tokenizer)
print(answer)3단계: 리소스 절약이 필요하다면
# Ollama로 간편하게 (CPU도 가능)
ollama run minicpm-o
# 또는 llama.cpp로 GGUF 양자화 버전
# iOS/iPad에서도 동작4단계: 프로덕션 배포
# vLLM으로 고처리량 서빙
python -m vllm.entrypoints.openai.api_server \
--model openbmb/MiniCPM-o-4_5 \
--trust-remote-codeMiniCPM-V Cookbook: 실무 활용의 보물창고
GitHub에 공개된 MiniCPM-V CookBook은 아이디어를 바로 구현으로 옮길 수 있게 해줍니다:
추론 레시피
- 멀티 이미지 비교 분석
- 비디오 이해 및 요약 (10fps까지 지원)
- PDF/웹페이지 문서 파싱
- 시각적 그라운딩 (이미지 내 특정 객체 위치 파악)
- 보이스 클로닝 및 TTS
파인튜닝
- LLaMA-Factory로 커스텀 데이터 학습
- SWIFT로 파라미터 효율적 튜닝
- LoRA/QLoRA 지원
배포
- vLLM/SGLang: GPU 서빙
- llama.cpp: PC, iPhone, iPad CPU 추론
- Gradio + WebRTC: 실시간 스트리밍 웹 데모
실제 활용 시나리오
MiniCPM-o가 특히 빛나는 영역들:
- 사내 문서 자동화: 계약서, 영수증, 보고서를 로컬에서 파싱. 민감 정보 외부 유출 없음
- 실시간 통역 디바이스: 11GB VRAM이면 충분. 엣지 디바이스에서 실시간 양방향 통역
- 시각 장애인 보조: 카메라 영상을 실시간 분석하고 음성으로 상황 설명
- 교육용 AI 튜터: 학생이 문제 사진을 보여주면 풀이 과정을 음성으로 설명
- 산업 현장 검수: 제품 사진을 찍으면 불량 여부를 즉시 판별
한계와 솔직한 평가
모든 모델에는 한계가 있습니다:
- 영어/중국어 음성에 최적화. 한국어 음성은 아직 제한적
- 복잡한 멀티턴 추론에서는 GPT-4o에 밀릴 수 있음
- Full-Duplex 스트리밍은 아직 실험적 단계
- 비전 성능이 Gemini 2.5 Flash에 근접하지만, 아직 완전히 넘지는 못함
하지만 이것이 오픈소스이고 9B라는 점을 기억하세요. 파인튜닝으로 특정 도메인에서는 훨씬 더 나은 성능을 끌어낼 수 있습니다.
마치며
MiniCPM-o 4.5는 "작은 모델은 성능이 낮다"는 통념을 깨부수는 모델입니다.
9B 파라미터, 11GB VRAM, Apache 2.0 라이선스. 이 세 가지 조합이 만드는 가능성은 무궁무진합니다. 여러분의 노트북에서, 스마트폰에서, 라즈베리 파이에서 GPT-4o급 멀티모달 AI를 돌릴 수 있는 시대가 왔습니다.
지금 바로 시작해보세요.
관련 링크
- HuggingFace: openbmb/MiniCPM-o-4_5
- GitHub: OpenBMB/MiniCPM-o
- Cookbook: MiniCPM-V CookBook
- 라이선스: Apache 2.0
이메일로 받아보기
관련 포스트

Google COSMO 해부 — 온디바이스 AI 에이전트의 새 아키텍처
Google이 실수로 공개한 차세대 AI 어시스턴트 COSMO. Gemini Nano + PI 서버 + 하이브리드 모드의 3-모드 아키텍처를 완전히 분석합니다. Google I/O 2026 직전 유출.
Gemma 4 MoE 파인튜닝 — 3.8B 활성 파라미터로 Arena #6 성능 커스터마이징
Gemma 4 26B MoE 모델에 QLoRA 적용. Expert 레이어 LoRA 전략, Dense 대비 비교, MoE 전용 학습 팁, Ollama 배포까지. LoRA 시리즈 Part 4.

Gemma 4 — 구글이 Apache 2.0으로 풀어놓은 오픈 모델의 새 기준
Gemma 시리즈 최초 Apache 2.0 라이선스. Chatbot Arena 전체 3위. 31B Dense, 26B MoE(3.8B 활성), E4B/E2B 에지 모델까지. AIME 89.2%, Codeforces ELO 2150, 256K 컨텍스트, 멀티모달.